Общее представление об обработке
Собрав совокупность данных, исследователь приступает к их обработке, получая сведения более высокого уровня, называемые результатами. Он уподобляется портному, который снял мерку (данные) и теперь все зафиксированные размеры соотносит между собой, приводит в целостную систему в виде выкройки и в конечном итоге – в виде той или иной одежды. Параметры фигуры заказчика – это данные, а готовое платье – это результат. На этом этапе могут обнаружиться ошибки в замерах, неясности в согласовании отдельных деталей одежды, что требует новых сведений, и клиент приглашается на примерку, где вносятся необходимые коррективы. Так и в научном исследовании: полученные на предыдущем этапе «сырые» данные путем их обработки приводят в определенную сбалансированную систему, которая становится базой для дальнейшего содержательного анализа, интерпретации и научных выводов и практических рекомендаций. Если по обработке данных выявляются какие-либо ошибки, пробелы, несоответствия, препятствующие построению такой системы, то их можно ликвидировать и восполнить, проведя повторные замеры.
Обработка данных направлена на решение следующих задач: 1) упорядочивание исходного материала, преобразование множества данных в целостную систему сведений, на основе которой возможно дальнейшее описание и объяснение изучаемых объекта и предмета; 2) обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях; 3) выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей; 4) обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса; 5) выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов.
Если на предыдущих этапах происходит процесс увеличения разнообразия сведений (числа параметров, единичных измерений, источников и т. п.), то теперь наблюдается обратный процесс – ограничение разнообразия, приведение данных к общим знаменателям, позволяющим делать обобщения и прогнозировать развитие тех или иных психических явлений.
Рассматриваемый этап обычно связывается с обработкой количественного характера. Качественная сторона обработки эмпирического материала, как правило, только подразумевается либо вовсе опускается. Обусловлено это, видимо, тем, что качественный анализ часто ассоциируется стеоретическим уровнем исследования, который присущ последующим стадиям изучения объекта – обсуждению и интерпретации результатов. Представляется, однако, что исследование качественного характера имеет два уровня: уровень обработки данных, где проводится организационно-подготовительная работа по первичному выявлению и упорядочиванию качественных характеристик изучаемого объекта, и уровень теоретического проникновения в сущность этого объекта. Работа первого типа характерна для стадии обработки данных, а второго – для этапа интерпретации результатов. Результат в данном случае понимается как итог и количественного, и качественного преобразования первичных данных. Тогда количественная обработкаесть манипуляция с измеренными характеристиками изучаемого объекта (объектов), с его «объективизированными» во внешнем проявлении свойствами. Качественная обработка – это способ предварительного проникновения в сущность объекта путем выявления его неизмеряемых свойств на базе количественных данных.
Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно, на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала, включающих в себя категорию «анализ» корреляционный анализ, факторный анализ и т. д. Основным гом количественной обработки является упорядоченная совокупность «внешних» показателей объекта (объектов). Реализуется количественная обработка с помощью математико-статистических методов.
В качественной обработке доминирует синтетическая составляющая познания, причем в этом синтезе превалирует компонент, объединения и в меньшей степени присутствует компонент обобщения. Обобщение – прерогатива последующего этапа исследовательского процесса – интерпретационного. В фазе качественной обработки данных главное заключается не в раскрытии сущности изучаемого явления, а пока лишь в соответствующем представлении сведений о нем, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики.
Противопоставление друг другу качественной и количествен ной обработок (а следовательно, и соответствующих методов) довольно условно. Они составляют органичное целое. Количественный анализ без последующей качественной обработки бессмыслен, так как сам по себе он не в состоянии превратить эмпирические данные в систему знаний. А качественное изучение: объекта без базовых количественных данных – немыслимо. В научном познании. Без количественных данных качественное познание – это чисто умозрительная процедура, не свойственная современной науке. В философии категории «качество» и «количество», как известно, объединяются в категории «мера».
Единство количественного и качественного осмысления эмпирического материала наглядно проступает во многих методах обработки данных: факторный и таксономический анализы, шкалирование, классификация и др. Но поскольку традиционно в науке принято деление на количественные и качественные характеристики, количественные и качественные методы, количественные и качественные описания, не будем «святее папы Римского» и примем количественные и качественные аспекты обработки данных за самостоятельные фазы одного исследовательского этапа, которым соответствуют определенные количественные и качественные методы.
Качественная обработка естественным образом выливается в описание и объяснение изучаемых явлений, что составляет уже следующий уровень их изучения, осуществляемый на стадии интерпретации результатов. Количественная же обработка полностью относится к рассматриваемому этапу исследовательского процесса, что в совокупности с ее особой спецификой побуждает к ее более подробному изложению. Процесс количественной обработки данных имеет две фазы: первичную и вторичную. Последовательно рассмотрим их.
Первичная обработка
На первой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы, а для наглядного представления данных строятся различные диаграммы и графики. Все эти манипуляции позволяют, во-первых, обнаружить и ликвидировать ошибки, совершенные при фиксации данных, и, во-вторых, выявить и изъять из общего массива нелепые данные, полученные в результате нарушения процедуры обследования, несоблюдения испытуемыми инструкции и т. п. Кроме того, первично обработанные данные, представая в удобной для обозрения форме, дают исследователю в первом приближении представление о характере всей совокупности данных в целом: об их однородности–неоднородности, компактности-разбросанности, четкости–размытости и т. д. Эта информация хорошо читается на наглядных формах представления данных и связана с понятием «распределение данных».
Под распределением данных понимается их разнесенность по категориям выраженности исследуемого качества (признака). Разнесенность по категориям показывает, как часто (или редко) в определенном массиве данных встречаются те или иные показатели изучаемого признака. Поэтому такой вид представления данных называют «распределением частот». Выраженность признака, как видели выше, может быть представлена в оценках: «есть – нет» или «равно – неравно» (номинативные данные), «больше – меньше» (порядковые данные), «настолько-то больше или меньше» (интервальные данные), «во столько-то раз больше или меньше» (пропорциональные данные). Первая категория оценок предполагает явную дискретность выраженности изучаемого признака, остальные – непрерывность (хотя бы теоретически). Проиллюстрируем это примерами.
Пример для дискретных данных
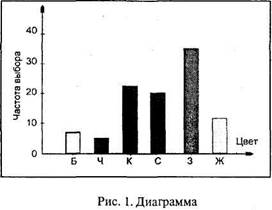
В трехтысячном трудовом коллективе были выбраны сто человек, которые давали ответ на вопрос: «какой цвет вы предпочитаете?». Предлагалось 6 вариантов: белый (Б), черный (Ч), красный (К), синий (С), зеленый (3), желтый (Ж). В данном случае каждый цвет – это самостоятельная категория выраженности признака «окраска». Допустим, цель – выбор дизайнером окраски рабочих помещений, где трудятся эти люди. Итоги опроса, зафиксированные в протоколе, подсчитали и занесли в таблицу 1 (табулировали).
Таблица 1
Итоги опроса
| Цвет | Количество выборов | ||
| Абсолютная частота | Относительная частота | % | |
| Б | 0,08 | ||
| Ч | 0,06 | ||
| К | 0,21 | ||
| С | 0,20 | ||
| З | 0,34 | ||
| Ж | 0,11 | ||
| Сумма | 1,00 |
Частота (абсолютная частота)– это число ответов данной категории в выборке, частость (относительная частота)– это отношение частоты ко всей выборке. Под выборкойпонимается все множество полученных в исследовании значений изучаемого признака (свойства, качества, состояния) объекта. В нашем примере выборка равна 100. Понятие выборки связано с понятием генеральной совокупности(или популяции),которая представляет собой все возможное множество значений изучаемого признака. В нашем примере она равна 3000. Поскольку даже ограниченные популяции обычно весьма велики, то опыты проводятся только на выборках. Поэтому встает вопрос о репрезентативностивыборки, т. е. о том, можно ли результаты, полученные на выборке, переносить на всю совокупность. Для этого привлекают статистические методы доказательства репрезентативности. Таким образом, выборка есть часть генеральной совокупности. Краткое описание этих множеств производится с помощью так называемых описательных мер (мер центральной тенденции, разброса исвязи), вычисление которых производится при вторичной обработке данных. Значения мер, вычисленные для генеральных совокупностей, называются параметрами,для выборок – статистиками.Параметр описывает генеральную совокупность также, как статистика – выборку. Принято обозначать статистики латинскими буквами, а параметры – греческими. Правда, в психологических исследованиях этих правил не всегда строго придерживаются.
На основании табличных данных можно построить диаграмму,где распределение представлено нагляднее:
Пример для непрерывных данных
Данные непрерывного характера можно представить веще более наглядной форме: в виде гистограмм, полигонов икривых.
В опытах В. К. Гайды, описанных в учебном пособии для студентов-психологов [76, с. 23-25], участвовало 96 испытуемых. Определялся цвет последовательного образа восприятия насыщенного красного цвета. С этой целью каждый испытуемый в течение одной минуты рассматривал окрашенный в красный цвет образец, а затем переносил взгляд на белый экран, где видел круг в дополнительных цветах. Рядом с ним находился цветовой круг с разноокрашенными секторами, на котором испытуемый должен был выбрать тот цвет, который соответствовал цвету возникшего у него последовательного образа. При этом испытуемый не называл цвет, а лишь его номер в цветовом круге. Цветовой круг нормирован таким образом, что соседние цвета отличаются в нем друг от друга на одинаково замечаемую величину. Следовательно, цветовой круг можно рассматривать как интервальную шкалу. Наряду с этим цветовой круг характеризуется и еще одним свойством. В частности, можно себе представить, что между двумя соседними цветами, например между зеленовато-голубым и голубовато-зеленым, имеется еще множество не замечаемых человеческим глазом цветовых переходов. В этом смысле цветовой круг представляет собой пример непрерывной переменной. Фактически же испытуемые всегда выделяют конечное число цветовых оттенков и поэтому свой выбор останавливают на конкретном номере (или названии) цвета. В рассматриваемом эксперименте испытуемые определяли свой последовательный образ в диапазоне от № 16 – зеленовато-голубой цвет до № 23 – желтовато-зеленый. Полученные данные можно табулировать, что и сделано в таблице 2.
Таблица 2
| Последовательный образ | Частота выбора цвета образа |
| Σ |
Как видно, в построении таблиц 1 и 2 нет принципиального различия. Но разница в характере первичных данных, отображенных в обеих таблицах, все же есть, и она обнаруживается при их графическом изображении. В самом деле, рис. 2 представляет собой уже не столбиковую, а ступенчатую диаграмму, называемую гистограммой.Следует обратить внимание на то, что все участки (столбики) ступенчатой диаграммы расположены вплотную друг к другу (числовые переменные на оси абсцисс гистограммы пишут против центральной оси каждого участка).
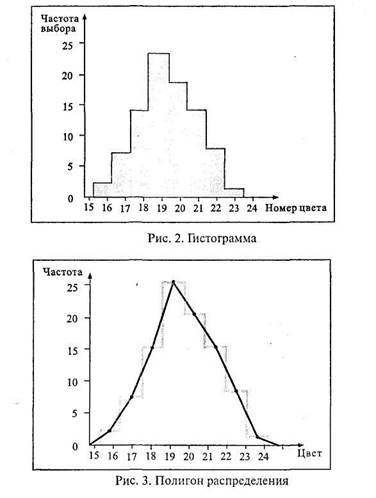
От гистограммы легко перейти к построению частотного полигона распределения,а от последнего – к кривой распределения. Частотный полигон строят, соединяя прямыми отрезками верхние точки центральных осей всех участков ступенчатой диаграммы (рис. 3). Если же вершины участков соединить с помощью плавных кривых линий, то получится кривая распределения первичных результатов (рис. 4).

Переход от гистограммы к кривой распределения позволяет путем интерполяции находить те величины исследуемой переменной, которые в опыте не были получены.
Вторичная обработка