First-Come, First-Served (FCFS)
Простейшим алгоритмом планирования является алгоритм, который принято обозначать аббревиатурой FCFS по первым буквам его английского названия — First Come, First Served (первым пришел, первым обслужен). Представим себе, что процессы, находящиеся в состоянии готовность, организованы в очередь. Когда процесс переходит в состояние готовность, он, а точнее ссылка на его PCB, помещается в конец этой очереди. Выбор нового процесса для исполнения осуществляется из начала очереди с удалением оттуда ссылки на его PCB. Очередь подобного типа имеет в программировании специальное наименование FIFO — сокращение от First In, First Out (первым вошел, первым вышел).
Аббревиатура FCFS используется для этого алгоритма планирования вместо стандартной аббревиатуры FIFO для механизмов подобного типа для того, чтобы подчеркнуть, что организация готовых процессов в очередь FIFO возможна и при других алгоритмах планирования (например, для Round Robin).
Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения своего текущего CPU burst. После этого для выполнения выбирается новый процесс из начала очереди.
| Процесс | p0 | p1 | p2 |
| Продолжительность очередного CPU burst |
Таблица 1.
Преимуществом алгоритма FCFS является легкость его реализации, в то же время он имеет и много недостатков. Рассмотрим следующий пример. Пусть в состоянии готовность находятся три процесса p0, p1 и p2, для которых известны времена их очередных CPU burst. Эти времена приведены в таблице 1 в некоторых условных единицах. Для простоты будем полагать, что вся деятельность процессов ограничивается использованием только одного промежутка CPU burst, что процессы не совершают операций ввода-вывода, и что время переключения контекста пренебрежимо мало.
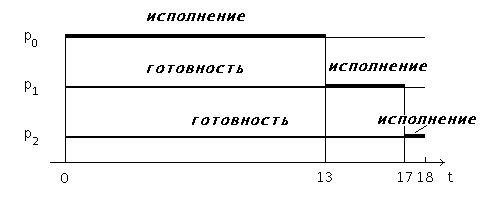
Рис 2. Выполнение процессов при порядке p0,p1,p2
Если процессы расположены в очереди процессов готовых к исполнению в порядке p0, p1, p2, то картина их выполнения выглядит так, как показано на рисунке 2. Первым для выполнения выбирается процесс p0, который получает процессор на все время своего CPU burst, т. е. на 13 единиц времени. После его окончания в состояние исполнение переводится процесс p1, занимая процессор на 4 единицы времени. И, наконец, возможность работать получает процесс p2. Время ожидания для процесса p0 составляет 0 единиц времени, для процесса p1 — 13 единиц, для процесса p2 — 13 + 4 = 17 единиц. Таким образом, среднее время ожидания в этом случае — (0 + 13 + 17)/3 = 10 единиц времени. Полное время выполнения для процесса p0 составляет 13 единиц времени, для процесса p1 — 13 + 4 = 17 единиц, для процесса p2 — 13 + 4 + 1 = 18 единиц. Среднее полное время выполнения оказывается равным (13 + 17 + 18)/3 = 16 единицам времени.
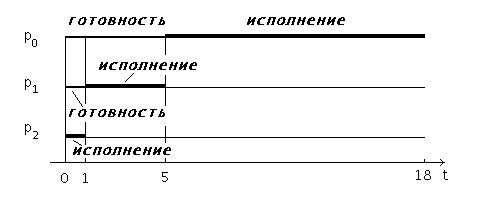
Рис 3. Выполнение процессов при порядке p2,p1,p0
Если те же самые процессы расположены в порядке p2, p1, p0, то картина их выполнения будет соответствовать рисунку 3. Время ожидания для процесса p0 равняется 5 единицам времени, для процесса p1 — 1 единице, для процесса p2 — 0 единиц. Среднее время ожидания составит (5 + 1 + 0)/3 = 2 единицы времени. Это в 5 (!) раз меньше, чем в предыдущем случае. Полное время выполнения для процесса p0 получается равным 18 единицам времени, для процесса p1 — 5 единицам, для процесса p2 — 1 единице. Среднее полное время выполнения составляет (18 + 5 + 1)/3 = 6 единиц времени, что почти в 2,7 раза меньше чем при первой расстановке процессов.
Среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от порядка расположения процессов в очереди. Если есть процесс с длительным CPU burst, то короткие процессы (перешедшие в состояние готовность после длительного процесса) будут очень долго ждать начала своего выполнения. Поэтому алгоритм FCFS практически неприменим для систем разделения времени. Слишком большим получается среднее время отклика в интерактивных процессах.
Round Robin (RR)
Модификацией алгоритма FCFS является алгоритм, получивший название Round Robin (Round Robin – это вид детской карусели в США) или сокращенно RR. По сути дела это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически — процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10 - 100 миллисекунд (см. рисунок 4). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.
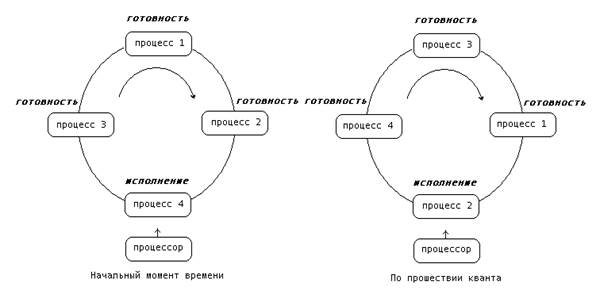
Рис 4. Процессы на карусели.
Реализуется такой алгоритм так же, как и предыдущий, с помощью организации процессов, находящихся в состоянии готовность, в очередь FIFO. Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди, и устанавливает таймер для генерации прерывания по истечении определенного кванта времени. При выполнении процесса возможны два варианта:
§ Время непрерывного использования процессора, требующееся процессу, (остаток текущего CPU burst) меньше или равно продолжительности кванта времени. Тогда процесс по своей воле освобождает процессор до истечения кванта времени, на исполнение выбирается новый процесс из начала очереди и таймер начинает отсчет кванта заново.
§ Продолжительность остатка текущего CPU burst процесса больше, чем квант времени. Тогда по истечении этого кванта процесс прерывается таймером и помещается в конец очереди процессов готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
Рассмотрим предыдущий пример с порядком процессов p0, p1, p2 и величиной кванта времени равной 4. Выполнение этих процессов иллюстрируется таблицей 2. Обозначение “И” используется в ней для процесса, находящегося в состоянии исполнение, обозначение “Г” — для процессов в состоянии готовность, пустые ячейки соответствуют завершившимся процессам. Состояния процессов показаны на протяжении соответствующей единицы времени, т. е. колонка с номером 1 соответствует промежутку времени от 0 до 1.
| время | ||||||||||||||||||
| p0 | И | И | И | И | Г | Г | Г | Г | Г | И | И | И | И | И | И | И | И | И |
| p1 | Г | Г | Г | Г | И | И | И | И | ||||||||||
| p2 | Г | Г | Г | Г | Г | Г | Г | Г | И |
Таблица 2.
Первым для исполнения выбирается процесс p0. Продолжительность его CPU burst больше, чем величина кванта времени, и поэтому процесс исполняется до истечения кванта, т. е. в течение 4 единиц времени. После этого он помещается в конец очереди готовых к исполнению процессов, которая принимает вид p1, p2, p0. Следующим начинает выполняться процесс p1. Время его исполнения совпадает с величиной выделенного кванта, поэтому процесс работает до своего завершения. Теперь очередь процессов в состоянии готовность состоит из двух процессов p2, p0. Процессор выделяется процессу p2. Он завершается до истечения отпущенного ему процессорного времени, и очередные кванты отмеряются процессу p0 — единственному, не закончившему к этому моменту свою работу. Время ожидания для процесса p0 (количество символов “Г” в соответствующей строке) составляет 5 единиц времени, для процесса p1 — 4 единицы времени, для процесса p2 — 8 единиц времени. Таким образом, среднее время ожидания для этого алгоритма получается равным (5 + 4 + 8)/3 = 5,6(6) единицы времени. Полное время выполнения для процесса p0 (количество непустых столбцов в соответствующей строке) составляет 18 единиц времени, для процесса p1 — 8 единиц, для процесса p2 — 9 единиц. Среднее полное время выполнения оказывается равным (18 + 8 + 9)/3 = 11,6(6) единицам времени.
Легко видеть, что среднее время ожидания и среднее полное время выполнения для обратного порядка процессов не отличаются от соответствующих времен для алгоритма FCFS и составляют 2 и 6 единиц времени соответственно.
На производительность алгоритма RR сильно влияет величина кванта времени. Рассмотрим тот же самый пример c порядком процессов p0, p1, p2 для величины кванта времени равной 1 (см. таблицу 3). Время ожидания для процесса p0 составит 5 единиц времени, для процесса p1 — тоже 5 единиц, для процесса p2 — 2 единицы. В этом случае среднее время ожидания получается равным (5 + 5 + 2)/3 = 4 единицам времени. Среднее полное время исполнения составит (18 + 9 + 3)/3 = 10 единиц времени.
| время | ||||||||||||||||||
| p0 | И | Г | Г | И | Г | И | Г | И | Г | И | И | И | И | И | И | И | И | И |
| p1 | Г | И | Г | Г | И | Г | И | Г | И | |||||||||
| p2 | Г | Г | И |
Таблица 3.
При очень больших величинах кванта времени, когда каждый процесс успевает завершить свой CPU burst до возникновения прерывания по времени, алгоритм RR вырождается в алгоритм FCFS. При очень малых величинах создается иллюзия того, что каждый из n процессов работает на своем собственном виртуальном процессоре с производительностью ~ 1/n от производительности реального процессора. Правда, это справедливо лишь при теоретическом анализе при условии пренебрежения временами переключения контекста процессов. В реальных условиях при слишком малой величине кванта времени и, соответственно, слишком частом переключении контекста, накладные расходы на переключение резко снижают производительность системы.
Shortest-Job-First (SJF)
При рассмотрении алгоритмов FCFS и RR мы видели, насколько существенным для них является порядок расположения процессов в очереди процессов готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает. Если бы мы знали время следующих CPU burst для процессов, находящихся в состоянии готовность, то могли бы выбрать для исполнения не процесс из начала очереди, а процесс с минимальной длительностью CPU burst. Если же таких процессов два или больше, то для выбора одного из них можно использовать уже известный нам алгоритм FCFS. Квантование времени при этом не применяется. Описанный алгоритм получил название “кратчайшая работа первой” или Shortest Job First (SJF). SJF алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF планировании процессор предоставляется избранному процессу на все требующееся ему время, независимо от событий происходящих в вычислительной системе. При вытесняющем SJF планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
Рассмотрим пример работы невытесняющего алгоритма SJF. Пусть в состоянии готовность находятся четыре процесса p0, p1, p2 и p3, для которых известны времена их очередных CPU burst. Эти времена приведены в таблице 4. Как и прежде, будем полагать, что вся деятельность процессов ограничивается использованием только одного промежутка CPU burst, что процессы не совершают операций ввода-вывода, и что время переключения контекста пренебрежимо мало.
| Процесс | p0 | p1 | p2 | p3 |
| Продолжительность очередного CPU burst |
Таблица 4.
При использовании невытесняющего алгоритма SJF первым для исполнения будет выбран процесс p3, имеющий наименьшее значение очередного CPU burst. После его завершения для исполнения выбирается процесс p1, затем p0 и, наконец, p2. Вся эта картина изображена в таблице 5.
| время | ||||||||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | |||||||
| p1 | Г | И | И | И | ||||||||||||
| p2 | Г | Г | Г | Г | Г | Г | Г | Г | Г | И | И | И | И | И | И | И |
| p3 | И |
Таблица 5.
Как видим, среднее время ожидания для алгоритма SJF составляет (4 + 1 + 9 + 0)/4 = 3,5 единицы времени. Легко посчитать, что для алгоритма FCFS при порядке процессов p0, p1, p2, p3 эта величина будет равняться (0 + 5 + 8 + 15)/4 = 7 единицам времени, т. е. будет в 2 раза больше, чем для алгоритма SJF. Можно показать, что для заданного набора процессов (если в очереди не появляются новые процессы) алгоритм SJF является оптимальным с точки зрения минимизации среднего времени ожидания среди класса всех невытесняющих алгоритмов.
Для рассмотрения примера вытесняющего SJF планирования мы возьмем ряд процессов p0, p1, p2 и p3с различными временами CPU burst и различными моментами их появления в очереди процессов готовых к исполнению (см. таблицу 6).
| Процесс | Время появления в очереди | Продолжительность очередного CPU burst |
| p0 | ||
| p1 | ||
| p2 | ||
| p3 |
Таблица 6.
В начальный момент времени в состоянии готовность находятся только два процесса p0 и p4. Меньшее время очередного CPU burst оказывается у процесса p3, поэтому он и выбирается для исполнения (см. таблицу 7). По прошествии 2-х единиц времени в систему поступает процесс p1. Время его CPU burst меньше, чем остаток CPU burst у процесса p3, который вытесняется из состояния исполнение и переводится в состояние готовность. По прошествии еще 2-х единиц времени процесс p1 завершается, и для исполнения вновь выбирается процесс p3. В момент времени t = 6 в очереди процессов готовых к исполнению появляется процесс p2, но поскольку ему для работы нужно 7 единиц времени, а процессу p3 осталось трудиться всего 2 единицы времени, то процесс p3 остается в состоянии исполнение. После его завершения в момент времени t = 7 в очереди находятся процессы p0 и p2, из которых выбирается процесс p0. Последним получит возможность выполняться процесс p2.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | И | И | И |
| p1 | И | И | ||||||||
| p2 | Г | Г | Г | Г | ||||||
| p3 | И | И | Г | Г | И | И | И |
| время | ||||||||||
| p0 | И | И | И | |||||||
| p1 | ||||||||||
| p2 | ||||||||||
| p3 | Г | Г | Г | И | И | И | И | И | И | И |
Таблица 7.
Основную сложность при реализации алгоритма SJF представляет невозможность точного знания времени очередного CPU burst для исполняющихся процессов. В пакетных системах количество процессорного времени, требующееся заданию для выполнения, указывает пользователь при формировании задания. Мы можем брать эту величину для осуществления долгосрочного SJF планирования. Если пользователь укажет больше времени, чем ему нужно, он будет ждать получения результата дольше, чем мог бы, так как задание будет загружено в систему позже. Если же он укажет меньшее количество времени, задача может не досчитаться до конца. Таким образом, в пакетных системах решение задачи оценки времени использования процессора перекладывается на плечи пользователя. При краткосрочном планировании мы можем делать только прогноз длительности следующего CPU burst, исходя из предыстории работы процесса. Пусть t(n) – величина n-го CPU burst, T(n + 1)– предсказываемое значение для n + 1-го CPU burst, a – некоторая величина в диапазоне от 0 до 1.
Определим рекуррентное соотношение

T(0) положим произвольной константой. Первое слагаемое учитывает последнее поведение процесса, тогда как второе слагаемое учитывает его предысторию. При a = 0 мы перестаем следить за последним поведением процесса, фактически полагая

т.е. оценивая все CPU burst одинаково, исходя из некоторого начального предположения.
Положив a = 1, мы забываем о предыстории процесса. В этом случае мы полагаем, что время очередного CPU burst будет совпадать со временем последнего CPU burst:

Обычно выбирают

для равноценного учета последнего поведения и предыстории. Надо отметить, что такой выбор a удобен и для быстрой организации вычисления оценки T(n + 1). Для подсчета новой оценки нужно взять старую оценку, сложить с измеренным временем CPU burst и полученную сумму разделить на 2, например, с помощью ее сдвига на 1 бит вправо. Полученные оценки T(n + 1) применяются как продолжительности очередных промежутков времени непрерывного использования процессора для краткосрочного SJF планирования.
Гарантированное планирование
При интерактивной работе N пользователей в вычислительной системе можно применить алгоритм планирования, который гарантирует, что каждый из пользователей будет иметь в своем распоряжении ~ 1/N часть процессорного времени. Пронумеруем всех пользователей от 1 до N. Для каждого пользователя с номером i введем две величины: Ti - время нахождения пользователя в системе, или, другими словами длительность сеанса его общения с машиной, и ti - суммарное процессорное время уже выделенное всем его процессам в течение сеанса. Справедливым для пользователя было бы получение Ti/N процессорного времени. Если

то i - й пользователь несправедливо обделен процессорным временем.
Если же

то система явно благоволит к пользователю с номером i. Вычислим для каждого пользовательского процесса значение коэффициента справедливости

и будем предоставлять очередной квант времени процессу с наименьшей величиной этого отношения. Предложенный алгоритм называют алгоритмом гарантированного планирования. К недостаткам этого алгоритма можно отнести невозможность предугадать поведение пользователей. Если некоторый пользователь отправится на пару часов пообедать и поспать, не прерывая сеанса работы, то по возвращении его процессы будут получать неоправданно много процессорного времени.
Приоритетное планирование
Алгоритмы SJF и гарантированного планирования представляют собой частные случаи приоритетного планирования. При приоритетном планировании каждому процессу присваивается определенное числовое значение — приоритет, в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FCFS. Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс. Для алгоритма гарантированного планирования приоритетом служит вычисленный коэффициент справедливости. Чем он меньше, тем больше приоритет у процесса.
Принципы назначения приоритетов могут опираться как на внутренние критерии вычислительной системы, так и на внешние по отношению к ней. Внутренние используют различные количественные и качественные характеристики процесса для вычисления его приоритета. Это могут быть определенные ограничения по времени использования процессора, требования к размеру памяти, число открытых файлов и используемых устройств ввода-вывода и т. д. Внешние критерии исходят из таких параметров, как важность процесса для достижения каких-либо целей, стоимость оплаченного процессорного времени и других политических факторов. Планирование с использованием приоритетов может быть как вытесняющим, так и невытесняющим. При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом. В случае невытесняющего планирования он просто становится в начало очереди готовых процессов. Давайте рассмотрим примеры использования различных режимов приоритетного планирования.
Пусть в очередь процессов, находящихся в состоянии готовность, поступают те же процессы, что и в предыдущем примере для вытесняющего алгоритма SJF, только им дополнительно еще присвоены приоритеты (см. таблицу 8). В вычислительных системах не существует определенного соглашения, какое значение приоритета - 1 или 4 считать более приоритетным. Во избежание путаницы, во всех наших примерах мы будем предполагать, что большее значение соответствует меньшему приоритету, т.е. наиболее приоритетным в нашем примере является процесс p3, а наименее приоритетным — процесс p0.
| Процесс | Время появления в очереди | Продолжительность очередного CPU burst | Приоритет |
| p0 | |||
| p1 | |||
| p2 | |||
| p3 |
Таблица 8.
Как будут вести себя процессы при использовании невытесняющего приоритетного планирования? Первым для выполнения в момент времени t = 0 выбирается процесс p3, как обладающий наивысшим приоритетом. После его завершения в момент времени t = 5 в очереди процессов готовых к исполнению окажутся два процесса p0 и p1. Больший приоритет из них у процесса p1 он и начнет выполняться (см. таблицу 9). Затем в момент времени t = 8 для исполнения будет избран процесс p2 и лишь потом процесс p0.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | Г | Г | Г |
| p1 | Г | Г | Г | И | И | |||||
| p2 | Г | И | И | И | ||||||
| p3 | И | И | И | И | И |
| время | ||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | И |
| p1 | ||||||||||
| p2 | И | И | И | И | ||||||
| p3 |
Таблица 9.
Иным будет предоставление процессора процессам в случае вытесняющего приоритетного планирования (см. таблицу 10). Первым, как и в предыдущем случае, исполняться начнет процесс p3, а по его окончании процесс p1. Однако в момент времени t = 6 он будет вытеснен процессом p2 и продолжит свое выполнение только в момент времени t = 13. Последним, как и раньше будет исполнен процесс p0.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | Г | Г | Г |
| p1 | Г | Г | Г | И | Г | Г | Г | Г | ||
| p2 | И | И | И | И | ||||||
| p3 | И | И | И | И | И |
| время | ||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | И |
| p1 | Г | Г | Г | И | ||||||
| p2 | И | И | И | |||||||
| p3 |
Таблица 10.
В рассмотренном выше примере приоритеты процессов не изменялись с течением временем. Такие приоритеты принято называть статическими. Механизмы статической приоритетности легко реализовать, и они сопряжены с относительно небольшими издержками на выбор наиболее приоритетного процесса. Однако статические приоритеты не реагируют на изменения ситуации в вычислительной системе, которые могут сделать желательной корректировку порядка исполнения процессов. Более гибкими являются динамические приоритеты процессов, изменяющие свои значения по ходу исполнения процессов. Начальное значение динамического приоритета, присвоенное процессу, действует в течение лишь короткого периода времени, после чего ему назначается новое, более подходящее значение. Изменение динамического приоритета процесса является единственной операцией над процессами, которую мы до сих пор не рассмотрели. Как правило, изменение приоритета процессов проводится согласованно с совершением каких-либо других операций: при рождении нового процесса, при разблокировке или блокировании процесса, по истечении определенного кванта времени или по завершении процесса. Примерами алгоритмов с динамическими приоритетами являются алгоритм SJF и алгоритм гарантированного планирования. Схемы с динамической приоритетностью гораздо сложнее в реализации и связанны с большими издержками по сравнению со статическими схемами. Однако их использование предполагает, что эти издержки оправдываются улучшением поведения системы. Главная проблема приоритетного планирования заключается в том, что при ненадлежащем выборе механизма назначения и изменения приоритетов низкоприоритетные процессы могут быть не запущены неопределенно долгое время.