Постепенная формализация в задачах моделирования процессов прохождения информации в системах управления
Принципиальной особенностью метода постепенной формализации модели принятия решения [5] является то, что она ориентирована на развитие представлений исследователя об объекте или процессе принятия решений, на постепенное "выращивание" формализованной модели. Поэтому предусматривается не одноразовый выбор методов моделирования, а смена методов по мере развития у ЛПР представлений об объекте и проблемной ситуации в направлении все большей формализации модели принятия решения.
Для формирования и анализа модели постепенной формализации была разработана методика системного анализа, сочетающая методы из групп МАИС и МФПС, которые помогают создать язык моделирования, процедуру оценки вариантов решения и автоматизировать процесс "выращивания" решения. Возможный вариант смены методов по мере развития модели проиллюстрируем на упрощенном примере моделирования процессов прохождения информации в процессе ее регистрации, передачи и предварительной обработки (сортировки, укрупнения и т.п.).
Основная идея постепенной формализации иллюстрируется рис. 6.4, на котором показаны последовательные переходы от методов работы с ЛПР (из группы МАИС) к методам формализованного представления, и обратно.
В методике системного анализа для решения данной задачи удобно предусмотреть два основных этапа.
1. Формирование модели, отображающей возможные варианты прохождения информации в АИС (этот этап иллюстрируют рис. 6.4 и 6.5).
2. Оценка модели и выбор наилучшего варианта пути прохождения информации (рис. 6.6).
Охарактеризуем кратко эти этапы.
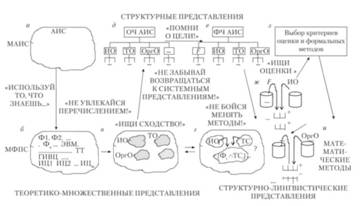
Рис. 6.6. Иллюстрация идеи постепенной формализации
Лекция 1. Формирование модели, отображающей возможные варианты прохождения информации в АИС
1.1. Отграничение системы от среды ("перечисление" элементов системы).
Подэтап может выполняться с применением метода "мозговой атаки", а в реальных условиях — методов типа комиссий, семинаров и других форм коллективного обсуждения, в результате которого определяется некоторый перечень элементов будущей системы. В состав таких комиссий должны входить и разработчики, и будущие пользователи АИС.
Задачу "перечисления" можно представить на языке теоретико-множественных методов как переход от названия характеристического свойства, отраженного в названии формируемой системы и множества ее элементов, к перечислению элементов, которые отвечают этому свойству и могут быть включены в исходное множество.
На рис. 6.4, б и 6.5, а перечислено для примера небольшое число исходных элементов: ГИВЦ, ИЦ, ИЦ,Al, А,... — пункты сбора и обработки информации; Ф, Ф,... — формы сбора и представления информации (документы, массивы); ЭВМ, ТТ (телетайп), Т (телефон),... и т.д.
Понятно, что в реальных условиях конкретных видов подобных элементов существенно больше и они будут названы более конкретно — не ЭВМ, а тип ЭВМ; аналогично — тип ТТ, регистраторов производства (РИ), наименование или код документов и массивов и т.д.
1.2. Объединение элементов в группы.
Не следует слишком увлекаться подэтапом "перечисления" (хотя на практике это и имело место). Сложную реальную развивающуюся систему невозможно "перечислить" полностью. Следует, набрав некоторое множество элементов, попытаться объединить их в группы, найти меры сходства, "близости" и предложить способ их объединения.
Если в качестве метода формализованного отображения совокупности элементов выбраны теоретико-множественные представления, то этот подэтап можно трактовать как образование из элементов исходного множества некоторых подмножеств путем перехода от перечисления сходных по какому-то признаку элементов к названию характеристического свойства этого подмножества. В результате в приводимом примере могут быть образованы подмножества элементов по соответствующим видам обеспечения — ИО, ТО, ОргО (рис. 6.4, в и 6.5, б).
Примечание. Можно было бы предусмотреть еще один подэтап разделения подмножеств на более мелкие.
1.3. Формирование из элементов подмножеств новых множеств, состоящих из "пар", "троек", "п-к" элементов исходных подмножеств.
В рассматриваемом примере, объединяя элементы подмножеств ИО, ТО, ОргО в "пары" и "тройки", можно получить, например: Ф_ЭВМ, Ф_ТТ, ФЭВМ и т.п.; ЭВМ_ ГИВЦ, ЭВМ_ИЦ, ЭВМ_А, ТТ_ГИВЦ, ТТ_ИВЦ, ТТ_А и т.п.; ФЭВМГИВЦ, ФТТА и т.д.
Иногда в задачах моделирования на этом этапе можно получить новый результат, который подсказывает путь дальнейшего анализа.
Но в данном примере, как правило, интерпретация получаемых компонентов затруднена и ввести какое-либо формальное правило сравнения элементов новых множеств для принятия решения о выборе наилучших не удается. В таких случаях, согласно рассматриваемому подходу, нужно обратиться к системно-структурным представлениям и попытаться поискать дальнейший путь развития модели.
Отметим, что отражением данного подэтапа в истории развития проектных работ по созданию АСУ был период, когда формировались матрицы "документы — технические средства", "информационные службы — технические средства" и на основе экспертной оценки элементов этих матриц пытались принимать решения, связанные с формированием структуры АИС.
1.4. Содержательный анализ полученных результатов и поиск новых путей развития модели.
Для проведения содержательного анализа следует возвратиться к системным представлениям и использовать один из методов группы МАИС — структуризацию (в данном случае в форме иерархической структуры — рис. 6.4, д и 6.5, в).
Такое представление более удобно для руководителей работ по созданию АСУ, чем теоретико-множественные представления, и помогает им вначале распределить работу между соответствующими специалистами по ИО, ТО и т.д., а затем найти дальнейший путь развития модели на основе содержательного анализа сути полученных "пар" и "троек" с точки зрения формулировки решаемой задачи.
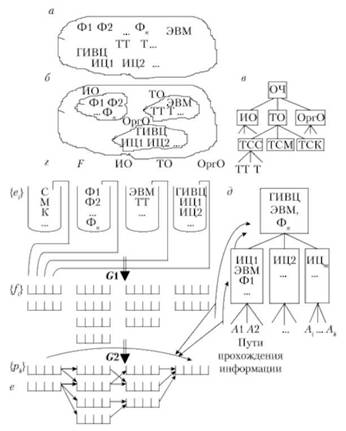
Рис. 6.5. Иллюстрация формирования графо-семиотической модели
При моделировании рассматриваемой задачи помимо определения видов обеспечения нужно разместить их так, чтобы обеспечить наиболее эффективную реализацию задач, подлежащих автоматизации. А поскольку любая задача представляет собой последовательность действий (функций) по сбору, хранению и первичной обработке информации, то становится очевидной необходимость внесения в модель нового подмножества "функции-операции (ФО)>>, добавление элементов которого к прежним "парам" и "тройкам" позволяет получить новое их осмысление (рис. 6.4, е).
Для того чтобы глубже понять развитие модели постепенной формализации, проиллюстрируем изложенную идею на конкретном примере.
Предположим, что нужно принять решение о структуре АИС, отрасли предприятия которой расположены в разных городах, как первой очереди ОАСУ.
Предварительно рассматривались два основных варианта:
1) увеличение мощности единого Главного информационно-вычислительного центра (ГИВЦ) отрасли и организации централизованного сбора от всех предприятий посредством установленных на них периферийных средств сбора информации (/11, /12,.... Ак);
2) наряду с ГИВЦ и периферийными средствами сбора на предприятиях создать региональные ИВЦ (обозначенные на рис. 6.4 ИЦ, ИЦ,ИЦ/и), которые будут расположены в городах.
Необходимо выбрать вариант и определить требуемую вычислительную мощность ГИВЦ и региональных ИВЦ (в случае выбора второго варианта), типы ЭВМ для ГИВЦ и ИВЦ, типы периферийных средств регистрации информации, объемы информационных массивов в ГИВЦ и ИВЦ, формы документов Ф, Ф,Фп сбора и передачи информации между пунктами, принятыми в соответствующем варианте. При этом следует иметь в виду, что в случае выбора первого варианта возникают проблемы диспетчеризации приема-передачи информации от достаточно многочисленных пунктов первичного сбора информации на предприятиях.
Аналогично может быть поставлена задача для корпораций, фирмы которых расположены в разных городах (как, например, в Объединении АвтоВАЗ), или для предприятии, крупные производства которых расположены в разных корпусах.
Для ответа на требуемые вопросы необходимо исследовать информационные потоки.
Для простоты на рис. 6.5 показаны только принципиально отличающиеся друг от друга функции — связи С, хранения М и обработки К. После их добавления получаются комбинации, которые ЛПР могут не только сравнивать, но и оценивать.
Например, комбинации типа С_Ф_ТТ и С_Ф_Т отличаются друг от друга скоростями передачи информации, которые в конкретных условиях можно измерить или вычислить.
Если бы задача не была сформулирована, то при содержательном осмыслении результатов предшествующих этапов нужно было бы уточнить формулировку задачи, что и помогло бы сделать дальнейший шаг в развитии модели.
Примечание. Важно отметить, что применение на практике матричных представлений, упомянутых в предыдущем пункте, обратило внимание разработчиков на тот факт, что анализировать названные матрицы практически невозможно, если не задумываться над тем, для решения каких задач предназначены технические средства и документы. Тогда стали формировать матрицы "задачи — методы", "задачи — средства", т.е. вводить фактически новое множество — "Задачи" или "Функции (Г)".
1.5. Разработка языка моделирования.
После того как найдено недостающее подмножество, в принципе можно было бы продолжить дальнейшее формирование модели, пользуясь теоретико-множественными представлениями. Однако когда осознана необходимость формирования последовательностей функций-операций, конкретизированных путем дополнения их видами обеспечения — конкретизированных функций (КФ), то целесообразнее выбрать лингвистические представления, которые удобнее для разработки языка моделирования последовательностей КФ.
Тогда в терминах лингвистических представлений данный этап можно представить следующим образом: 1) разработка тезауруса языка моделирования; 2) разработка грамматики (или нескольких грамматик, что зависит от числа уровней модели и различий правил). Структура тезауруса языка моделирования, приведенная на рис. 6.4, ж и 6.5, г, включает три уровня:
- уровень первичных терминов (или слов), которые представлены в виде списков, состоящих из элементов {еЦ подмножеств ФО, ИО, ТО, ОргО;
— уровень фраз который в этом конкретном языке можно назвать уровнем КФ, так как абстрактные функции С, М, К, объединяясь с элементами подмножеств ИО, ТО, ОргО, конкретизируются применительно к моделируемому процессу;
— уровень предложений {рк}, отображающий варианты прохождения информации при решении той или иной задачи.
Грамматика языка включает правила двух видов: (Л — преобразования элементов {е:} первого уровня тезауруса в компоненты {/^} второго уровня, которые имеют характер правил типа "помещения рядом" (конкатенации, сцепления, /?[ на рис. 6.6);
С — преобразования компонентов в предложения {рк) (варианты прохождения информации) — правила типа "условного следования за" (йц на рис. 6.6); правила этого вида исключают из рассмотрения недопустимые варианты следования информации: например, после функции С_Ф_ Л-ИЦТТ (передача документа Ф из Ф в ИЦ с помощью ТТ) не может следовать функция М_Ф_ГИВЦ_МН, так как в результате выполнения предшествующей функции документ Ф в ГИВЦ не поступил (здесь МН — машинный носитель).
Используя разработанный язык, процедуру формирования модели можно автоматизировать. При этом правила типа а и а относительно несложно реализуются с помощью языков логического программирования, и в частности языка Турбо-Пролог.