Перспективы развития информетрии
На основе идей законов Ципфа – Мандельброта и Брэдфорда – Викери, закономерности концентрации – рассеяния, сформулированной В. И. Горьковой, развиваются методики автоматизации индексирования и анализа текстов, введения весовых коэффициентов терминов [1].
Вводятся меры веса ключевых слов.
Так, в работах Спарка Джонса экспериментально показано, что если N – число документов и п – число документов, в которых встречается данный индексный термин (ключевое слово), то его вес вычисляется по формуле
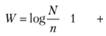
и приводит к более эффективным результатам поиска, чем без использования оценки значимости индексного термина, т.е. определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается.
Вводятся логарифмические меры.
Например, чтобы избавиться от лишних слов и в то же время поднять рейтинг значимых слов, вводят инверсную частоту термина
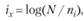
где N – количество документов в базе данных; ni – количество документов с термином i.
А затем каждому термину присваивают весовой коэффициент, отражающий его значимость в форме
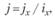
где j – вес термина i в документе; jx – частота термина i в документе; ix – инверсная частота термина.
В новом смысле используется термин "ядро".
В 1995 г. на симпозиуме в Дублине была предложена интересная и полезная для совершенствования информационного поиска идея "Дублинского ядра" (Dublin Core) [2], основанная на формировании метаданных, зафиксированных в спецификации определенного стандарта, и на представлении k-го документа множеством пар D„ = {Nik, Vik}, где Nik– имя i-го элемента метаданных Дублинского ядра в описании содержания k-го документа; – значение этого элемента метаданных. Аналогично описывается запрос.
Перспективным представляется использование для формирования "Дублинского ядра" закономерности концентрации-рассеяния.
Возрастает интерес и к способам оценки текстов. Например, к работам Г. Луна [3], в которых предложения текста оцениваются в соответствии с параметром
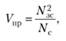
где V – значимость предложения; Ν.κ – число значимых слов в предложении; Nc – полное число слов в предложении.
Используя этот критерий, из любого документа можно отобрать некоторое число предложений. Понятно, что они не будут составлять членораздельного текста. Нужно учитывать также, что значимые слова должны браться из тематического тезауруса или отбираться экспертом. По этой причине методика может лишь помочь человеку, а не заменить его (во всяком случае, на современном этапе развития вычислительной техники).
Закономерности организации ДИП, введения количественных мер терминов, предложений и других компонентов текста полезно использовать на всех этапах создания информационно-поисковых систем: при комплектовании информационных фондов, создании информационно-поисковых языков и логико-семантического аппарата ИПС, при организации справочно-информационного обслуживания в библиотеках и отделах научно-технической информации, при создании и совершенствовании классификационных систем, выявлении тенденций роста и старения ДИП, при аналитико-синтетической обработке текстовой информации.
В последнее время на основе идеи закономерности концентрации – рассеяния разрабатываются методы выявления информационного ядра предметной области при построении информационной системы для реорганизации бизнес-процессов, при создании виртуальных предприятий.