Оценка адекватности и точности трендовых моделей
Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность - в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования.
Трендовая модель  , конкретного временного ряда yt, считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента
, конкретного временного ряда yt, считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента  (t = 1, 2, ..., п) удовлетворяла свойствам случайной компоненты временного ряда, указанным в параграфе 4.1: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
(t = 1, 2, ..., п) удовлетворяла свойствам случайной компоненты временного ряда, указанным в параграфе 4.1: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
Проверка случайности колебаний уровней остаточной последовательности означает проверку гипотезы о правильности выбора вида тренда. Для исследования случайности отклонений от тренда мы располагаем набором разностей

Характер этих отклонений изучается с помощью ряда непараметрических критериев. Одним из таких критериев является критерий серий, основанный на медиане выборки. Ряд из величин е, располагают в порядке возрастания их значений и находят медиану εт полученного вариационного ряда, т.е. срединное значение при нечетном п, или среднюю арифметическую из двух срединных значений, при п четном. Возвращаясь к исходной последовательности εt и сравнивая значения этой последовательности с εт, будем ставить знак "плюс", если значение εt превосходит медиану, и знак "минус", если оно меньше медианы; в случае равенства сравниваемых величин соответствующее значение εt опускается. Таким образом, получается последовательность, состоящая из плюсов и минусов, общее число которых не превосходит п. Последовательность подряд идущих плюсов или минусов называется серией. Для того чтобы последовательность е, была случайной выборкой, протяженность самой длинной серии не должна быть слишком большой, а общее число серий - слишком малым.
Обозначим протяженность самой длинной серии через Кmax, а общее число серий - через ν. Выборка признается случайной, если выполняются следующие неравенства для 5%-ного уровня значимости:

 (5.8)
(5.8)
где квадратные скобки означают целую часть числа.
Если хотя бы одно из этих неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая модель признается неадекватной.
Другим критерием для данной проверки может служить критерий пиков (поворотных точек). Уровень последовательности εt считается максимумом, если он больше двух рядом стоящих уровней, т.е. εt-1 < εt > εt+1, и минимумом, если он меньше обоих соседних уровней, т.е. εt-1 > εt < εt+1. В обоих случаях εt считается поворотной точкой; общее число поворотных точек для остаточной последовательности εt обозначим через р. В случайной выборке математическое ожидание числа точек поворота р и дисперсия σ2р выражаются формулами:

Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства
 (5.9)
(5.9)
где квадратные скобки означают целую часть числа. Если это неравенство не выполняется, трендовая модель считается неадекватной.
Проверка соответствия распределения остаточной последовательности нормальному закону распределения может быть произведена лишь приближенно с помощью исследования показателей асимметрии (γ1) и эксцесса (γ2), так как временные ряды, как правило, не очень велики. При нормальном распределении показатели асимметрии и эксцесса некоторой генеральной совокупности равны нулю. Мы предполагаем, что отклонения от тренда представляют собой выборку из генеральной совокупности, поэтому можно определить только выборочные характеристики асимметрии и эксцесса и их ошибки:
 (5.10)
(5.10)
В этих формулах  - выборочная характеристика асимметрии;
- выборочная характеристика асимметрии;  - выборочная характеристика эксцесса;
- выборочная характеристика эксцесса;  и
и  - соответствующие среднеквадратические ошибки. Если одновременно выполняются следующие неравенства:
- соответствующие среднеквадратические ошибки. Если одновременно выполняются следующие неравенства:

то гипотеза о нормальном характере распределения остаточной последовательности принимается.
Если выполняется хотя бы одно из неравенств

то гипотеза о нормальном характере распределения отвергается, трендовая модель признается неадекватной. Другие случаи требуют дополнительной проверки с помощью более сложных критериев.
Кроме рассмотренного метода известен ряд других методов проверки нормальности закона распределения случайной величины: метод Вестергарда, RS-критерий и т.д. Рассмотрим наиболее простой из них, основанный на RS-критерии. Этот критерий численно равен отношению размаха вариации случайной величины R к стандартному отклонению S.
В нашем случае  , а
, а  . Вычисленное значение критерия сравнивается с табличными (критическими) нижней и верхней границами данного отношения, и если это значение не попадает в интервал между критическими границами, то с заданным уровнем значимости гипотеза о нормальности распределения отвергается; в противном случае эта гипотеза принимается. Для иллюстрации приведем несколько пар значений критических границ RS-критерия для уровня значимости а = 0,05: при п = 10 нижняя граница равна 2,67, а верхняя равна 3,685; при п = 20 эти числа составляют соответственно 3,18 и 4,49; при п = 30 они равны 3,47 и 4,89.
. Вычисленное значение критерия сравнивается с табличными (критическими) нижней и верхней границами данного отношения, и если это значение не попадает в интервал между критическими границами, то с заданным уровнем значимости гипотеза о нормальности распределения отвергается; в противном случае эта гипотеза принимается. Для иллюстрации приведем несколько пар значений критических границ RS-критерия для уровня значимости а = 0,05: при п = 10 нижняя граница равна 2,67, а верхняя равна 3,685; при п = 20 эти числа составляют соответственно 3,18 и 4,49; при п = 30 они равны 3,47 и 4,89.
Проверка равенства математического ожидания остаточной последовательности нулю, если она распределена по нормальному закону, осуществляется на основе i-критерия Стыодента. Расчетное значение этого критерия задается формулой
 (5.11)
(5.11)
где 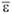 - среднее арифметическое значение уровней остаточной последовательности εt;
- среднее арифметическое значение уровней остаточной последовательности εt;
Sε - стандартное (среднеквадратическое) отклонение для этой последовательности.
Если расчетное значение t меньше табличного значения tα статистики Стьюдента с заданным уровнем значимости α и числом степеней свободы п - 1, то гипотеза о равенстве нулю математического ожидания остаточной последовательности принимается; в противном случае эта гипотеза отвергается и модель считается неадекватной.
Следует отметить, что проверку данного свойства на основе t-критерия имеет смысл проводить лишь в том случае, когда это свойство не очевидно из самого значения величины  .
.
Проверка независимости значений уровней остаточной последовательности, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности может осуществляться по ряду критериев, наиболее распространенным из которых является d-критерий Дарбина - Уотсона. Расчетное значение этого критерия определяется по формуле
 (5.12)
(5.12)
Заметим, что расчетное значение критерия Дарбина - Уотсона в интервале от 2 до 4 свидетельствует об отрицательной связи; в этом случае его надо преобразовать по формуле d' = 4 - d и в дальнейшем использовать значение d'.
Расчетное значение критерия d (или d') сравнивается с верхним d2 и нижним dt критическими значениями статистики Дарбина - Уотсона, фрагмент табличных значений которых для различного числа уровней ряда п и числа определяемых параметров модели k представлен для наглядности в табл. 5.2 (уровень значимости 5%).
Таблица 5.2
|
п |
k = 1 |
k = 2 |
k = 3 |
|||
|
d1 |
d2 |
d1 |
d2 |
d1 |
d2 |
|
|
15 |
1,08 |
1,36 |
0,95 |
1,54 |
0.82 |
1,75 |
|
20 |
1,20 |
1,41 |
1,10 |
1,54 |
1.00 |
1,68 |
|
30 |
1,35 |
1,49 |
1,28 |
1,57 |
1,21 |
1,65 |
Если расчетное значение критерия d больше верхнего табличного значения d2, то гипотеза о независимости уровней остаточной последовательности, т.е. об отсутствии в ней автокорреляции, принимается. Если значение d меньше нижнего табличного значения d1, то эта гипотеза отвергается и модель неадекватна. Если значение d находится между значениями d1 и d2, включая сами эти значения, то считается, что нет достаточных оснований сделать тот или иной вывод и необходимы дальнейшие исследования, например, по большему числу наблюдений. В этом случае можно использовать также первый коэффициент автокорреляции:

Если расчетное значение этого коэффициента по модулю меньше табличного (критического) значения r1кр, то гипотеза об отсутствии автокорреляции принимается; в противном случае эта гипотеза отвергается. В частности, при п = 10 можно принять r1кр = 0,36.
Вывод об адекватности трендовой модели делается, если все указанные выше четыре проверки свойств остаточной последовательности дают положительный результат. Для адекватных моделей имеет смысл ставить задачу оценки их точности. Точность модели характеризуется величиной отклонения выхода модели от реального значения моделируемой переменной (экономического показателя). Для показателя, представленного временным рядом, точность определяется как разность между значением фактического уровня временного ряда и его оценкой, полученной расчетным путем с использованием модели, при этом в качестве статистических показателей точности применяются следующие: среднее квадратическое отклонение
 (5.13)
(5.13)
средняя относительная ошибка аппроксимации
 (5.14)
(5.14)
коэффициент сходимости
 (5.15)
(5.15)
коэффициент детерминации
 (5.16)
(5.16)
и другие показатели; в приведенных формулах п - количество уровней ряда, k - число определяемых параметров модели,  - оценка уровней ряда по модели,
- оценка уровней ряда по модели,  - среднее арифметическое значение уровней ряда.
- среднее арифметическое значение уровней ряда.
На основании указанных показателей можно сделать выбор из нескольких адекватных трендовых моделей экономической динамики наиболее точной, хотя может встретиться случай, когда по некоторому показателю более точна одна модель, а по другому - другая.
Данные показатели точности моделей рассчитываются на основе всех уровней временного ряда и поэтому отражают лишь точность аппроксимации. Для оценки прогнозных свойств модели целесообразно использовать так называемый ретроспективный прогноз - подход, основанный на выделении участка из ряда последних уровней исходного временного ряда в количестве, допустим, п2 уровней в качестве проверочного, а саму трендовую модель в этом случае следует строить по первым точкам, количество которых будет равно п1 = п - п2. Тогда для расчета показателей точности модели по ретроспективному прогнозу применяются те же формулы, но суммирование в них будет вестись не по всем наблюдениям, а лишь по последним п2 наблюдениям. Например, формула для среднего квадратического отклонения будет иметь вид

где  - значения уровней ряда по модели, построенной для первых и, уровней.
- значения уровней ряда по модели, построенной для первых и, уровней.
Оценивание прогнозных свойств модели на ретроспективном участке весьма полезно, особенно при сопоставлении различных моделей прогнозирования из числа адекватных. Однако надо помнить, что оценки ретропрогноза - лишь приближенная мера точности прогноза и модели в целом, так как прогноз на период упреждения делается по модели, построенной по всем уровням ряда.
Пример 5.1. Для временного ряда, представленного в первых двух графах табл. 5.3, построена трендовая модель в виде полинома первой степени (линейная модель):

Требуется оценить адекватность и точность построенной модели.
Решение. Прежде всего, сформируем остаточную последовательность (ряд остатков), для чего из фактических значений уровней ряда вычтем соответствующие расчетные значения по модели: остаточная последовательность приведена в графе 4 табл. 5.3.
Проверку случайности уровней ряда остатков проведем на основе критерия пиков (поворотных точек). Точки пиков отмечены в графе 5 табл. 5.3; их количество равно шести (р = 6). Правая часть неравенства (5.9) равняется в данном случае двум, т.е. это неравенство выполняется. Следовательно, можно сделать вывод, что свойство случайности ряда остатков подтверждается.
Результаты предыдущей проверки дают возможность провести проверку соответствия остаточной последовательности нормальному закону распределения. Воспользуемся RS-критерием. В нашем случае размах вариации R = εmax - εmin = 2,7 - (-2,1) = 4,8, а среднее квадратическое отклонение

Таблица 5.3
|
t |
Фактическое yt |
Расчетное |
Отклонение εt |
Точки пиков |
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
1 |
85 |
84,4 |
0,6 |
- |
0,36 |
- |
- |
0,71 |
|
2 |
81 |
81,0 |
0,0 |
1 |
0,00 |
-0,6 |
0,36 |
0,00 |
|
3 |
78 |
77,6 |
0,4 |
1 |
0,16 |
0,4 |
0,16 |
0,49 |
|
4 |
72 |
74,1 |
-2,1 |
1 |
4,41 |
-2,5 |
6,25 |
2,69 |
|
5 |
69 |
70,7 |
-1,7 |
0 |
2,89 |
0,4 |
0,16 |
2,46 |
|
6 |
70 |
67,3 |
2,7 |
1 |
7,29 |
4,4 |
19,36 |
3,86 |
|
7 |
64 |
63,8 |
0,2 |
1 |
0,04 |
-2,5 |
6,25 |
0,31 |
|
8 |
61 |
60,4 |
0,6 |
1 |
0,36 |
0,4 |
0,16 |
0,98 |
|
9 |
56 |
57,0 |
-1,0 |
- |
1,00 |
-1,6 |
2,56 |
1,79 |
|
45 |
636 |
636,3 |
-0,3 |
6 |
16,51 |
35,26 |
13,29 |





Следовательно, критерий RS = 4,8 : 1,44 = 3,33, и это значение попадает в интервал между нижней и верхней границами табличных значений данного критерия (эти границы для п = 10 и уровня значимости α = 0,05 составляют соответственно 2,7 и 3,7). Это позволяет сделать вывод, что свойство нормальности распределения выполняется.
Переходя к проверке равенства (близости) нулю математического ожидания ряда остатков, заметим, что по результатам вычислений в табл. 5.3 это математическое ожидание равно (-0,3) : 9 = -0,03 и, следовательно, можно подтвердить выполнение данного свойства, не прибегая к статистике Стьюдента.
Для проверки независимости уровней ряда остатков (отсутствия автокорреляции) вычислим значение критерия Дарбина - Уотсона.
Расчеты по формуле (5.12), представленные в графах 6, 7, 8 табл. 5.3, дают следующее значение этого критерия: d = 35,26 : 15,51 = 2,27. Эта величина превышает 2, что свидетельствует об отрицательной автокорреляции (при наличии последней), поэтому критерий Дарбина - Уотсона необходимо преобразовать: d' = А - d = А - 2,27 = 1,73. Данное значение сравниваем с двумя критическими табличными значениями критерия, которые для линейной модели в нашем случае можно принять равными d1 = 1,08 и d2 = 1,36. Так как расчетное значение попадает в интервал от (d2 до 2, то делается вывод о независимости уровней остаточной последовательности.
Из сказанного выше следует, что остаточная последовательность удовлетворяет всем свойствам случайной компоненты временного ряда, следовательно, построенная линейная модель является адекватной.
Для характеристики точности модели воспользуемся показателем средней относительной ошибки аппроксимации, который рассчитывается по формуле (5.14):  = 13,29 : 9 = 1,48 (%). Полученное значение средней относительной ошибки говорит о достаточно высоком уровне точности построенной модели (ошибка менее 5% свидетельствует об удовлетворительном уровне точности; ошибка в 10 и более процентов считается очень большой).
= 13,29 : 9 = 1,48 (%). Полученное значение средней относительной ошибки говорит о достаточно высоком уровне точности построенной модели (ошибка менее 5% свидетельствует об удовлетворительном уровне точности; ошибка в 10 и более процентов считается очень большой).