Основа для построения выборки
Основу для построения выборки (sampling frame) составляют списки элементов исследуемой совокупности или правила нахождения этих элементов.
Примером правил нахождения элементов исследуемой совокупности может служить список всевозможных семизначных телефонных номеров, перемешанных случайным образом. Еще один пример - правила отбора интервьюером домохозяйств, в которых будет проводиться опрос. При использовании этого способа интервьюеру задаются маршрут (например, дома определенного избирательного участка) и правило отбора квартир в этих домах (например, в соответствии со списком трехзначных случайных чисел).
Часто эти два способа комбинируются: на одних ступенях построения выборки используют списки, а на других - правила нахождения. Так, при опросе о жевательной резинке (см. с. 289) на первой ступени отбора применялись списки административных округов. На второй - списки более мелких административных единиц в отобранных на первой ступени округах. На третьей ступени - список маршрутов в отобранных на второй ступени более мелких административных единицах. А далее в ход пошли уже не списки, а правила нахождения сначала жилищ, а затем детей нужного возраста.
Часто бывает так, что список элементов исследуемой совокупности можно достать или составить, но он окажется неидеальным: некоторые элементы пропущены, а некоторые позиции лишние. В таких ситуациях возникают уже упоминавшиеся ошибки основы выборки, относящиеся к категории ошибок исследователя (см. с. 188).
Иногда несоответствий в списках так мало, что ими можно пренебречь. Но чаще исследователь должен их скорректировать. Существуют три способа такой коррекции. Первый - переопределение исследуемой совокупности: ее называют так, чтобы она соответствовала имеющейся в наличии основе выборки. Например, вместо исследуемой совокупности: "семьи, проживающие в данном городе" берут другую: "семьи, чьи телефоны приведены в телефонной книге данного города". Такое переопределение делает исследование более "честным", но не исключает возможности получения ошибочных выводов относительно тех людей, чьи мнения нужно изучить.
Второй способ - отсев лишних элементов выборки на стадии проведения опроса. Потенциальным респондентам задаются "вопросы-фильтры". На основе полученных ответов принимается решение, проводить с ними интервью или не проводить. Например, выясняются их социально-демографические характеристики, степень знакомства с товаром и опыт его использования. Далее опрашивают только тех, кто ответил на вопросы-фильтры нужным для исследователя образом. Такая фильтрация позволяет избежать включения в выборку лишних элементов, но, естественно, не спасает, если элемент в списке отсутствует.
Третий способ - "взвешивание", выравнивание данных путем задания весовых коэффициентов, позволяющих скорректировать ошибки основы выборки. Например, при опросе о жевательной резинке основа выборки была организована так, что в ходе отбора респондента использовались половозрастные квоты. В этих квотах, как уже отмечалось, были предусмотрены две градации возраста. Это достаточно грубое деление привело к искажениям структуры опрошенных внутри первой из этих градаций (8-12 лет). Для исправления пропорций были применены весовые коэффициенты.
Поясним идею взвешивания следующим примером. Если в выборке 40% - мужчины, 60% - женщины, а в исследуемой совокупности (скажем, в составе населения) 46% мужчин и 54% женщин, то число респондентов, выбравших какой-либо определенный ответ на вопрос анкеты, будет рассчитываться по формуле:
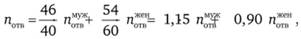
где  ,
, 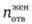 и
и 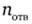 - число выбравших указанный ответ мужчин, женщин и респондентов обоего пола соответственно.
- число выбравших указанный ответ мужчин, женщин и респондентов обоего пола соответственно.
При необходимости поддержания не одной, а нескольких пропорций расчет, естественно, ведется по более сложным формулам. В самых сложных случаях, в частности при отсутствии статистической информации о детальной структуре исследуемой совокупности, используются специальные программные продукты, позволяющие в определенном смысле минимизировать искажения в структуре выборки.