Лекция 8. Модели представления и извлечения знаний
По мере активного развития компьютерного моделирования формируется самостоятельный класс моделей представления и извлечения знаний. В их числе модели, развиваемые на базе теории искусственного интеллекта, модели, построенные на принципах, заимствованных у природы, модели интеллектуального анализа данных (ИАД) — Data Mining.
Классификация моделей представления и извлечения знаний
В настоящее время нет единой классификации моделей представления и извлечения знаний. В числе этих моделей: модели, развиваемые на базе теории искусственного интеллекта (формальные, на основе исчисления высказываний и предикатов; неформальные семантические и реляционные; интегрированные или смешанные), модели, построенные на принципах, заимствованных у природы (эволюционные и генетические алгоритмы, иммунные сети, так называемые ройные модели), модели интеллектуального анализа данных (НАЛ) — Data Mining, включая модели описательной и предсказательной аналитики.
Одна из возможных классификаций этих моделей приведена на рис. 8.1.
Наиболее популярным и привлекательным для моделирования систем является Data Mining. Кроме того, в прикладной математике, искусственном интеллекте и интеллектуальном анализе данных для решения задач оптимизации широко применяются модели на принципах, заимствованных у природы.
Подходы кратко рассматриваются в следующих параграфах.
Модели на принципах, заимствованных у природы
Природа разумна, рациональна и изобретательна, поэтому можно назвать естественным стремление исследователей использовать в технических устройствах и системах принципы организации, свойств, функций и структур живой природы. В науке даже выделились два прикладных направления, отвечающих за это: бионика (от греч. — живущий) и биомиме-тика (от лат. bios — жизнь, и mimesis — подражание).
В прикладной математике и искусственном интеллекте процесс построения модели нередко сводится к решению некоторого конечного множества оптимизационных задач, а в интеллектуальном анализе данных вид оптимизационной функции целиком зависит отданных из обучаемой выборки. Нахождение глобального экстремума такой функции традиционными методами оптимизации является сложной, а часто нерешаемой задачей. Включение в математическую теорию условной и безусловной оптимизации моделей на принципах, заимствованных у природы, позволило получить новые результаты в оптимизации многоэкстремальных функций с большим числом переменных и экстремумов.
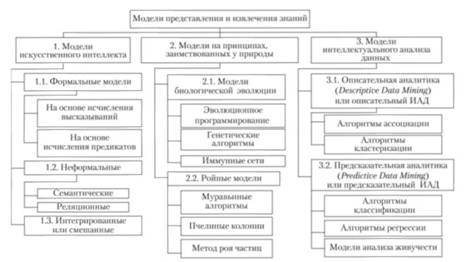
Рис. 8.1. Классификация моделей представления и извлечения знаний
Исторически первыми появились модели оптимизации на основе биологической эволюции: генетические алгоритмы, эволюционное программирование и иммунные сети.
Генетические алгоритмы (ГА) относятся к классу методов случайного направленного поиска. Но в отличие от простого случайного поиска в них используются механизмы генетической наследственности и естественного отбора. Впервые генетический алгоритм был предложен Д. Гольдбергом в 1989 г.1 на основе идей, изложенных Дж. Холландом в работе "Адаптация в естественных и искусственных системах".
Основная идея ГА состоит в создании популяции особей (индивидов), каждая из которых представляется в виде хромосомы. Любая хромосома есть возможное решение рассматриваемой оптимизационной задачи. Для поиска лучших решений необходимо знать только значение целевой функции, или функции приспособленности. Значение функции приспособленности особи показывает, насколько хорошо подходит особь, описанная данной хромосомой, для решения задачи.
Хромосома состоит из конечного числа генов, представляя генотип объекта, т.е. совокупность его наследственных признаков. Процесс эволюционного поиска ведется только на уровне генотипа. К популяции применяются основные биологические операторы: скрещивания, мутации, инверсии и др. В процессе эволюции действует известный принцип "выживает сильнейший". Популяция постоянно обновляется при помощи генерации новых особей и уничтожения старых, и каждая новая популяция становится лучше и зависит только от предыдущей. Основное отличие ГА от традиционных методов поиска оптимумов состоит в том, что ГА с каждой эпохой улучшает оптимальное решение, но не гарантирует нахождение лучшего за конечный промежуток времени.
Классическая схема ГА включает следующие шаги.
1. Задать начальный момент времени £ = 0. Создать начальную популяцию из к особей (размер популяции) Л) = {^1> ^2> •••• ДЛ-
2. Рассчитать приспособленность каждой особи F(Ai),i = =U.
3. Выбрать из популяции две особи Д-, А-г іф j.
4. Выполнить оператор кроссовера и мутации. В результате генерируется новая особь В (потомок).
5. Поместить полученную хромосому (или несколько хромосом) в новую популяцию Pl+i.
6. Выполнить оператор редукции, т.е. сократить размер новой популяции до исходного размера.
7. Выполнить шаги, начиная с п. 3, к раз.
8. Увеличить номер текущей эпохи t = t + 1.
9. При срабатывании условия останова завершить работу, иначе перейти на шаг 2.
Таким образом, генетический алгоритм можно записать в виде кортежа:
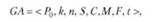
где Р0 — исходная популяция; к — ее размер; п — количество генов в хромосоме; 5, С, М — операторы отбора, кроссовера и мутации соответственно; Р — функция приспособленности; Ь — критерий останова.
Для представления генотипов особей в популяции используются различные схемы кодирования. Наиболее распространенным является двоичное кодирование. В генетическом алгоритме с двоичным кодированием для представления генотипа, как это следует из названия, применяются битовые строки. Каждому атрибуту объекта в фенотипе соответствует один ген в генотипе объекта. Задача кодирования и декодирования целочисленных признаков объектов тривиальна. Например, для кодирования значений переменных вектора Х = {х,х, —,хт], принимающих значения от 1 до 8, достаточно трех двоичных разрядов. В общем случае для кодирования параметра объекта требуется Мбит, причем N может быть различно для каждого из признаков.
Каждая переменная х,г=,т кодируется определенным участком хромосомы, состоящей из п генов. Каждый ген состоит из аллей. Декодирование хромосомы в вектор переменных осуществляется с помощью маски картирования, которая постоянна на протяжении работы ГА. Все генетические операции проводятся исключительно на уровне генотипа, т.е. с битовой строкой, а фенотип объекта используется при определении приспособленности особи.
Критерием останова генетического алгоритма может выступать ограничение на максимальное количество поколений, или когда средняя приспособленность популяции перестает изменяться заданное число эпох.
Одним из недостатков, существенно ограничивающим широкое применение генетических алгоритмов, является то, что для их успешной работы необходима их настройка. Эффективность генетического алгоритма напрямую и существенно зависит от его настроек и определяется выбранной схемой кодирования, используемыми операторами отбора, кроссовера и мутации.
В настоящее время генетические алгоритмы хорошо исследованы и широко применяются для решения комбинаторных и оптимизационных задач в экономике, технике и науке. Разработано большое количество разновидностей и модификаций простого ГА: вероятностный, динамический, нишевый, гибридный и др.
Эволюционное и генетическое программирование (основоположник — Л. Дж. Фогель, 1960 г.) решает большой класс задач теории вычислительных систем — научить компьютер решать поставленную задачу, не объясняя ему, как это делать. Данные алгоритмы занимаются поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа — методе группового учета аргументов (МГУА) — зависимость ищут в форме полиномов. Применение метода эволюционного программирования дает существенные преимущества в задачах, в которых классический математический анализ не позволяет получить аналитическое решение; задачах, в которых связь между независимыми и зависимыми переменными неизвестна либо известная связь подвергается сомнению.
Искусственные иммунные системы заимствуют у природы принцип иммунитета позвоночных, способность иммунитета к обучению и памяти. Первые разработки по иммунным системам были начаты в середине 70-х гг. XX в., но все полноценные исследования и математический аппарат были разработаны только в 1990-е гг., когда они стали широко применяться при проектировании систем для обнаружения компьютерных атак.
Естественная иммунная система человека представляет собой сложную систему и использует многоуровневую защиту против внешних антигенов, включая действие неспецифических (врожденных) и специфических (приобретенных) защитных механизмов. Основная роль иммунной системы заключается в распознавании всех клеток (или молекул) организма и классификации их как "своих" или "чужих". Чужеродные клетки подвергаются дальнейшей классификации с целью стимуляции защитного механизма соответствующего типа. В процессе эволюции иммунная система обучается различать внешние антигены (например, бактерии и вирусы) и собственные клетки или молекулы организма.
Применительно к задачам распознавания в качестве популяции антигенов иммунной сети выступает набор данных (векторов), которые нужно распознать. Алгоритм формирования иммунной сети включает в себя два этапа — обучение и распознавание. Обучение можно сравнить с вакцинацией организма, в обучающей выборке находятся образцы всех распознаваемых объектов (антигенов). В результате обучения происходит формирование иммунной памяти к антигенам. При распознавании на вход сети подается образ, и для всех лимфоцитов сети вычисляется аффинность к данному антигену и генерируется ответ иммунной сети.
Успех математического моделирования принципов эволюции живых организмов заставил исследователей обратиться к децентрализованным самоорганизующимся системам с коллективным поведением. Так появился целый класс моделей, условно названных ройными или роевым интеллектом (от англ. Swatm Intelligence): муравьиные и пчелиные алгоритмы, метод роя частиц или "стайный" алгоритм.
Алгоритмы муравьиных колоний (от англ. Ant Colony Optimization — АСО) моделируют поведение муравейника. Их основное применение — комбинаторная оптимизация. Идея и первая реализация алгоритма муравья была предложена М. Дориго в 1992 г. для поиска оптимального пути в графе.
Колония муравьев может рассматриваться как многоагентная система, в которой каждый агент (муравей) функционирует автономно по простым правилам, связанным с их способностью быстро находить кратчайший путь от муравейника к источнику пищи и адаптироваться к изменяющимся условиям, находя новый кратчайший путь. При своем движении муравей метит путь феромоном, и эта информация используется другими муравьями для выбора пути. Это элементарное правило поведения и определяет способность муравьев находить новый путь, если старый оказывается недоступным. В математической модели колонии муравьев используются формулы для расчета вероятностей перехода из одной точки в другую и для обновления феромона с использованием текущего уровня феромона, интенсивности испарения, стоимости текущего решения и др.
Метод пчелиных колоний (англ. Bee Colony Algorithm), предложенный группой английских исследователей в 2005 г., моделирует поведение пчел при поиске нектара и так же, как и алгоритм муравья, используется для комбинаторной оптимизации. Математическая модель пчелиной колонии включает в себя следующие понятия:
— источник нектара (характеризуется удаленностью от улья, концентрацией нектара, удобством его добычи);
— занятые фуражиры (завербованная в источник нектара пчела);
— незанятые фуражиры (свободные пчелы, занятые поиском источников нектара);
— пчела-разведчик (осуществляют облет территории и поиск источников нектара).
По возвращении в улей пчела-разведчик выполняет "вербовку" незанятых пчел с помощью танца на специальной площадке улья. Вероятность вербовки определяется полезностью соответствующего источника нектара. Завербованная пчела следует за пчелой-разведчиком к источнику нектара и становится занятым фуражиром.
Метод роя частиц (англ. Particle Swarm Optimization), канонический вариант которого был предложен в 1995 г.2, имитирует групповое поведение, например, стаи птиц и косяка рыб. Агентами в данном случае являются частицы в пространстве параметров задачи оптимизации. В каждый момент времени (на каждой итерации) частицы имеют в этом пространстве некоторое положение и вектор скорости. Для каждого положения частицы вычисляется соответствующее значение целевой функции, и на этой основе по определенным правилам частица меняет свое положение и скорость в пространстве поиска.
Отметим, что перечисленные методы — не исчерпывающий список в моделях роевого интеллекта. Разработаны методы передвижения бактерий, стохастического диффузионного поиска, алгоритмы капель воды, светлячков.