Логическая структура иерархической БД
Иерархическая модель данных была исторически первой структурой БД, видимо, из-за того, что древовидные иерархические структуры широко используются в повседневной человеческой деятельности. Это всевозможные классификаторы, ускоряющие поиск требуемой информации, иерархические функциональные структуры управления. Наиболее известной иерархической СУБД до сих пор остается IMS [1 – 11].
Элементами иерархической модели являются поле и сегмент. Структурные связи определяются подчиненностью, в силу чего сегмент более низкого уровня называют порожденным, а более высокого уровня – исходным. Сегмент самого верхнего уровня носит название корневой. Именно через него осуществляется доступ к иерархической БД (точка входа). Экземпляр порожденного сегмента не может существовать в отсутствие экземпляра исходного сегмента. В силу этого положения при удалении экземпляра исходного сегмента удаляются и все экземпляры порожденных сегментов.
Если структура запроса совпадает со структурой иерархической БД, то такая модель данных обладает самым высоким быстродействием и потому чаще всего применяется в суперЭВМ. В противном случае быстродействие может резко снизиться или данные совсем могут быть не получены. Чтобы избежать последнего неприятного случая, в иерархической МД вводят еще один тип связи – логической, о которой поговорим позднее. Иерархические, как и сетевые, МД могут быть представлены в виде графов: сегмент отражается в виде узла.
В графической диаграмме схемы базы данных вершины графа также используются для интерпретации типов сущностей, а дуги – типов связей между типами сущностей. При реализации каждая вершина графа представляется совокупностью описаний экземпляров сущности соответствующего типа.
В иерархической модели данных действуют более жесткие внутренние ограничения на представление связей между сущностями, чем в сетевой модели. Основные внутренние ограничения иерархической модели данных:
• все типы связей функциональные (1:1, 1:Μ, М:1);
• структура связей древовидная.
Результатом действия этих ограничений является ряд особенностей процесса структуризации данных в иерархической модели.
Древовидная структура (дерево) – это связный неориентированный граф, который не содержит циклов (петель) из замкнутых путей. Обычно при работе с деревом выделяют конкретную вершину, которую определяют как корень дерева, и рассматривают ее особо: в нее не заходит ни одно ребро. В этом случае дерево становится ориентированным. Корневое дерево можно определить следующим образом:
1) имеется единственная особая вершина, называемая корнем, в которую не заходит ни одно ребро;
2) во все остальные вершины заходит только одно ребро, а исходит произвольное количество ребер;
3) не имеется циклов.
В программировании используется другое определение дерева, позволяющее при решении задач рассматривать дерево как структуру, состоящую из меньших деревьев (или поддеревьев), т. е. как рекурсивную структуру.
Рекурсивно дерево определяется как конечное множество Т, состоящее из одного или более узлов (вершин), таких, что:
1) существует один специально выделенный узел, называемый корнем дерева;
2) остальные узлы разбиты на m > = 0 непересекающихся подмножеств Tt, T2, ..., Tm, каждое из которых в свою очередь является деревом.
Деревья Tt, Т2, .... Тт называются поддеревьями корня.
Из определения следует, что любой узел дерева является корнем некоторого поддерева, содержащегося в полном дереве. Число поддеревьев узла называют степенью узла. Узел называется концевым, если он имеет нулевую степень. Иногда концевые узлы называют листьями, а ребра – ветвями. Узел, не являющийся ни корнем, ни концевым узлом, называется узлом ветвления.
Таким образом, иерархическая древовидная структура, ориентированная от корня, удовлетворяет следующим условиям:
• узел состоит из одного или нескольких атрибутов;
• иерархия всегда начинается с корневого узла;
• на верхнем уровне может находиться только один узел – корневой;
• на нижних уровнях находятся порожденные (зависимые) узлы: они могут добавляться в вертикальном и горизонтальном направлениях без ограничения;
• каждый порожденный узел, находящийся на уровне i, связан только с одним непосредственно исходным узлом (непосредственным родительским узлом), находящимся на более высоком уровне (/-1) иерархии дерева;
• каждый исходный узел может иметь один или несколько непосредственно порожденных узлов, которые называются подобными (связи 1:М);
• доступ к каждому порожденному узлу выполняется через его непосредственно исходный узел;
• существует единственный иерархический путь доступа к любому узлу, начиная от корня дерева (рис. 6.7), например путь ABEI.
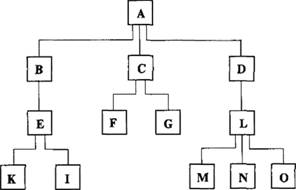
Рис. 6.7. Иерархический путь доступа
Поскольку узлы, входящие в иерархический путь, могут встретиться не более одного раза, иерархические пути в древовидной структуре линейны. Любой узел, находящийся на иерархическом пути выше рассматриваемого узла, является для последнего исходным узлом (родительским). Любой узел, находящийся на иерархическом пути ниже рассматриваемого узла, является для него порожденным узлом.
В иерархических моделях данных используется ориентация древовидной структуры от корня, т. е. дуги, соответствующие функциональным связям, направлены от корня к листьям дерева. Графическая диаграмма схемы базы данных для иерархической базы данных называется деревом определения.
Вершины дерева определения БД соответствуют введенным типам групп записей, с помощью которых выполнена интерпретация типов сущностей. Обычно допускают только простые типы групп, т. е. группа, представляющая вершину дерева определения, не должна включать составные и повторяющиеся группы, но их можно представить как самостоятельные вершины дерева определения. Корневой вершине дерева определения соответствует тип корневой группы, остальным вершинам – типы зависимых групп. Дуга дерева определения, соответствующая групповому отношению, представляет некоторый тип связи между рассматриваемыми типами сущностей (которые представлены соответствующими типами групп). Дуга исходит из типа родительской (исходной) группы и заходит в тип порожденной группы. Дуги обычно называют связью "исходный– порожденный". Поскольку между двумя типами групп может быть не более одной такой связи, то на графической диаграмме схемы иерархической базы данных связи могут специально не помечаться. Тип зависимой группы можно идентифицировать соответствующей последовательностью связей "исходный-порожденный". Иерархический путь в дереве определения представляется последовательностью групп, начинающейся типом корневой группы и заканчивающейся типом заданной группы.
Следствием внутренних ограничений иерархической модели является то, что каждому экземпляру зависимой группы в иерархической БД соответствует уникальное множество экземпляров родительских групп (по одному экземпляру каждого типа родительской группы).
Иерархия – это разновидность сети, являющаяся совокупностью деревьев (лесом), в которой все связи направлены от отца к сыну. Рассматривая этот тип моделей, будем использовать терминологию сетевых моделей, введя дополнительное понятие – тип виртуальной логической записи (необходим, когда надо поместить какой-либо тип записи в два или более деревьев иерархии или в нескольких местах в одном дереве). Такая логическая запись представляет собой указатель на логическую запись некоторого типа и устраняет избыточность.
Снова обратимся к рис. 3.4, в (см.). Теперь придется переместить некоторые поля в другие таблицы. На рис. 6.8 показана прямая связь ряда таблиц.
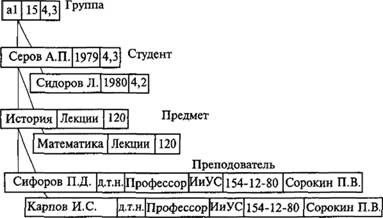
Рис. 6.8. Структура иерархической БД
Программная реализация иерархической БД
В иерархической МД имеется сильная зависимость логической структуры от физической, что хорошо видно из рис. 6.9 и программы на языке СУБД IMS, приведенной ниже.
DBD NAME=DB3, ACCESS=HISAM
DATASET D01=DEPTD01, DEVICE=3380, OWFLW=DEPTOVF
SEGM NAME=PART, BYTES-32
LCHILD NAME=(COMP ASSEMB, DB3), PAIR=ASSEMB_COMP
FIELD NAME=(PS, SEQ), BYTES-5, START=1
FIELD NAME=PD, BYTES=25, START=6
FIELD NAME=CL, BYTES=2, START=31
SEGM NAME= ASSEMB_COMP, BYTES=10
POINTER=(LPART, TWIN, LTWIN)
PARENT(PART), SOURCE(PART, PHISICAL, DB3)
FIELD NAME=(PS, SEQ), BYTES=5, START-1
FIELD NAME=OTY, BYTES=5, START=6
SEGM NAME= COMP_ASSEMB, BVTES=10
POI NTER=RAI DER
FIELD NAME=(PS, SEQ), BYTES=5, START=1
PARENT PART, SOURCE(ASSEMB COMP, DB3)
FIELD NAME=(PS, SEQ), BYTES=5, START=1
FIELD NAME=OTV, BYTES=5, START=6
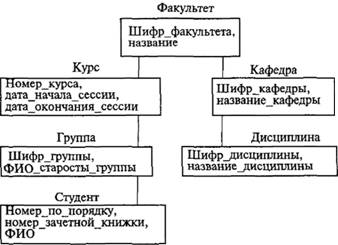
Рис. 6.9. Реализация иерархической БД
На внутреннем уровне древовидные структуры могут быть представлены различными способами. Например, отдельный экземпляр структуры, соответствующий схеме базы данных, можно определить как экземпляр записи файла. В этом случае иерархическая база данных на внутреннем уровне будет представлена одним экземпляром этого файла. Многие иерархические СУБД могут поддерживать несколько различных баз данных. В этом случае каждая БД на внутреннем уровне представляется одним файлом, который объединяет экземпляры записей одного типа со структурой, соответствующей схеме этой базы данных. На рис. 6.9 приведен пример схемы иерархической базы данных и ее возможной реализации на внутреннем уровне.
Создание иерархической БД (ЯОД)
Базовыми языками иерархической БД по-прежнему может быть COBOL, PL/1, Assembler.
Иллюстрацию ЯОД удобно вести на основе программы на языке СУБД IMS. Объявляются имена БД, сегмента и полей. Для одного из полей, по которому идет упорядочение, указывается метка SEQ и количество порожденных сегментов: один (U) или много (М). Отмечается исходный (PARENT) сегмент. Может присутствовать поле указателя (POINTER), метод доступа (HISAM).
Введение логических связей обозначается командой LCHILD, в которой указываются имена порожденного логического сегмента и сегмента БД, а в команде PARENT – исходные физический и логический сегменты БД.
Использование иерархической БД (ЯМД)
Обновление осуществляется командами REPLACE (заменить) и DELETE (удалить текущий сегмент и порожденные). Вставка (INSERT) может быть по отношению к текущему исходному сегменту (INSERT S) или по указанию (INSERT клиенты WHERE ГОРОД = 'СПб' and ИМЯ АГЕНТА='Святослав').
Помещение сегмента в область ввода-вывода осуществляется командой GET:
GET UNIQUE <имя сегмента>
WHERE <условие>,
GET NEXT,
GET NEXT WITHIN PARENT.
Из описания иерархической МД видно, что БД построить достаточно сложно. Здесь нет четкого разделения логической и физической структур. Набор структур запросов ограничен, а для неиерархических связей требуются дополнительные логические связи, превращающие фактически иерархическую МД в сетевую.