Количественные оценки релевантности
Формальные оценки релевантности можно получить только для релевантности первого рода, т.е. для релевантности в исходном ее понимании в теории информационного поиска.
Для введения критерия релевантности следует задать процедуру определения меры семантической близости поискового образа документа поисковому образу запроса и некоторое пороговое значение этой меры. Если мера превышает пороговое значение, то документ релевантен запросу.
ПОД и ПОЗ представляют собой множества ключевых слов или дескрипторов в зависимости от вида информационно-поискового языка. Для их сопоставления используют критерии смыслового соответствия, которые определяют на основе совпадения ключевых слов (дескрипторов) в ПОД и ПОЗ.
ПОД и ПОЗ можно представить в виде четких и нечетких множеств.
Для четких множеств вводят нормированную меру релевантности
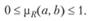
Критерий смыслового соответствия можно представить в виде
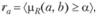
где μβ (а, b) – функция вычисления меры релевантности (или просто мера релевантности); α – пороговое значение релевантности, такое, что
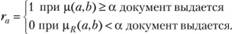
Изменяя пороговое значение а, можно организовать выдачу различных совокупностей документов, которую в теории информационного поиска называют эшелонированной выдачей. Каждый эшелон соответствует определенной мере семантической близости совокупности документов запросу.
Очевидно, что чем больше пороговое значение а, тем более жесткие условия налагаются на смысловую близость документа запросу. В нормированных мерах при α = 1 для выдачи документа требуется полное совпадение ПОД и ПОЗ.
Оценку релевантности можно характеризовать полнотой выдачи (или потерями), т.е. числом невыданных релевантных документов, и точностью (или шумом), т.е. числом или процентом "лишних" документов, которые выданы в результате поиска, но не являются релевантными.
Например, в [24] оценки полноты R и точности Т вводятся следующим образом:
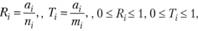
где ai – число релевантных документов, формально выданных системой на i-й запрос; mi – число всех формально выданных на i-запрос системой документов; и,• – число всех релевантных документов, соответствующих запросу.
При этом рекомендуется полноту и точность определять на основе нескольких поисков N по запросу, определять их средние значения и суммарные относительные оценки:
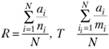 = средние относительные оценки;
= средние относительные оценки;
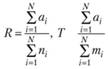 –суммарные относительные оценки, где N – число поисков.
–суммарные относительные оценки, где N – число поисков.
Величины (1-7) и (I – R) называются соответственно шумом и потерями.
В работах А. И. Михайлова, А. И. Чёрного и Р. С. Гиляревского [14, с. 306] предлагается наглядная матрица для определения полноты и потерь, точности и шума (табл. 6.5).
Таблица 6.5
Матрица для определения критериев релевантности
|
Релевантны |
Нерелевантны |
|||
|
А1 |
а2 |
|||
|
Выдано |
В1 |
а |
b |
a + b |
|
Не выдано |
В2 |
с |
d |
c+d |
|
а + с |
b + d |
a+b+c+d |
||
Полноту поиска измеряют отношением числа выданных релевантных документов (а) к общему числу релевантных документов массива (а + с):
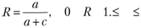
Точность поиска Г – отношение числа выданных релевантных документов (а) к числу общему выданных документов (а + b):
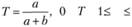
Соответственно, потери L и шум S можно представить следующим образом: 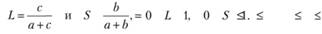
В [24] предлагается, проведя серию экспериментов п по определению полноты и точности поиска, определить среднюю полноту и среднюю точность:
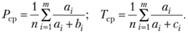
Используются и иные способы усреднения (см., например, в [14, 24]). Например, в связи с оценкой системы СМАРТ Сэлтон [1] ввел нормированную полноту RN и нормированную точность PN:
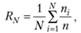
где N – число документов в массиве; п – число всех релевантных документов в массиве; ni – число релевантных документов, выданных до i-го ранга включительно;
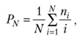
где i – номер ранга.
В [14] предлагается также, пользуясь табл. 5.4, ввести (с определенной степенью приближения) показатели в терминах теории вероятностей:
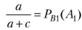 – условная вероятность выдачи релевантных документов;
– условная вероятность выдачи релевантных документов;
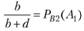 – условная вероятность выдачи нерелевантных документов;
– условная вероятность выдачи нерелевантных документов;
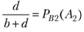 – условная вероятность невыдачи релевантных документов;
– условная вероятность невыдачи релевантных документов;
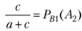 – условная вероятность невыдачи нерелевантных документов.
– условная вероятность невыдачи нерелевантных документов.
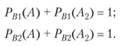
Предлагались и другие способы оценки релевантности (см. обзор в [14]).
Например, со способами применения для оценки релевантности нечетких множеств можно познакомиться в работе Г. Ю. Максимовича, А. Г. Романенко, О . Ф. Самойлюк [2]
К числу показателей функциональной эффективности названные авторы предлагают относить также оперативность поиска; специфичность поиска С – отношение числа невыданных нерелевантных документов (d) к общему числу нерелевантных документов (d + b), где b – число выданных нерелевантных документов:
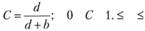
С учетом того, что на практике при оценке ИПС с большими массивами информации точные измерения числа релевантных и нерелевантных документов в общем массиве или в массивах выданных документов затруднено, предлагают использовать энтропийные показатели.
Энтропийные меры могут быть получены на основе исследования выборки из информационного массива, т.е. могут использоваться вероятностные меры неопределенности исходного массива р0, массива выданных р1 и массива невыданных р2 документов, вычисленные на их основе #0, НB, Ннв и соответствующие меры W.
В частности, предлагается интегральный энтропийный показатель как мера упорядоченности поискового массива документов, являющаяся результатом процесса поиска по заданному запросу:
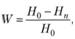
где Н0 – допоисковая (априорная) энтропия; Нп – послепоисковая (апостериорная) энтропия.
При этом для измерения априорной и апостериорной энтропии предлагается использовать меры концентрации релевантных документов в общем массиве, в массиве выданных документов и в массиве невыданных документов, в относительных единицах:
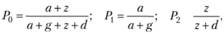
где а – число релевантных документов, выданных в результате поиска; г – число релевантных, не выданных в результате поиска; g – число нерелевантных документов, выданных в результате поиска; d – число нерелевантных документов, невыданных в результате поиска.
Энтропийная мера может быть представлена и в логарифмической форме.
Например, для оценки энтропии используются натуральная логарифмическая мера (т.е. неопределенность измеряется в неперах Нп):
– неопределенность исходного массива;
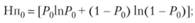
– неопределенность массива выданных документов:
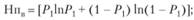
– неопределенность массива невыданных документов:
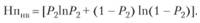
При формировании подобных мер могут быть использованы и иные логарифмические шкалы: двоичные логарифмы (биты), восьмеричные логарифмы (байты), десятичные логарифмы.
Определение полноты системы связано с определением содержательной выдачи на каждый запрос.
Существует несколько способов (методов) определения этой выдачи:
• сплошной просмотр всего экспериментального массива. Достоинством этого способа является надежность, недостатком – трудоемкость;
• метод документа-источника ("метод Клевердона"). Состоит в том, что по некоторым документам массива, выбранным более или менее случайно, составляются запросы с таким расчетом, чтобы каждый документ-источник был релевантен составленному по нему запросу;
• метод контрольных документов. По запросу, полученному по произвольно выбранному документу-источнику, проводится содержательный поиск путем сплошного просмотра массива, начиная, например, с документа-источника, до нахождения первого релевантного документа, который объявляется контрольным. Значение полноты для системы считается теперь как доля запросов, по которым система выдала контрольный документ в общем количестве запросов;
• метод объединения формальных выдач. Применяется при сравнении нескольких поисковых систем ("оценка-шкала"), Он состоит в том, что по каждому запросу эксперт просматривает только те документы, которые выдавались хотя бы одной из этих поисковых систем. Содержательной выдачей считается совокупность обнаруженных релевантных документов, и относительно нее определяется полнота, которая отличается от истинной полноты каждой из рассматриваемых систем.
Вопрос о представительности массива документов и массива запросов, выбранных для определения формальных оценок, в общем виде не решен. Считается, что более или менее устойчивые оценки (колебания не превышают 5%) можно получить на массиве в 4000 документов, массив запросов при этом должен быть порядка нескольких сотен.
Таким образом, релевантность (формальная) характеризует свойства средств логико-семантического аппарата информационно-поисковой системы и зависит от возможности отображения ПОД и ПОЗ с помощью информационнопоискового языка, принятых в ИПС алгоритмов поиска и системы индексирования.