Инструментальные средства построения физической модели базы данных
Построение физической модели базы данных в ее представлении уровня даталогического и физического моделирования может реализовываться как отдельно от логического построения модели, так и совместно с ним. Это позволяет разграничить уровни разработчиков либо обеспечить параллельное моделирование с одновременной синхронизацией моделей разных уровней. Однозначного решения о том, как правильно проводить моделирование: раздельно по уровням или параллельно, — не существует, но практика реализации сложных проектов показывает, что параллельное моделирование существенно усложняет процесс разработки, требующий регулярного возврата к предыдущим этапам анализа и моделирования, что приводит к необходимости разработчику самостоятельно отслеживать корректность внесенных изменений в логическую и физическую модели.
Раздельное моделирование, когда сначала строится логическая модель, а потом на ее основе формируется физическое представление модели, является, особенно для больших проектов, наиболее предпочтительным вариантом, поскольку дает возможность сначала детально проработать все механизмы представления данных и их взаимодействия, а потом, учитывая особенности работы с данными в конкретной СУБД, определить элементы физического уровня. Этот подход, учитывая необходимость последующей трансформации логической модели в физическую с переименованием объектов с национального алфавита в латиницу, зачастую реализуется разработчиками в рамках применения единых требований к логическому и физическому уровням представления моделей базы данных, т.е. использования в именах объектов на всех уровнях единых требований (соглашение имен)
и общего алфавита (латиница). Это существенно снижает возможности взаимодействия на уровне моделей с заказчиком, но упрощает процедуры перехода между уровнями представления моделей у разработчиков.
Инструментальное средство СА ERWin Data Modeler
Выполнение физического моделирования, основанное на ранее сформированной логической модели базы данных, производится на модели, получаемой после соответствующей трансформации. Как и в любом другом средстве моделирования, ERWin Data Modeler сохраняет все наименования в исходном варианте, как это представлено в логической модели базы данных, но заменяет пробелы и специальные символы на определенный в правилах трансформации символ. Обычно таким символом является "_" (знак подчеркивания).
Дополнительно к стандартному переименованию, инструментальное средство производит изменение заявленных в логической модели типов данных по атрибутам, формируя идентичный по свойствам тип данных, который определен в выбранной при трансформации СУБД, сохраняя размерности и описания соответствующего типа данных.
В итоге, после трансформации (рис. 5.4) разработчику необходимо правильно, в соответствии с соглашением имен, представить наименования всех объектов новой модели базы данных, включая таблицы и ноля (колонки). Осуществление процесса переименования реализуется через диалоговые окна описания таблиц и полей (колонок), аналогично процессу при формировании логической модели базы данных.
|
Рис. 5.4. Результирующая модель после трансформации в физическую модель |

Предположим, что разработчиком определено соглашение имен, как в предыдущем разделе. При выполнении процедуры переименования у разработчика в рассматриваемом примере модели возникает противоречие, которое заключается в том, что в таблице "епМу2" будет образовано два поля с одинаковым наименованием "16", что недопустимо по правилам именования объектов базы данных (рис. 5.5).
|
Рис. 5.5. Модель базы данных в соответствии с соглашением имен |

Для разрешения этого противоречия, учитывая абстрактность рассматриваемой модели, присвоим таблицам порядковые номера, отразив их значения также в нолях первичных ключей. Это изменение в правилах именования обязательно необходимо отразить в таблице соглашения имен (табл. 5.3).
|
Таблица 53 Корректировка таблицы соглашения имен
|
Таким образом, теперь все суррогатные первичные ключи будут иметь уникальные наименования, соответствующие номерам таблиц в модели, и приведение имен объектов к правильному виду не вызовет рассматриваемого противоречия, позволив создать корректный внешний ключ в дочерней таблице.
Организуя физическую модель базы данных, обязательно необходимо проверить корректность сформированных типов данных, описывающих конкретные атрибуты. Изначально это можно увидеть на самой модели, определив соответствующие правила отображения модели (операция выполняется идентично представлению логической модели). В случае, когда разработчик обнаружил несоответствие типа данных, поскольку в СУБД типов данных определенного вида может быть больше, чем представлено в списке стандартных типов данных уровня логической модели, важно корректно определить верный тип данных для каждого поля (рис. 5.6).
Определяя размерности первичных ключей, ранее было выявлено, что поле "id 1" будет через пять лет содержать максимальное значение 18 750, а ноле "id2" — 3100. Поскольку для этих полей был определен тип "Integer", который в качестве максимального значения диапазона имеет число 32 767, что значительно больше рассчитанного значения для обоих первичных ключей, а типа данных меньшей размерности, который позволил бы хранить рассчитанные значения, не существует, то этот тип данных можно сохранить для физической модели и ее реализации в физической базе данных.
|
Рис. 5.6. Настройка базовых свойств поля таблицы |

Если же максимально возможное значение первичного ключа будет больше диапазона, определенного для него типа данных, то его необходимо скорректировать в свойствах поля. Также необходимо исправить тип данных для поля в разделе выбранной СУБД, чтобы при синхронизации были правильно сформированы команды обновления структуры базы данных.
Выполняя настройку полей в соответствии с выбранной базой данных (рис. 5.7), разработчик может указать не только тип данных поля, но и ряд дополнительных характеристик, которые применяются в базе данных:
• Generated (Генерируемый) — свойство определяет возможность заполнения поля сгенерированным значения в соответствии с математическими или лингвистическими правилами;
• Generation Expression (Вычисляемое выражение) — свойство представляет математическое или лингвистическое выражение, выполнение которого должно привести к формированию некоторого значения, причем значения полей для выражения должны использоваться только из того же экземпляра той же таблицы;
• Generated Identity (Идентифицирующее вычисление) — свойство определяет признак необходимости формировать значение уникального характера, что обычно обеспечивается вычислениями по правилу арифметической прогрессии и, как правило, применяется для суррогатных ключей;
• Starting Value (Начальное значение) — свойство определяет значение, от которого будет отталкиваться СУБД при вычислении значения по правилам арифметической прогрессии;
• Increment By (Шаг) — свойство определяет значение, которое должно использоваться при очередном вычислении по правилам арифметической прогрессии.
Также для определения более точных характеристик поля (колонки) разработчику предоставляется возможность указать прочие свойства. Однако нужно помнить, что, в зависимости от выбранной СУБД, перечень свойств, которые можно определить для поля (колонки), может отличаться.
|
Рис. 5.7. Настройка свойств поля по выбранной СУБД |

Выполнив все операции по приведению физической модели базы данных к виду для последующей реализации в базе данных, можно приступать к уточнению и расширению возможностей будущей базы данных, учитывая особенности хранения данных и их обработки. Одним из таких действий является определение табличных пространств и распределение, но ним имеющихся в модели таблиц.
Объект "Табличное пространство" (рис. 5.8), являясь исключительно объектом базы данных, может отсутствовать в описаниях физической модели, если в качестве СУБД выбрана такая, где этот объект не присутствует. Тем не менее, если распределение таблиц по табличным пространствам возможен, то это желательно сделать, особенно если разрабатывается сложная информационная система. Создание табличного пространства выполняется через пункт меню "Model/Target.../Tablespeces..." (Модель/ Назначение.../Табличные пространства). В зависимости от выбранной СУБД пункт меню "Target..." будет изменяться названием этой СУБД. Также создать табличное пространство можно через контекстного меню дерева модели в левой области рабочего пространства.
|
Рис. 5.8. Область описания основных свойств табличного пространства |

Создав новое табличное пространство, необходимо определить основные его характеристики:
• Туре (Тип) — характеристика определяет правила работы СУБД с табличным пространством и выделяет пять основных типов:
— Regular (Базовое) — в этом табличном пространстве определяются все таблицы базы данных, исключая данные больших размеров, которые описываются типами Text, CLOB, BLOB, Binary и т.д.;
— Large (Большое) — табличное пространство ориентировано на размещение больших данных из соответствующих атрибутов;
- System Temporary (Системное временное) — используется для хранения временных сведений о базе данных и ее объектах, что определяет его как недоступное для пользователя;
- User Temporary (Пользовательское временное) — используется для хранения временных таблиц, формируемых в результате работы пользователя с представлениями, хранимыми процедурами и т.д.;
- Index (Индексное) — табличное пространство ориентировано на хранение индексных таблиц, используемых при контроле уникальности значений, поиске данных и сортировке;
• Managed By Туре (Тип управления) — свойство определяет правила, по которым в СУБД будет контролироваться расходование ресурсов компьютера и операционной системы, предполагая следующие варианты:
— System (Система) — управление ресурсами передается на уровень операционной системы;
- Database (База данных) — управлением будет руководить СУБД;
— Automatic Storage (Автоматическое хранилище) — управление ресурсами будет обеспечиваться тем методом, который, по мнению СУБД, будет являться наиболее предпочтительным.
Эти базовые свойства формируют основные параметры табличного пространства и при синхронизации указывают обязательные характеристики команды создания табличного пространства в базе данных. Дополнительно по табличным пространствам нужно определить их размерность, а точнее, правила разделения области табличного пространства на отдельные блоки.
Реализация процессов управления табличным пространством основывается на распределении таблиц по экстентам и страницам, что должно быть определено в дополнении к основным настройкам (рис. 5.9). Таким образом, в основной закладке "General" дополнительных настроек табличного пространства разработчику предлагается указать размер страницы (Page Size), выбрав в списке один из четырех вариантов размерности, величину экстента (Extent Size), измеряемого в количестве страниц, и прочие характеристики, определяющие особенности физического размещения таблиц и данных в табличном пространстве.
Также разработчиком определяются правила управления размером табличного пространства, если объем данных будет превышать ранее установленные для него параметры. Здесь предлагается указать ряд свойств:
• Use Auto Resize (Использовать автоматическое изменение размера) — определяется необходимость увеличения размера табличного пространства и файла базы данных;
• Initial Size (Начальный размер) указание размера табличного пространства, которое должно быть обозначено в момент создания базы данных;
• Increase Size By (Тип изменения размера) — указывают вариант расчета для изменения размера табличного пространства, предполагая точное количественное выражение и процентное вычисление;
• Increase Size (Шаг изменения размера) — указывается количественная величина, на которую изменяется размер табличного пространства при его увеличении;
• Max Size (Максимальный размер) — определяется величина максимального размера табличного пространства, больше которого оно не должно увеличиваться.
|
|

Puc. 5.9. Определение правил управления табличным пространством
В результате указания данных параметров и на основании определенного принципа управления табличным пространством оно будет размещать закрепленные в нем таблицы и их данные (рис. 5.10).
Выбирая свойства таблицы в отдельной закладке "Tablespace" (Табличное пространство), можно выбрать табличные пространства, где должны быть размещены данные из рассматриваемой таблицы, а также указать в свойстве "Index In Tablespace" (Индексы в табличном пространстве) то табличное пространство, как правило, это отдельное табличное пространство обычного типа (Regular), где должны храниться и распределяться сведения об индексации ключей и отдельных совокупностей атрибутов, формируя соответствующие индексные таблицы. Указав это размещение, в физической модели базы данных определяют правила физического распределения таблиц, индексов и больших данных, организуя эффективное управление данными на физическом (техническом) уровне, поскольку эти настройки используются именно для организации работы с файлом (-ами) базы данных на магнитном носителе.
|
Рис. 5.10. Закрепление таблицы в табличное пространство |

Определив параметры физической организации базы данных, можно переходить к ее логической организации, заключающейся в настройках, с учетом выбранной СУБД, параметров полей (колонок), ограничений, процедур и т.д. Одним из таких объектов, которые необходимо определить, являются умолчания. Выбрав определенную СУБД, инструментальным средством заранее можно будет определить предустановленные в СУБД умолчания (рис. 5.11), которые можно использовать в других объектах, например, при установлении проверочных ограничений.
|
Рис. 5.11. Список предустановленных умолчаний |

К таким умолчаниям, как правило, относятся значения текущей даты и времени, пустые значения в разрезе отдельных типов данных, имя сессии подключенного к базе данных пользователя, имя подключенного пользователя и т.д.
Создание нового умолчания выполняют аналогично процессу для логической модели базы данных, вызвав через контекстное меню закладки "Default Values" (Значение умолчания) в дереве проектов диалоговое окно, где необходимо указать наименование умолчания, которое будет использоваться в базе данных в качестве уникального имени объекта, и значение, которое должно присваиваться полям и использоваться в ограничениях.
Говоря об умолчаниях физической модели базы данных, с учетом выбранной СУБД, их применение реализуют при определении значения, автоматически устанавливаемого для полей, а также, ввиду их описания в качестве переменных базы данных, можно использовать при определении ограничений, имея в вычислительных и проверочных (логических) выражениях. Эта особенность позволяет разработчику определить большое количество стандартных значений, которые в базе данных могут быть использованы для эффективной и стандартизированной обработки данных в различных вариантах применения: заполнение полей, вычисление значений, проверка корректности значений, выполнение процедур обработки и выборки.
Следующим элементом физической модели базы данных, который необходимо уточнить и точно определить, является ограничение ссылочной целостности, определяемое через указание действий, которые необходимо выполнять при наступлении действия обработки (добавление, изменение, удаление) данных в родительской или дочерней таблице. Настройку ограничений ссылочной целостности выполняют в настройках связи между таблицами (рис. 5.12), используя закладку "RI Actions".
Для каждого варианта действия над данными инструментальное средство предлагает полный набор операций, которые были рассмотрены при описания логической модели базы данных. Конечно, нужно понимать, что различные СУБД обладают разным набором возможных операций ограничений ссылочной целостности, но данное инструментальное средство рассматривает эти операции не столько в качестве стандартных механизмов, сколько потенциальным правилом для написания программного кода триггера, выполнение которого также администрируется в СУБД.
Для физической базы данных в большинстве СУБД существуют определения для стандартных операций ограничения ссылочной целостности по следующим действиям над данными:
— добавление новой записи в дочернюю таблицу, понимая, что в ней имеется хотя бы один внешний ключ, значение которого необходимо контролировать в части наличия такого же значения в первичном ключе родительской таблицы;
- изменение значения первичного ключа родительской таблицы, поскольку в дочерней таблице есть связанное с ним точно совпадающее значение и бесконтрольное изменение может привести к нарушению целостности данных;
- удаление записи в родительской таблице, учитывая, что в дочерних таблицах могут присутствовать связанные записи и отсутствие ограничения ссылочной целостности может привести к невозможности получения доступа к связанным данным дочерней таблицы. * 3
|
Рис. 5.12. Настройка ограничений ссылочной целостности |

Все остальные действия, как правило, рассматриваются в СУБД на уровне программно реализованного триггерного действия, код которого инструментальным средством, как правило, определяется автоматически, но может быть представлен и программным кодом, определенным разработчиком (рис. 5.13). Для создания собственного триггерного действия достаточно через контекстное меню папки "Triggers" (Триггеры) дерева проекта создать его и перейти к его редактированию.
|
|

Puc. 5.13. Выбор для редактирования триггерного действия
Триггерное действие, хотя оно влияет на связи между ключами, определяется для таблицы, поскольку вызывается через выполнение действия над данными в таблице (рис. 5.14). Поэтому создавать его необходимо в папке дерева проектов, размещенной в рамках конкретной таблицы.
|
Рис. 5.14. Определение основных параметров триггера |

Поскольку триггерное действие выполняется при наступлении события по модификации данных, то среди основных характеристик, которые для него нужно определить, является указание действия над данными, которые должны этот триггер вызвать, что в области основных параметров отражено флажками по колонкам "Insert", "Update", "Delete". При этом необходимо указать время выполнения триггерного действия: "After" (после выполнения действия над данными) или "Before" (до выполнения действия над данными). В дополнение к основным характеристикам разработчиками указываются правила доступа к данным, действия над которыми привели к выполнению этого триггера.
Настройка базовых параметров выполняется в закладке "General", где можно определить доступность к модифицируемым данным (рис. 5.15):
• Scope (Область) — правило доступности к модифицируемым данным, где указывается уровень строки данных (Row) или таблицы с множеством строк (Table);
• New (Новый) — наименование временной области данных, представляемых единственной строкой данных, сформированной по результатам выполнения операции над данными;
• Old (Старый) — наименование временной области данных, представляемых единственной строкой данных, содержащей сведения до выполнения операции над данными;
• New Table (Новая таблица) — наименование временной таблицы с множеством строк данных, получаемых после выполнения операции над данными;
• Old Table (Старая таблица) — наименование временной таблицы с множеством строк данных, получаемых до выполнения операции над данными;
• When Clause (Условие выполнения) — указание логического выражения с применением правил языка программирования СУБД, определяющее дополнительные условия выполнения триггерного действия.
Наличие дополнительных условий выполнения триггерного действия дает возможность существенно ограничить необходимость применения триггера. Это необходимо делать по той причине, что триггерное действие,
выполняемое в автоматическом режиме, не может быть доступно без специальных режимов доступа для его остановки или какого-либо управления. Этот неконтролируемый запуск триггерных действий может привести к существенному снижению скорости работы базы данных, а зачастую и к ее полной неработоспособности.
|
Puc. 5.15. Указание базовых настроек триггера |

Когда триггерное действие определяется на изменение (Update) данных таблицы, то можно еще указать поля (колонки), действия над которыми будут инициировать триггер, что может быть определено в закладке "Update Columns" (Изменяемые колонки) настроек триггера (рис. 5.16).
|
|

Puc. 5.16. Определение колонок
для инициирования триггера
В перечень доступных для выбора колонок попадают все поля (колонки) таблицы, но, в данном случае, наиболее интересны колонки, которые
нс относятся к первичным ключам. Правда, иногда необходимо определить действие, если корректируется значение одного из атрибутов сцепленного первичного ключа. По всем остальным колонкам может быть необходимо выполнение триггерного действия. Наиболее часто такие триггерные действия определяются для полей (колонок), которые не являются ключевыми и требуют изменения данных в других таблицах.
Например, при разделении в разные таблицы сведений о цене товара и его количестве, чтобы вычислить стоимость заказываемого товара, нужно обратиться к двум таблицам, что невозможно, если применяется метод автоматического вычисления значения поля (колонки) по математическому выражению. Здесь на помощь может прийти триггерное действие, которое, при изменении, например, цены товара, запустит процесс вычисления новой стоимости товара и внесет эти сведения в соответствующее поле (колонку) другой таблицы.
Такое применение триггерного действия избавляет разработчика от написания в процедуре или приложении дополнительного действия по пересчету стоимости товара, перекладывая эту функцию на процесс автоматического выполнения операций.
В результате определения этих параметров будет сформирован код триггера, но он не будет содержать непосредственно операций по действиям, которые необходимо выполнить. Для этого, используя специальный макроязык инструментального средства (рис. 5.17), в закладке "Сос1с" (программный код) настроек триггера разработчик может сформировать нужные команды и их последовательность. Написанный на макроязыке программный код позволяет с минимальными затратами переключаться от одной СУБД к другой, формируя настройки программного кода, независимого от СУБД.
|
Рис. 5.17. Настройка программного кода триггера на макроязыке |

Результатом написания этого программного кода будет являться, учитывая выбранную СУБД, программный код на языке этой СУБД (рис. 5.18), который можно посмотреть и скорректировать, используя ее особенности программирования, в закладке "Expanded" (расширенный).
|
Puc. 5.18. Программный код на языке СУБД |

Этот программный код будет, учитывая синтаксис и особенности программирования языка, применяемого в СУБД, с учетом существующих там конструкций, а при соответствующей корректировке, специальных процедур и функций, представленных только в этой выбранной СУБД.
Триггерные действия, являясь программными процедура, тем не менее используют не очень часто. Наиболее часто применяются хранимые процедуры (рис. 5.19), программным кодом которых можно управлять и получать доступ, включая запуск на выполнение. Создание хранимой процедуры выполняется через контекстное меню папки "Stored procedures" (Хранимые процедуры) дерева проектов.
Как и любая программная процедура или функция, хранимая процедура обладает базовыми обязательными характеристиками: наименование, входные параметры и выходящий результат. Перечень входных параметров для хранимой процедуры разработчик может назначить в рамках настроек в закладке "Parameter" (Параметр), где для каждого параметра указываются:
Parameter — наименование параметра, по которому нужно будет его использовать в программном коде процедуры;
• Туре — тип параметра, выбранный из двух вариантов (In — входящий, Out — выходящий);
• Physical Data Type — тип данных, которым описываются допустимые значения для параметра;
• Default — значение по умолчанию, которое должно быть присвоено параметру, если оно не определено пользователем при вызове процедуры.
|
Рис. 5.19. Основные настройки хранимой процедуры |

Указание этих характеристик для всех параметров хранимой процедуры сформирует заголовок процедуры, который задаст ключевые правила ее использования в СУБД.
В рамках закладки "General" настроек процедуры определяются основные параметры самой процедуры, которые позволят точно сформировать базовый программный код, формирующий результат выполнения процедуры и принципы построения программного кода (рис. 5.20). Это необходимо по той причине, что хранимые процедуры могут выступать в двух качествах:
— программный модуль модификации данных, когда выполняется множество действий по добавлению, изменению, удалению данных и применяются различные программные конструкции, такие как условия, циклы и курсоры, а также специфические функции, реализованные только для языка программирования выбранной СУБД;
— параметрическое представление, предполагающее выполнение единственной команды выборки с возвратом результата в виде множества таблично организованных данных, но, в отличие от классического представления, реализуемое на основе входных параметров.
|
Puc. 5.20. Настройки хранимой процедуры |

В рамках рассматриваемых базовых настроек хранимой процедуры наиболее важными являются две:
• Specific Name (Наименование) — имя процедуры, по которому она будет вызываться для выполнения обработки данных;
• SQL Data Access (Доступ к данным SQL) — тип выполняемой процедуры с вариантами обработки данных (Modifies SQL Data) и выборки данных (Reads SQL Data).
Помимо основных настроек, предполагающих применение стандартного языка SQL, инструментальным средством предоставляется возможность определить некоторые дополнительные настройки (рис. 5.21), которые указываются в закладке "Other Options" (Прочие настройки). Важными настройками являются:
— Language (Язык) — язык программирования, на базе которого будет сформирован программный код хранимой процедуры;
- Coded Character Set Identifier (Кодировка символов) — использование определенной кодировки символьных данных, которые будут записываться в символьные переменные и параметры, что особенно важно при использовании базы данных в интернет-приложении, где кодировка данных определяется в интернет-странице;
Commit Transaction On Return (Завершать транзакцию при возврате) — хранимая процедура, по своей сути, является единой транзакцией, т.е. выполняемой полностью или не выполняемой вообще, что требует фиксирования результата выполнения указанных в процедуре команд.
|
Рис. 5.21. Прочие настройки хранимой процедуры |

В итоге указания всех первоначальных параметров хранимой процедуры будет, как и в случае с триггером, сформирован программный код на макроязыке инструментального средства (рис. 5.22).
В целях универсализации программного кода применение макроязыка для хранимых процедур является очень полезной составляющей инструментального средства, давая возможность быстро переключаться между разными СУБД и создавать базы данных, одинаково функционирующих в разных СУБД. Конечно, создавая на макроязыке программный код, в него можно включать стандартные операции на языке SQL или другом языке, который специфицирован для написания хранимой процедуры, а также специфические функции и процедуры, определенные только для выбранного языка СУБД. Однако в этом случае, когда используются явные ука-

зания на функции, процедуры и конструкции языка СУБД, нужно быть готовым к тому, что преобразованный программный код при смене СУБД не будет функционально работающим и его придется исправлять, учитывая особенности другой СУБД, для которой модель базы данных необходимо переформировать. Это существенно снижает возможности быстрой и мало затратной смены СУБД и создает менее гибкую модель базы данных.

В результате полного описания программного кода в закладке "Expanded" будет отображен программный код, сформированный на основе указанного для процедуры языка программирования СУБД (рис. 5.23). Этот программный код можно скорректировать, учитывая особенности применения отдельных функций СУБД, но предполагается, что разработчик, с целью универсализации модели, все необходимые указания сделал в рамках программного кода, написанного на макроязыке инструментального средства.
Puc. 5.23. Результат хранимой процедуры
на языке СУБД
Чтобы сменить СУБД, для которой реализуется модель базы данных, достаточно в меню "Actions/Target Database..." (Дсйствия/База данных назначения...) вызвать соответствующее диалоговое окно, где указать нужную СУБД и ее версию (рис. 5.24).
|
Puc. 5.24. Изменение выбора СУБД |

Инструментальное средство IBM InfoSphere Data Architect
Применяя инструментальные средства для моделирования физической модели базы данных, разработчик ставит перед собой задачу не только построить модель и трансформировать ее в физическую базу данных, но и иметь возможность управлять этой базой данных с помощью имеющейся модели. Инструментальное средство от IBM, рассматривая разработку информационной системы как единый неделимый процесс, поддерживающий все этапы жизненного цикла, реализует множество функций в рамках единого средства, как, например, в IBM InfoSphere Data Architect реализуются этапы логического и физического моделирования, а также управление базой данных в части программирования и структурирования объектов базы данных непосредственно из самого инструментального средства, учитывая описания физической модели базы данных.
Именно с учетом этих особенностей применения инструментальных средств разработка физической модели является одной из важнейших задач, которую необходимо выполнить максимально качественно и полно, затрагивая не только и не столько описания таблиц и полей (колонок), но и всех остальных составляющих: представления, хранимые процедуры, функции и триггеры. Используя принципы перехода к физической модели базы данных, разработчики, по итогам трансформации логической модели в физическую и формирования таблицы соглашения имен, выстраивают физическую модель с определением всех необходимых свойств таблиц и полей (колонок), включая умолчания, ограничения значений, генерацию идентифицирующих значений для суррогатных ключей.
В процессе разработки моделей по примеру электронного магазина при переходе к физической модели базы данных была выбрана СУБД IBM DB2 (рис. 5.25). Особый интерес вызывает трансформация первичных ключей суррогатного типа, при которой был изменен тип данных. Например, в сущности "Заказы" первичный ключ "ИДФ заказа" был определен
типом "serial" и объявлен суррогатным ключом. Трансформация в таблицу "orders" сформированное поле "id_order" приобрело другой тип данных - Varchar(l) for bit data. Для выбранной СУБД это специальный тип данных, который представляется символьным типом, но с процедурой обработки как числового атрибута, предполагающего хранение числового значения, генерируемого по правилам арифметической прогрессии.
|
Рис. 5.25. Результат перехода к физической модели базы данных |

Важно отметить, что, при ранее установленном правиле не использовать символьные атрибуты в качестве первичных ключей, этот вариант вполне допустим, поскольку в СУБД реализованы специальные механизмы, ускоряющие процесс обработки данного символьного типа. При этом для такого атрибута устанавливаются специальные параметры (рис. 5.26).
|
Рис. 5.26. Настройка суррогатного первичного ключа |

Представленные настройки суррогатного первичного ключа указывают на необходимость использовать генерирование значения по правилам арифметической прогрессии, что обозначено флажком "Generated" (Генерируемое). Дополнительно, чтобы правило генерирования значения отрабатывалось в СУБД корректно, указываются прочие характеристики:
• Start — начальное значение, от которого СУБД оттолкнется при создании первой записи таблицы;
• Increment — шаг изменения значений ключа при добавлении очередной записи таблицы, вычисляемый, как привило, на основе специального объекта "Счетчик" (Sequence), хранящего текущее значение, которое необходимо изменять;
• Minimum — минимальное значение, которое может принимать поле (колонка) данного первичного ключа, где, в случае снятия флажка, условие не будет контролироваться;
• Maximum — максимальное значение, которое может принимать поле (колонка) первичного ключа, учитывая ранее сформированные условия заполнения значениями первичных ключей.
Если разработчиком определено, что значение поля (колонки) должно подчиняться не правилам арифметической прогрессии, а каким-либо другим вычислительным выражениям, то в свойстве "Expression" (Выражение) указывают это выражение, учитывая, что в него могут включаться вычислительные функции, константы и поля той таблицы в которой формируется выражение. Таким образом, используя эти свойства полей, можно настроить правила их заполнения.
Приведя модель базы данных к правилам использования имен объектов, условиям наполнения нолей значениями и ограничений на эти значения, как это предусмотрено процедурой разработки, переходим к формированию табличных пространств и размещению таблиц в этих табличных пространствах.
Для создания табличного пространства необходимо обратиться к дереву проекта, где отражают все объекты модели, разделяя их по группам (рис. 5.27);
— Diagrams — диаграммы модели базы данных с отображением таблиц и представлений;
— SQL Statement — программные модели обработки базы данных, включая функции и хранимые процедуры;
- Storage Diagrams — диаграммы храпения и размещения данных но табличным пространствам и контейнерам, определяющим физическое размещение данных на магнитном носителе;
— Schema — схема (роль) базы данных, группирующая множество объектов представления данных, включая таблицы, представления и триггеры.
|
Рис. 5.27. Дерево проекта физической модели базы данных |

Используют контекстное меню области "Storage Diagrams" (Диаграммы хранения), создают соответствующую диаграмму, где можно разместить необходимые табличные пространства (рис. 5.28), представляемые двумя типами: Regular — стандартное табличное пространство для использова-
ния с таблицами и индексами; Large — большое табличное пространство для хранения данных больших типов.
|
Рис. 5.28. Перенос таблиц в табличное пространство |

Создав диаграмму, на рабочем пространстве можно создать пустое табличное пространство и в закладке "Tables" (Таблицы) области свойств табличного пространства указать таблицы, индексы и таблицы с большими данными, которые должны быть размещены в нем (лис. 5.29).
|
Рис. 5.29. Результат создания табличного пространства с таблицами |

В результате па диаграмме и в дереве проекта будет представлено табличное пространство со списком закрепленных за ним таблиц. Однако недостаточно закрепить таблицы в табличное пространство. Нужно правильно настроить это табличное пространство, что делается в закладке "General" (Основное) области свойств табличного пространства.
Помимо наименования табличного пространства, разработчику необходимо определить правила управления хранением на магнитном носителе файла базы данных и возможности восстановления таблиц при их удалении (рис. 5.30). Как и в других инструментальных средствах, возможные настройки правил управления хранением определяются в соответствии с СУБД, что для IBM DB2 определяется вариантами: System, Database и Automatic Storage, — рассматривающими управление на уровнях операционной системы, СУБД или автоматического определения соответственно.
|
Рис. 530. Настройка основных свойств табличного пространства |

Настроив тип управления хранением, важно указать количественные характеристики размерности табличного пространства и изменений его размеров при полном заполнении данными. Эти характеристики определяются в закладке "Size" области свойств табличного пространства (рис. 5.31).
|
|

Puc. 531. Настройка размеров табличного пространства
Аналогично другим инструментальным средства для табличного пространства нужно определить размер страницы (Page size) и ее начальный размер (Initial size), указав единицу измерения (Кб, Мб, Гб). Также указывают размер экстента (Extent size), учитывая размерность страницы.
Указав, что для физического места табличного пространства необходимо автоматически изменять размер (Autoresize), если оно полностью заполнено данными, нужно дополнительно определить следующие параметры:
• Increase size — величина изменения размера с указанием принципа изменения (процентное или количественное);
• Maximum size — максимальный размер табличного пространства, указываемый в количественном объеме (Кб, Мб, Гб).
Таким образом, описав все табличные пространства, можно проверить корректность закрепления таблиц, особенно, если ранее таблицы не были размещены в табличные пространства. Для выполнения операции внесения таблицы в табличное пространство нс только определением свойств самого табличного пространства можно обратиться к свойствам таблицы, где в закладке "Tablespace" можно указать, каким образом нужно разместить данные таблицы.
Поскольку для таблиц, индексов и больших данных предполагается использование разных табличных пространств, то в свойствах таблицы разработчику предлагается выбрать, как размещать соответствующие элементы. Исходя из того, что стандартное табличное пространство используется для таблиц и индексов, в соответствующих нолях (Regular, Index) можно указать одно и тоже табличное пространство (рис. 5.32), по надо понимать, что скорость обработки при больших объемах данных может быть существенно снижена, чем при варианте разнесения таблиц и индексов по разным табличным пространствам.
|
Puc. 5.32. Закрепление таблицы в табличные пространства |

Когда же речь идет о больших данных, представляемых большими типами данных (Text, CLOB, BLOB, Binary и т.д.), то для хранения этих данных нужно использовать специальное табличное пространство (Large tablespace), которое, по умолчанию, настроено на эффективную работу с такими данными.
И наконец, остался последний набор свойств описания таблиц, определяющий правила управления хранением данных. Этот набор свойств размещается в закладке "Volumetries" (Измерители) области свойств таблицы (рис. 5.33). Важным является, в первую очередь, указание сведений о количестве записей, которые могут быть в таблице:
— Initial number of rows (начальное количество строк) — это свойство показывает, что при создании таблицы туда необходимо разместить какое-то количество записей;
Row growth per month (изменение строк в месяц) — это свойство определяет количество строк (записей), которое будет добавляться в таблицу в течение месяца, определяя степень изменчивости и увеличения размера таблицы;
Maximum number of rows (максимальное количество строк) — этим свойством ограничивается количество записей, которое может быть внесено в таблицу, обеспечивая ограничения на возможности добавления новых записей, что очень актуально для стандартных классификаторов, изменчивость которых стремится к нулю.
Второй областью измерителей является определение свойств изменения и размеров записей и индексных сведений. Поскольку индекс представляется такой же таблицей, как и обычные данные, то набор свойств для индексов идентичен свойствам таблицы. Инструментальное средство сразу указывает на средний размер одной записи и предлагает с помощью
|
свойства "Projected in month" прогнозируемый размер записи в течение месяца, учитывая, что некоторые поля (колонки) таблицы обладают типом динамического размера строки (varchar).
Puc. 533. Настройка измерителей таблицы |
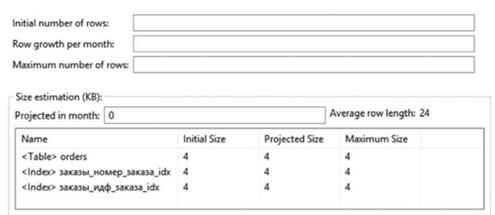
Аналогичные свойства указываются для таблицы в целом и индексов:
• Initial Size — базовый размер записи таблицы или соответствующего индекса;
• Projected Size — прогнозируемый размер;
• Maximum Size — максимальный размер.
Определившись с таблицами, полями (колонками) и табличными пространствами, разработчику необходимо установить корректные правила ссылочной целостности, но связям между таблицами (рис. 5.34), что выполняется через закладку "Referential Integrity" (ссылочная целостность) области свойств связи.
|
Рис. 534. Настройка ссылочной целостности |

Данное инструментальное средство, в отличие от многих других, ориентируется только на те правила ссылочной целостности, которые определены в выбранной СУБД, предоставляя возможность разработчику указать особенности контроля связи между таблицами только по двум действиям — изменению и удалению данных. В том числе, среди доступных действий, также существуют ограничения СУБД, которые воспроизводятся в инструментальном средстве. Например, для действия Update инструментально средство предлагает только три варианта контроля ссылочной целостности: No Action, Restrict и Cascade. Объясняется это тем, что данное средство моделирования реализует триггерные операции только по указанию разработчика и не формирует их в автоматическом режиме, как это, к примеру, предусмотрено в ERWin.
Таким образом, определив правила ссылочной целостности, разработчик должен задуматься о создании триггерных действий, которые не подчиняются базовым ограничениям. Создание триггеров реализуется через контекстное меню таблицы в дереве проекта.
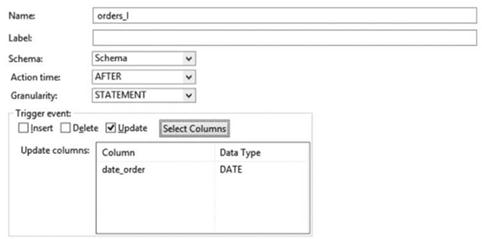
В базовых свойствах триггера (рис. 5.35), как и в других инструментальных средствах, определяются характеристики времени выполнения триггера и действие над данными, которое должно его инициировать. Так, разработчику предлагается указать:
— Name — наименование объекта триггера, чтобы к нему можно было обратиться через команды управления структурой базы данных;
— Schema — схему (роль), за которой закрепляется триггер, где, по умолчанию, определяется схема таблицы;
- Action time — время, когда должен выполниться триггер при его инициировании действием над данных, предлагая три варианта на выбор: after (после), before (до), instead of (вместо);
- Granularity — рассматриваемые области данных для использования в триггерных действиях: statement — для каждого элемента записи (поля, колонки), row — для всей записи целиком;
- Trigger event — события, инициирующие триггер, к которым относятся добавление (insert), изменение (update) и удаление (delete), где, если выбрано инициирующее действие в виде изменения данных, можно выбрать поля (колонки), изменение которых приведет к запуску триггера на выполнение.
|
Puc. 535. Определение базовых свойств триггера |
Переходя к следующему этапу описания триггера, разработчик должен определить условия программной логики и сам программный код. Настройка программного кода выполняется в закладке "Details" (Детали) области свойств триггера (рис. 5.36), где нужно определить уровень работы с данными:
• Temporary table names for transition tables — определение имен временных таблиц, где будут храниться данные до (Old) и после (New) выполнения операции, но модификации данных;
• Correlation names for transition rows — определение имен доступа к единственной модифицируемой записи данных, характеризуя данные до (Old) и после (New) выполнения операции по модификации данных.
|
Рис. 5/30. Область программирования триггера |

Важно понимать, что доступ к записи позволяет в программном коде обратиться непосредственно к полю записи, используя их имена. В случае, когда используется уровень временной таблицы, доступ к данным возможен через выполнение команд работы со множеством записей таблицы, включая команду выборки Select.
Далее разработчик указывает в поле "When" логическое выражение, которое будет проверяться перед выполнением триггера на факт целесообразности проведения записанных в нем операций. В поле "Action" разработчик указывает сам программный код на языке SQL, который необходимо выполнить при запуске триггера.
Еще одним объектом физической модели базы данных, который необходимо определить в ней, является представление, обозначаемое как стандартный запрос без использования параметров, предоставляемых пользователем, или параметрами, представленными константами. В основной закладке "General" указывается имя представления, чтобы при реализации других представлений, хранимых процедур, триггеров и приложений можно было к нему обратиться (рис. 5.37).
|
|

Рис. Ї.37. Результат создания представления
Реализация представления выполняется через контекстное меню дерева проектов, где в свойствах разработчик указывает команду выборки на языке
|
5()Ц используя закладку "5()Ь", на основании которой будут определены наборы полей (колонок), формируемых представлением (рис. 5.38).
Рис. 5.38. Выражение для представления |

Команда выборки данных, которая формирует представления, может быть достаточно разветвленной, использующей другие представления, множество связанных таблиц и подзапросы.
Последним объектом, формируемым в физической модели базы данных, является хранимая процедура (рис. 5.39), представляемая программным кодом на языке программирования, поддерживаемым в СУБД. Данное инструментальное средство, ориентируясь на СУБД, изначально предлагает формировать хранимую процедуру на том языке, который имеется в СУБД.
|
Рис. 5.39. Основные настройки хранимой процедуры |

Создав хранимую процедуру через контекстное меню в дереве проекта физической модели базы данных, в свойствах указывают имя процедуры для последующей возможности ее вызвать на выполнение и язык, на котором будет программироваться хранимая процедура. Следующим этаном создания хранимой процедуры является определение набора параметров (рис. 5.40), которые должны быть переданы в процедуры и использоваться в ее реализации, указывая не только наименование параметра, но также тип данных, которые будут передаваться, тип использования, выделяя входящие и выходящие параметры.
|
Рис. 5.40. Определение параметров хранимой процедуры |

Указанные параметры хранимой процедуры будут сформированы в определении программного кода и используются внутри процедуры при выполнении операций над данными, которые предполагают варианты модификации и выборки сведений.
Выбор варианта применения (рис. 5.41), а именно типа возвращаемого результата, осуществляется в закладке "Options" свойств хранимой процедуры, где:
Modifies SQL Data обозначает создание процедуры изменения данных в таблицах базы данных, предполагая использование всех возможностей языка программирования СУБД;
Reads SQL Data обозначает выборку данных из таблиц и представлений базы данных, используя параметры в качестве элементов логического ограничения выбираемых данных.
|
Рис. 5.41. Настройка вариантов использования хранимой процедуры |

При использовании варианта хранимой процедуры в качестве параметрического представления (Reads SQL Data) программный код реализуется в виде единственной команды выборки. Сам программный код формируется разработчиком в рамках закладки "Source" области свойств хранимой процедуры.
В итоге выполнения всех действий по формированию физической модели базы данных, учитывая особенности представления правил ссылочной целостности и методик моделирования программной обработки данных, будет подготовлена модель, синхронизация которой с базой данных позволит создать базу данных, не требующую дополнительных операций по ее настройке и структурированию.