Имитационные динамические модели
Логичным продолжением усилий ученых по улучшению прогнозных свойств математических моделей, используемых для прогнозирования экономики, стало научное направление, которое получило общее название "Имитационное моделирование". По большому счету любая прогнозная модель имитирует некую динамику реально существующего объекта, но под имитационными моделями стали понимать такие из них, которые описывают сложную систему причинно-следственных связей элементов и подсистем сложной системы. При этом все эти взаимосвязи являются результатом аналитического изучения объекта прогнозирования, а не статистического исследования имеющихся данных. На первом этапе изучается структура прогнозируемого объекта: его основные элементы и их характеристики, взаимосвязь и взаимозависимости между элементами, а уж потом эта структурная модель заполняется статистическим ОГЛАВЛЕНИЕм.
Исторически имитационные модели появились в науке с появлением доступных вычислительных машин, ведь предстояло математически описать и вычислять системы уравнений и неравенств, а вручную это делать (или же с помощью калькуляторов) не представляется возможным. Первые имитационные модели изначально разрабатывались специалистами, владеющими в первую очередь языками программирования и хорошо знакомыми с объектами моделирования.
В процессе построения таких моделей каждый ученый делал акцент на тех свойствах объекта, которые казались ему наиболее важными, опираясь на собственное понимание того, как протекают анализируемые процессы и как их можно описать. Поэтому первые имитационные модели напоминали не столько набор формальных правил и процедур, сколько полет творческой фантазии исследователей[1]. Кроме того, на заре становления вычислительной техники программные средства, которые были доступны исследователям, были весьма скудны, поэтому, разрабатывая и реализовывая имитационные динамические модели, ученые создавали специально ориентированные языки программирования, такие как DINAMO, SIMSCRIPT, SIMULA, GPSS и др. Наиболее успешным оказался язык GPSS, который, сохраняя свои базовые принципы, непрерывно модифицировался с момента своего создания (1961). Он широко используется и сегодня, тогда как, например, язык DINAMO представляет только исторический интерес.
Для того чтобы отличать имитационные модели социально-экономического развития от имитационных моделей другого уровня, их стали называть "Имитационные динамические модели" (ИДМ), подчеркивая, что динамика является важной, если не основной, характеристикой таких моделей. Имитационные динамические модели возникли из принципов системной динамики, впервые предложенной Дж. Форрестером[2].
Сегодня имитационное моделирование представляет собой развитую часть научного знания, используемого как на макроуровне, так и на мезо- и микроуровнях моделирования, и сведения о нем прогнозист может почерпнуть из множества доступных учебников. Поэтому в данном параграфе мы остановимся лишь на особенностях имитационного динамического программирования как инструмента выполнения многовариантного прогнозирования социально-экономической динамики любого уровня иерархии.
Прежде всего, обратимся к этапам построения ИДМ. Разные ученые выделяют различные этапы этой работы, тем не менее наиболее общей является Вперед последовательность действий.
1. Построение схемы когнитивной структуризации.
2. Подбор статистических данных и уточнение схемы.
3. Формирование математических моделей, описывающих когнитивные связи.
4. Компоновка ИДМ в целом.
5. Отладка модели.
6. Верификация модели.
7. Выполнение многовариантных расчетов, в том числе прогнозных.
По крайней мере, наш опыт построения ИДМ опирается именно на такую последовательность действий. Разберем эти этапы более тщательно.
1. Построение схемы когнитивной структуризации. Под этим процессом понимается построение и использование когнитивной карты для анализа структуры прогнозируемого объекта[3]. На этом этапе выявляется структура прогнозируемого объекта – его наиболее важные элементы и взаимосвязь между ними. Эта карта представляет собой процесс абстрагирования – отвлечения от второстепенных с позиций исследования факторов и условий и акцентирования внимания только на главных объектах. Четко устоявшихся правил построения таких схем нет, поскольку они представляют собой некоторое схематическое изображение элементов и подсистем моделируемого объекта и взаимосвязей между ними. Обычно элементы и подсистемы изображаются некоторой фигурой (овал, прямоугольник и т.п.). Если в изучаемом объекте имеются некоторые типичные элементы, для отличия их от других элементов одинаковые элементы обозначаются одинаковыми фигурами. Например, если в схеме взаимосвязей встречаются отдельные коллективы исполнителей, поведение которых в моделируемой системе рассматривается как типичное, этот элемент может быть обозначен одной и той же фигурой, например треугольником. А некоторый типичный технологический процесс, встречающийся на разных уровнях сложной системы моделируемого объекта, обозначается ромбом и т.п.
Поскольку элементы и подсистемы общей системы как объекта прогнозирования находятся во взаимосвязи друг с другом, эта взаимосвязь обозначается стрелочками – от причины к следствию. Иногда для большей конкретизации сути взаимосвязи возле стрелки ставят "плюс" (если увеличение причины ведет к увеличению следствия) или "минус" (если увеличение причины ведет к уменьшению следствия). Например, если увеличение оплаты труда ведет к увеличению его производительности, то в этом случае возле стрелки ставят знак "плюс". Если увеличение объема производства до номинальных значений ведет к уменьшению себестоимости изготовления единицы продукции, то на стрелке, изображающей эту взаимосвязь, ставят знак "минус".
Поскольку объектом социально-экономического прогнозирования выступают сложные динамические системы, в них имеется обратная связь, когда действие некоторой причины вызывает после прохождения этого действия через сложную цепочку взаимосвязей обратное воздействие на причину. Системы с обратной связью являются саморазвивающимися – имитационная динамическая модель также представляет собой систему с обратной связью, когда она при заданных внешних условиях способна к многоитеративному пересчету своих параметров и характеристик. Тем самым модель самостоятельно имитирует динамику экономического процесса.
Пример
Построим схему когнитивной структуризации работы российского государственного вуза.
Прежде всего, отметим, что важным показателем работы любого российского вуза является конкурс на одно бюджетное место со стороны поступающих – абитуриентов. Этот конкурс формируется на основании престижа вуза в глазах абитуриентов. Первым элементом системы будет элемент под названием "Престиж вуза" (рис. 12.7).
Чем выше престиж вуза, тем большее количество абитуриентов стремится попасть в него. Поэтому "Абитуриенты" является следующим элементом нашей системы, количественные характеристики которого прямо зависят от престижа вуза. Соединяем эти два элемента стрелкой.
Прием в вузы в наши дни осуществляется на основании результатов ЕГЭ. Если баллы, набранные абитуриентом, высоки, он проходит по конкурсу и зачисляется на бюджетные места. Если баллов недостаточно, он может поступить в вуз на внебюджетное место. Следовательно, соединяем элемент "Количество абитуриентов вуза" стрелкой с блоком принятия решений под названием "ЕГЭ", изображенным ромбом. Условие соответствия нижней планке ЕГЭ дает абитуриенту возможность стать студентом, обучающимся на бюджетном месте, поэтому из одного угла ромба выведем стрелку, в основании которой ставим слово "да". Из другого угла ромба выведем другую стрелку, означающую, что абитуриент не проходит по конкурсу и не может быть зачислен на бюджетное место. У основания этой стрелки ставим слово "нет".
Планка ЕГЭ определяется престижностью вуза. Поэтому от элемента "Престиж" проведем стрелку к элементу "ЕГЭ".
Информация о престижности вуза, конкурсе на одно место со стороны абитуриентов доводится до Министерства образования и науки РФ, которое и определяет количество бюджетных мест для данного вуза. Поэтому в схему необходимо поместить элемент под названием "Министерство". От элемента "Престиж" ведем стрелку в элемент "Министерство", а от элемента "Министерство" – стрелку в элемент с названием "Бюджетные места". В этот же элемент под названием "Бюджетные места" ведем стрелку от блока "ЕГЭ", которую в основании обозначили словом "да".
Итак, процесс попадания абитуриентов на бюджетные места нами описан и включен в схему когнитивной структуризации.
Что же происходит с теми абитуриентами, которые по конкурсу не прошли на бюджетные места? Вуз предлагает им учиться в вузе по контракту, объявляя ежегодную плату за обучение. Вводим тогда такой элемент схемы, который будет назван "Плата за обучение по контракту". Если семья абитуриента считает для себя возможным оплачивать учебу по этой цене, абитуриент становится студентом, если же размер платы не устраивает семью, то абитуриент не поступает в вуз.
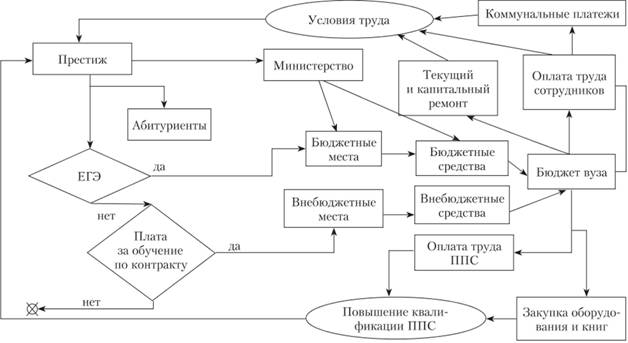
Рис. 12.7. Схема когнитивной структуризации модели работы вуза
Поэтому элемент "Плата за обучение по контракту" на схеме обозначена ромбом с двумя выходящими из него стрелками со словами "да" и "нет".
Стрелка со словом "да" логично связана с элементом под названием "Внебюджетные места". Стрелка со словом "нет" указывает на выход из цикла.
Приняв студентов на бюджетные места, вуз получает из министерства финансирование на их обучение. Поэтому из элемента "Бюджетные места" ведем стрелку в элемент под названием "Бюджетные средства". К этому элементу ведем и стрелку из элемента "Министерство", обозначая тем самым факт выделения им денег вузу.
Очевидно, что из элемента "Внебюджетные места" также следует вести стрелку в элемент под названием "Внебюджетные средства". Бюджетные и внебюджетные средства составляют единый бюджет вуза. Поэтому ведем две стрелки от каждого из этих элементов в элемент под названием "Бюджет вуза".
Структура затрат вуза разнообразна, но мы выделим основные затраты:
1. "Текущий и капитальный ремонт".
2. "Коммунальные платежи".
3. "Оплата труда сотрудников".
4. "Оплата труда ППС (профессорско-преподавательского состава)".
5. "Закупка оборудования и книг".
Назначение этих затрат различное, но можно утверждать, что первые три вида расходов способствуют формированию "Условий труда и обучения", а последние два вида расходов бюджета вуза способствуют "Повышению квалификации ППС". Проведем соответствующие стрелочки, соединяющие элементы расходов бюджета с этими двумя элементами. Очевидно, что и условия труда и обучения, и повышение квалификации ППС способствуют росту престижа вуза, и способствуют этому по-разному. Поэтому соединим элементы "Повышение квалификации ППС" и "Условия труда и обучения" с элементом "Престиж". Получилась система с обратной связью и в целом схема когнитивной структуризации построена. Теперь можно перейти к следующему этапу построения ИДМ.
2. Подбор статистических данных и уточнение схемы. После того как построена схема когнитивной структуризации, становится понятным, какие элементы должны войти в ИДМ и с какими другими элементами и подсистемами объекта моделирования они связаны. По каждому из элементов и по каждой из взаимосвязей необходимо получить информацию об их количественных характеристиках. Несмотря на кажущуюся простоту этого этапа, он связан с существенными трудностями.
Прежде всего, следует указать на то, что этот этап весьма трудоемкий – чаще всего в распоряжении прогнозиста нет всей необходимой информации и он должен ее собрать и обработать.
Вторая трудность является менее преодолимой – практически каждый раз в ходе сбора необходимой информации исследователь сталкивается с ситуацией, когда он не в состоянии получить нужные статистические данные по одному или нескольким элементам. Это может быть вызвано самыми разными причинами, например коммерческой тайной. Чаще всего восполнить недостаток этой информации исследователю не удается. Приходится исключать этот элемент и его взаимосвязи из схемы когнитивной структуризации, что нарушает целостность модели и ухудшает ее имитационные свойства.
Простое исключение какого-либо элемента из когнитивной схемы может привести к бессмысленным результатам. Например, в схеме рис. 12.7, если неизвестны характеристики такого элемента, как "Оплата труда ППС", и мы вынуждены исключить его из схемы, получится, что повышение квалификации ППС определяется только средствами, направленными на приобретение оборудования и литературы. Это, очевидно, существенно искажает смысл модели, и ее результаты становятся малоценными. Поэтому с учетом того, какая информация имеется в его распоряжении, исследователь вновь возвращается к первому этапу и, возможно, существенно перестроит когнитивную схему.
3. Формирование математических моделей, описывающих когнитивные связи. В идеале, конечно, следует стремиться к тому, чтобы так детализировать когнитивную схему, чтобы взаимосвязи между элементами довести до элементарного уровня, лучше всего – до простых линейных зависимостей, когда изменение одного из элементов приводит к линейному изменению зависимого от него элемента. Но, к сожалению, в экономике это невозможно – любая социально-экономическая система нелинейна. Тогда следовало бы довести когнитивную схему до уровня четко определяемых взаимосвязей. Например, взаимосвязь между оплатой труда и его производительностью имеет нелинейный характер, и эта нелинейная зависимость хорошо изучена и довольно точно может быть описана с помощью математических моделей. Но и в этом случае остаются некоторые неясности – на тот же самый нелинейный характер зависимости между уровнем оплаты труда и его производительностью оказывают влияние и другие элементы и факторы. Включить всех их в модель просто невозможно – "нельзя объять необъятное". Поэтому в стремлении к элементаризации отношений внутри изучаемого объекта все равно не удается получить идеальную модель – множество факторов и условий останутся за ее пределами.
Это приводит и к тому, что вместо точных и однозначных отношений между элементами приходится прибегать в таких случаях к эконометрическим построениям, которые по определению несут в себе некоторую ошибку – вместо точной зависимости за ее незнанием приходится прибегать к некоему ее аналогу. Например, вместо имеющейся логарифмической зависимости – использовать квадратичную функцию, которая на определенном участке довольно хорошо описывает фактическую зависимость, но на остальных участках делает это плохо.
Задача этого третьего этапа построения ИДМ как раз и заключается в том, чтобы по возможности свести эту ошибку инструментария к минимуму, подобрав регрессионную модель не столько по статистическому критерию ее адекватности реально наблюдаемому ряду взаимосвязи, сколько исходя из экономической сути этой взаимосвязи.
В любом случае получается, что на этапе формирования математических взаимосвязей между элементами и подсистемами системы наряду с дискретными уравнениями в ИДМ приходится использовать стохастические взаимосвязи, а иногда включать интервалы неопределенности от минимальных до максимальных значений. Все это приводит к тому, что ИДМ не получается столь точной и адекватной, как ожидается.
На третьем этапе все взаимосвязи, описываемые в ИДМ, получают конкретное выражение либо исходя из аналитически выявленной количественной зависимости, либо исходя из статистически определенной регрессионной зависимости.
4. Компоновка имитационной динамической модели в целом. После того как прогнозист описал с помощью математических моделей все взаимосвязи и взаимозависимости, обозначил математическими символами каждую переменную, отражающую уровень развития каждого из элементов, возникает задача компоновки модели в целом.
Прежде всего, следует точно определить перечень экзогенных (внешних для данного объекта) и эндогенных (внутренних переменных объекта) переменных.
Экзогенные переменные определяют поведение внешних для объекта факторов, например, в схеме рис. 12.7 к экзогенным переменным, безусловно, следует отнести все показатели, которые характеризуют действия министерства, – они во многом определяются характеристиками вуза, но не вытекают из этих характеристик со всей очевидностью.
Все эндогенные (внутренние) переменные должны быть взаимосвязаны. В ИДМ не может быть эндогенных переменных, не связанных с внутренней системой моделируемого объекта. Если в процессе компоновки модели вдруг это выясняется, следует вновь обратиться к первому этапу и проанализировать, правильно ли построена когнитивная схема.
Связывая все переменные друг с другом, исследователь неминуемо столкнется с тем, что ему нужно будет задать некоторые временны́е характеристики, ведь идя через цепочку взаимосвязей от первых значений переменных и факторов модели к последним ее элементам, тем самым моделируется один цикл работы модулируемого объекта. Продолжительность этого цикла для каждого объекта различна и должна быть точно задана. В терминах математики это означает дискретный прирост времени в единицу. Если каждый цикл обозначается символом t, то дискретное изменение циклов Δt = 1 как раз и соответствует периоду одного очередного цикла. По сути, здесь под символом t подразумевается нс время в его строгом понимании, а некий счетчик циклов. Поэтому надо заранее определить, что Δt = 1 соответствует продолжительности производственного (или иного) цикла. Например, когда мы строили ИДМ Ульяновского автомобильного завода (УАЗ), производственный цикл составлял пять месяцев и каждый шаг расчета, каждый новый цикл означал затраты времени, равные пяти календарным месяцам.
Счетчик времени в модели может играть активную роль, если в ней имеются некие тренды, а может выступать просто индексом, отражающим масштаб моделируемого процесса, его развитие во времени.
В результате компоновки модели у прогнозиста должна получиться система уравнений и неравенств (если есть такая необходимость в задании ограничений), которая представляет собой взаимосвязь всех переменных, позволяющая, вычислив их значения на первом шаге, перейти к вычислению на втором шаге, опираясь на результаты первого. Результаты второго шага имитации являются основанием для вычисления значений переменных на третьем шаге и т.д.
В ходе компоновки модели, возможно, придется включить в модель некоторые новые переменные и уравнения, описывающие взаимосвязи, ранее не включенные в модель.
ИДМ скомпонована.
5. Отладка модели. ИДМ отличаются от всех других типов моделей, используемых в экономике, тем, что они без вычислительной техники не существуют – количество переменных, уравнений и неравенств, связывающих их, насчитывает несколько десятков единиц, а в особо сложных случаях – сотни и даже тысячи. Поэтому ни вручную, ни с помощью даже самого продвинутого калькулятора посчитать такие модели невозможно.
Задача данного этапа заключается в том, чтобы перенести математическую формулировку построенной модели на платформу имеющейся в распоряжении прогнозиста вычислительной техники. Конечно, существенно облегчают этот труд специально созданные платформы и языки программирования ЭВМ, ориентированные на имитацию неких процессов, но следует иметь в виду, что наиболее распространенные типовые платформы и языки пригодны лишь для моделирования определенного класса задач, но не всех задач вообще. Экономическая реальность такова, что разработать универсальную платформу для каждого реального случая не представляется возможным.
Поэтому прогнозисту следует подойти к используемому программному средству с позиций критико-конструктивного анализа, ни в коем случае не пытаясь подогнать модель под имеющееся программное средство, поскольку эти сразу же снизит практическую ценность и точность модели.
Следует внимательно изучить особенности платформы или языка программирования, чтобы понять, какие именно математические зависимости ими описываются. Например, в языке DINAMO, разработанном Дж. Форрестером, априорно предполагается наличие экспоненциальных зависимостей между элементами, а экспоненты, как известно, с ростом аргумента нелинейно возрастают. Это, кстати, и предопределило то, что этот язык перестал широко использоваться в экономической практике, хотя в 1970–1980-х гг. он был очень востребован. Наиболее распространенный сегодня язык имитационного моделирования – GPSS – в основном ориентирован на моделирование систем массового обслуживания, что также не прибавляет ему универсальности.
Если исследователя не удовлетворяет ни одна из существующих ныне платформ или ни один из языков программирования, он будет вынужден сам сформировать машинную версию имитационной модели. В не самых сложных случаях для этого вполне пригоден MS Excel.
После того как модель построена в терминах некоторой компьютерной программы, проводится ее пробное тестирование – пошаговая процедура вычислений всех элементов ИДМ. "Любая ошибка, которая может вкрасться в расчеты, обязательно вкрадется", – утверждал в своих законах научной деятельности Ф. Чизхолм. Этот закон лучше всего проявляется именно на этапе отладки модели – обязательно выяснится, что в процессе переноса математической модели на вычислительную платформу забывается какое-либо уравнение, знак случайно меняется на противоположный, путаются направления взаимосвязи, осуществляется деление на нуль, при построении схемы допускаются замкнутые циклы внутри модели, на втором шаге имитации оказывается недостаточно данных для дальнейших расчетов и т.п. Задача этого этапа – сделать модель пригодной для ее машинной реализации. Прогнав алгоритм вычисления характеристик модели несколько раз и устранив все очевидные ошибки, следует перейти к следующему этапу.
6. Верификация модели. Под верификацией модели понимается подтверждение на основе представления объективных свидетельств того, что модель соответствует требованиям точности, предъявляемым к прогностическим моделям. Но как определить, что точность модели такова, что ее можно использовать для прогнозирования, ведь будущее не определено? Точность описания моделью прошлого только свидетельствует о том, что она пригодна для описания прошлого, но как определить, что она пригодна и для прогнозирования будущего? Здесь принято в качестве некоего эталона, с которым уместно сравнение, использовать простую прогнозную модель, например модель тренда. Если прогнозные значения основных показателей ИДМ принципиально в разы не отличаются от прогнозных значений трендов, можно говорить о том, что ИДМ прошла верификацию и пригодна для практических целей. Если же выяснится, что результаты прогнозов ИДМ и трендов принципиально отличаются друг от друга, это означает, что необходимо выявить причину такого расхождения. Возможно, что ИДМ учитывает такие факторы, которые не учитывает модель тренда, и именно поэтому имеется расхождение в результатах прогноза, т.е. ИДМ точнее и правильнее описывает систему причинно-следственных связей реального объекта прогнозирования. Но чаще всего расхождения вызываются все-таки тем, что в ИДМ имеются ошибки, которые следует устранить.
И здесь следует указать на специфическую ошибку ИДМ, приводящую к возникновению систематического отклонения моделируемых величин от реальных значений. Чтобы понять суть этой ошибки, воспользуемся условным примером.
Пример
Пусть взаимосвязь между элементами, выявленная исследователем, позволила ему построить когнитивную схему, представленную на рис. 12.8.
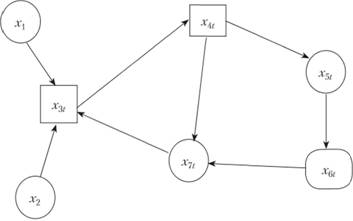
Рис. 12.8. Когнитивная схема условного примера
Статистические данные по объекту прогнозирования и его элементам приведены в табл. 12.11. Экзогенными по отношению к данному объекту выступают параметры х1 и х2. Это могут быть, например, фиксированные платежи. Для рассмотренного примера приняты такие значения: х1 = 0,2 и х2 = 0,15, а также х70 = 1,2, поскольку это начальное значение предыдущего шага имитации.
Таблица 12.12
Данные условного примера
|
t |
|
|
|
|
|
|
1 |
0,816655 |
0,86998 |
1,735973 |
3,523749 |
1,457469 |
|
2 |
1,010318 |
1,068474 |
1,863765 |
3,474325 |
1,71822 |
|
3 |
1,193122 |
1,260148 |
1,987251 |
3,42819 |
1,955494 |
|
4 |
1,483728 |
1,312509 |
2,226123 |
3,262093 |
2,289318 |
|
5 |
1,43449 |
1,665473 |
2,132878 |
3,421192 |
2,273846 |
|
6 |
1,553709 |
1,808093 |
2,215384 |
3,396438 |
2,419196 |
|
7 |
1,641148 |
1,941605 |
2,272654 |
3,388563 |
2,526753 |
|
8 |
1,819766 |
1,946299 |
2,42677 |
3,275865 |
2,720826 |
|
9 |
1,780913 |
2,135217 |
2,368197 |
3,368626 |
2,693842 |
|
10 |
1,831599 |
2,206088 |
2,403123 |
3,361573 |
2,753652 |
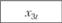
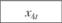
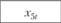
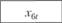
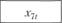
Анализ взаимосвязей позволил предложить для их описания следующие модели:
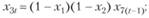 (12.59)
(12.59)
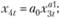 (12.60)
(12.60)
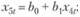 (12.61)
(12.61)
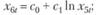 (12.62)
(12.62)
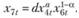 (12.63)
(12.63)
Используя метод наименьших квадратов для этих моделей (за исключением первой модели, где параметры задаются извне), получим такие оценки коэффициентов:
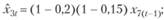 (12.64)
(12.64)
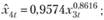 (12.65)
(12.65)
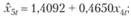 (12.66)
(12.66)
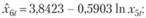 (12.67)
(12.67)
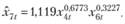 (12.68)
(12.68)
Точность аппроксимации этими моделями исходных данных табл. 12.12 довольно высока. Это со всей очевидностью следует из табл. 12.13, в которую сведены результаты аппроксимации моделями (12.64) – (12.68) исходных данных.
Таблица 12.13
Точность аппроксимации данных табл. 12.8 моделями (12.64) – (12.68)
|
t |
|
|
|
|
|
|
1 |
0 |
-0,0332 |
0,0778 |
0,0070 |
-0,0717 |
|
2 |
0 |
-0,0226 |
0,0423 |
-0,0005 |
-0,0313 |
|
3 |
0 |
-0,0001 |
0,0079 |
-0,0087 |
0,0075 |
|
4 |
0 |
0,1195 |
-0,2066 |
-0,1078 |
0,3187 |
|
5 |
0 |
0,0709 |
0,0508 |
0,0260 |
-0,0776 |
|
6 |
0 |
-0,0487 |
0,0346 |
0,0237 |
-0,0610 |
|
7 |
0 |
-0,0508 |
0,0394 |
0,0309 |
-0,0741 |
|
8 |
0 |
0,0188 |
-0,1125 |
-0,0431 |
0,1440 |
|
9 |
0 |
0,0096 |
0,0339 |
0,0352 |
-0,0746 |
|
10 |
0 |
-0,0613 |
0,0319 |
0,0368 |
-0,0748 |
|
Средняя ошибка аппрок симации |
0,00% |
3,01% |
2,95% |
0,94% |
4,10% |





Поэтому можно было бы ожидать приличной точности имитации этого сложного объекта с помощью ИДМ, в которую воедино сведены уравнения (12.64) – (12.68). Выполним пошаговую имитацию динамики объекта. Вначале вычислим расчетные величины на первом шаге t =1. Затем, опираясь на эти расчетные значения, вычислим значения модели на втором шаге t = 2. Полученные расчетные значения переменных будут являться основанием для следующего шага имитации для t = 3 и т.д.
Результаты имитации обескураживают – модель плохо описывает исходные данные, причем ошибка имитации каждого из показателей имеет один и тот же знак, что свидетельствует о наличии систематической ошибки (табл. 12.14). В таблице эти ошибки приведены в процентах от имитируемой величины.
Таблица 12.14
Ошибки имитации каждой из переменных условной ИДМ
|
t |
|
|
|
|
|
|
1 |
0,00 |
-7,63 |
2,70 |
-0,65 |
-0,78 |
|
2 |
-0.78 |
-11,68 |
-0,85 |
0,16 |
-6,35 |
|
3 |
-6,35 |
-17,89 |
-4,88 |
1,12 |
-12,52 |
|
4 |
-12,52 |
-16,90 |
-13,92 |
6,02 |
-22,62 |
|
5 |
-22.62 |
-32,51 |
-9,43 |
0,95 |
-20,53 |
|
6 |
-20,53 |
-36,76 |
-12,39 |
1,60 |
-24,45 |
|
7 |
-24,45 |
-40,53 |
-14,37 |
1,79 |
-27,19 |
|
8 |
-27,19 |
-40,34 |
-19,68 |
5,27 |
-32,14 |
|
9 |
-32,14 |
-45,45 |
-17,62 |
2,35 |
-31,31 |
|
10 |
-31,31 |
-47,10 |
-18,78 |
2,56 |
-32,72 |
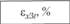


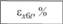
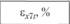
Поскольку ошибки имитации не только имеют один и тот же знак, но и нарастают по своему абсолютному значению с возрастанием шага имитации, модель непригодна для прогнозирования поведения объекта.
Нами был использован условный пример, который наглядно показал, что после построения модели и ее отладки в процессе верификации выясняется, что модель оказывается непригодной для имитации.
В некоторых учебных пособиях и учебниках в таком случае рекомендуется вновь вернуться к первому шагу построения ИДМ и, анализируя шаг за шагом процесс ее построения, постараться найти источник той ошибки, которая приводит к появлению систематических отклонений в ходе имитации. Чаще всего следование такой процедуре приводит к существенному изменению структуры модели – появлению новых показателей и исчезновению старых, изменению вида зависимостей между элементами модели и т.п. Подобные изменения зачастую искажают смысл самой модели, хотя она начинает более или менее адекватно описывать реальную ситуацию.
На самом деле возникновение систематического отклонения имитируемых показателей от фактических вызвано совсем другими причинами. Разберемся в них.
Для определения вида каждой из моделей и вычисления ее коэффициентов (чаще всего с помощью МНК) используют фактические значения, статистическая обработка которых позволяет получить модель, хорошо описывающую зависимость между фактическими значениями одной переменной и фактическими значениями другой. Но в процессе имитации в полученные уравнения вместо фактических значений подставляют расчетные. А ведь расчетные значения по определению содержат в себе ошибку, ведь они с той или иной степенью точности описывают реальные данные. Вот и получается, что расчетные величины, содержащие в себе ошибку аппроксимации, подставляются в уравнение регрессии, которая описывает реальные процессы с другой ошибкой. Эти две ошибки синтезируются в одну – ошибку имитации. Имитируемые значения, содержащие в себе ошибку имитации, вновь подставляются в регрессионные уравнения, где ошибка имитации усиливается за счет ошибки, присущей регрессионной модели. Вот и получается, что с каждым шагом имитации ошибка накапливается, и модель все хуже и хуже описывает исходные ряды наблюдений.
Пример
Покажем возникновение ошибки имитации на нескольких первых этапах имитации на вышеприведенном условном примере.
Первое уравнение ИДМ (12.64) описывает реальное значение с некоторой ошибкой аппроксимации:
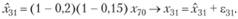 (12.69)
(12.69)
В последующее уравнение ИДМ подставляется не фактическое значение переменной, а расчетное. Расчетное значение из (12.69) можно записать так:
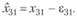 (12.70)
(12.70)
Если бы далее подставлялось фактическое значение х3], а не расчетное, то второе уравнение модели описывало бы реальное значение четвертой переменной с ошибкой аппроксимации регрессионной модели:
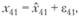 (12.71)
(12.71)
т.е.
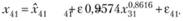 (12.72)
(12.72)
Но ведь вместо фактического значения третьей переменной х31 в (12.72) в процессе имитации подставляется расчетное значение, которое отличается от фактического на некоторую ошибку, как это следует из (12.71). С учетом этой ошибки (12.72) запишется так:
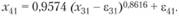 (12.73)
(12.73)
Становится очевидным, что в процессе имитации четвертая переменная будет описываться имитационной моделью хуже, чем регрессионной – появилась ошибка имитации:
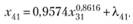 (12.74)
(12.74)
Расчетное значение четвертой переменной отличается от фактического значения на эту ошибку имитации.
Для вычисления пятой переменной в ходе имитации в регрессионное уравнение вновь вместо фактического значения четвертой переменной подставляется его расчетное значение:
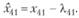 (12.75)
(12.75)
Эго означает, что пятая переменная будет имитироваться с помощью регрессионной модели с такой ошибкой:
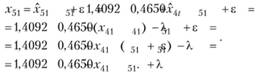 (12.76)
(12.76)
В свою очередь, и шестая переменная вычисляется нс через фактическое наблюдение, а через полученное в результате имитации значение с ошибкой имитации и т.д. Уже седьмая расчетная переменная, которая заканчивает первый цикл вычислений, содержит в себе помимо ошибки аппроксимации ε71 еще и ошибку имитации λ71. Это расчетное значение теперь является основой для дальнейшей имитации на следующем, втором цикле расчетов. Оно содержит в себе значительную ошибку имитации реального значения, и эта ошибка никуда не исчезает, а продолжает влиять на все вычисления последующих значений переменных на втором шаге, затем на третьем, на четвертом и т.п. Из табл. 12.10 эта динамика ошибки имитации легко прослеживается – если на первом шаге она была еще относительно мала, то на всех последующих шагах имитации она возрастает.
Приведенный пример показывает нам, где именно находится источник ошибки имитации, которая приводит к систематической и все возрастающей ошибке имитации всех показателей:
1) использование при имитации вместо фактических расчетных величин имитируемых показателей;
2) наличие замкнутого контура, в результате чего ошибки каждого шага имитации не исчезают, а накапливаются.
Теперь понятно, как избежать появления специфической ошибки имитации. Для этого есть два пути:
1) находить значения всех коэффициентов имитационной модели, решая систему одновременных уравнений, что в эконометрике осуществляется с помощью таких методов, как косвенный МНК и двухшаговый МНК (здесь мы на них останавливаться не будем);
2) корректировать коэффициенты ИДМ в ситуациях, когда расчетные значения модели превышают допустимые пределы. А поскольку имитируемая социально-экономическая система эволюционирует во времени, формальным математическим аппаратом такой корректировки должен выступать метод адаптации моделей с помощью неравномерного сглаживания, рассмотренный ранее.
7. Выполнение многовариантных расчетов, в том числе прогнозных. Меняя значения входных переменных или некоторых констант (уровень налога, процент отчисления на инновации, нормы амортизации и т.п.), получают многовариантные прогнозы развития, или, как часто говорят экономисты, определяют разные траектории развития, из которых можно выбрать наилучшую, и из условий модели понять, какие из них приведут объект к этой траектории.
Как видно из материалов данной главы, существующие способы описания с помощью экономико-математического моделирования структуры социально-экономических объектов все же не позволяют получать прогнозы, существенно лучшие, чем те, которые прогнозист вычисляет с помощью более простых прогнозных моделей.
Основная причина этого заключается нам видится в том, что любой социально-экономический объект столь сложен для анализа, что выявить все его составляющие элементы и взаимосвязи между ними и удовлетворительно описать их с помощью математического аппарата наука пока что не в состоянии. Поэтому удается описать лишь некоторые элементы объекта и наиболее простые взаимосвязи между ними. К тому же совершенно не разработан аппарат моделирования эволюционного развития. Адаптивные модели и методы, часть из которых изложена в предыдущих главах учебника, позволяют только учесть последствия эволюционного развития, но не промоделировать его. В результате этого самые сложные экономико-математические прогнозные модели, описывающие структуру социально-экономического объекта, позволяют лишь отчасти улучшить прогнозные результаты.
Заключение
Выпуская этот учебник "в свет", мы осознаем, что вовсе не ставим точку на рассматриваемой теме. В нем мы лишь представили свою точку зрения на социально-экономическое прогнозирование как с позиций методологии, так и с позиций инструментария.
Читатель наверняка заметил, что и по структуре, и по содержанию наш учебник отличается от того множества учебников по прогнозированию, которые хотя и в малом количестве, но все же издаются в современной России. В отличие от них мы в качестве структурирующего признака выбрали признак характера социально-экономической динамики, в первую очередь группировку этой динамики на процессы обратимые и необратимые. Это позволило, как нам представляется, изложить материалы учебника более системно, чем это делается в других изданиях.
Почему мы, завершив работу над учебником, все же думаем над его продолжением? Этому есть несколько причин.
Первая причина очевидна – экономика и социально-экономические процессы – очень сложные объекты для научного и практического исследования. С каждым днем появляются все новые и новые научные знания, которые могут использоваться в том числе и для прогнозирования.
Вторая причина связана с тем, что давно и успешно применяемый на практике инструментарий прогнозирования также продолжает совершенствоваться и развиваться. Описав сегодня основное состояние дел в этом вопросе, уже завтра мы будем вынуждены говорить о том, что учебник требует пересмотра, дополнения и развития за счет новых инструментов. Сегодня можно прогнозировать появление в недалеком будущем новых методов и моделей, как связанных с инструментами прогнозирования, изложенными в данном учебнике, так и вновь изобретенных.
Прежде всего, следует отметить такую проблему, к решению которой ученые уже приступили, но пока что еще не имеют удовлетворительного решения, как построение прогнозной модели с изменяющейся структурой. Любая экономическая система, развиваясь во времени, меняет не только свои количественные характеристики, но и состав элементов, а также направление и степень взаимосвязи между ними. Даже самые "продвинутые" сегодня прогнозные модели все же слабо отражают это свойство прогнозируемых объектов. Состав переменных прогнозных моделей и уравнения, описывающие взаимосвязь между факторами и показателями, либо остаются неизменными, либо корректируются с учетом происходящих в реальных объектах изменениях, но не вскрывают при этом внутреннюю причину и механизм эволюционного развития. Такие прогнозные модели, которые бы самостоятельно меняли свою структуру и состав переменных, отражая эволюционную динамику социально- экономических объектов, пока что только разрабатываются и не являются достоянием научной общественности из-за фрагментарности реальных успехов. Нам представляется что в основе построения таких моделей может лежать метод неравномерного сглаживания (гл. 11), полученный из модификации метода стохастической аппроксимации, поскольку вариацией параметров демпфирования колебаний можно добиться в том числе и того, что некоторые коэффициенты модели либо вовсе не будут изменяться во времени, либо будут существенно усиливать свое влияние на прогнозируемый результат, либо их влияние будет сведено к нулю.
Существенное развитие теории и инструментария социально-экономического прогнозирования ожидается от развития комплексно-значной экономики[4] – использования элементов теории функций комплексного переменного для моделирования экономики. В нашем учебнике мы привели лишь малую часть новых моделей и методов комплексно-значной экономики – в параграфах 2.5 и 4.4. Но уже здесь мы показали, как обогащается инструментарий социально-экономического прогнозирования за счет комплексно-значной экономики.
Третья причина заключается в том, что осветить все возможные методы прогнозирования в рамках одного учебника затруднительно. Так, мы практически не уделили внимания комбинированным прогнозам, которые по последним исследованиям прогнозистов в ряде случаев позволяют увеличить точность прогнозов по сравнению с индивидуальными методами (такими, как авторегрессии и экспоненциальное сглаживание). Такому разделу, как прогнозирование хаотических процессов, которые нередко встречаются в социально-экономической динамике, мы так же пока не уделили должного внимания. Теория хаоса как самостоятельная дисциплина начала свое формирование еще в 1970-х гг. и в настоящее время является довольно развитым научным разделом математики, но при этом рекомендовать для нашего учебника хотя бы один успешный метод прогнозирования хаотических процессов мы не можем – в их числе нет таких, которые были бы проверены многолетней практикой. По той же причине мы не изложили в учебнике и материалы, посвященные применению в прогнозировании социально-экономических процессов нейронных сетей.
Если сегодня эти разделы пока что являются прерогативой научных исследований, то через некоторое время, а мы в этом уверены, они будут до такой степени отработаны и формализованы, что, несомненно, прочно войдут в арсенал методов и моделей социально-экономического прогнозирования.