Вычислительные процедуры
Современные приложения метода дисперсионного анализа предполагают использование современных вычислительных средств, оснащенных современными пакетами статистической обработки или электронными таблицами. Однако это не значит, что небольшой объем данных, относящихся к несложным экспериментальным планам, не может быть обработан вручную или же с помощью простейшего карманного или настольного калькулятора. В этом случае, правда, не вполне подходят формулы, которые приводились выше для разъяснения смысла однофакторного дисперсионного анализа, так как они несколько затрудняют и без того не совсем простые вычисления. В "ручных" вычислениях имеет смысл использовать формулы, полученные из уже приведенных в результате несложных алгебраических преобразований.
Так, формулу (3.1) лучше преобразовать к следующему виду:
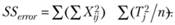 (3.6)
(3.6)
Формулу (3.2) имеет смысл переписать таким образом:
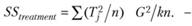 (3.7)
(3.7)
Наконец, формулу (3.4) будет лучше выразить так:
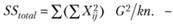 (3.8)
(3.8)
Нетрудно заметить, что три новые формулы (3.6)-(3.8) имеют общие элементы. Поэтому нет смысла проводить все вычисления по каждой из них отдельно. Лучше начать подсчет именно с этих общих элементов, их всего три. В результате вычисления значительно упростятся.
В табл. 3.4 резюмируются логика однофакторного экспериментального плана и его вычислительные процедуры.
Таблица 3.4
Вычислительные процедуры однофакторного дисперсионного анализа
|
Уровни независимой переменной |
|||||||||
|
1 |
… |
j |
… |
k |
|||||
|
X11 |
Xj1 |
Xk1 |
|||||||
|
. |
. |
||||||||
|
. |
. |
||||||||
|
. |
. |
||||||||
|
X1n |
… |
Xjn |
… |
Xkn |
|||||
|
|
… |
|
… |
|
|||||
|
|
|||||||||
|
Элементы формул |
|||||||||
|
|
|
|
|||||||
|
Формулы |
|||||||||
|
Источник дисперсии |
Принятое обозначение |
Суммарный квадрат |
Степени свободы |
||||||
|
Экспериментальная ошибка |
Enor |
(2) – (3) |
(kп – 1) |
||||||
|
Экспериментальное воздействие |
Treatment |
(3)-(1) |
k – 1 |
||||||
|
Общий |
Total |
(2)-(1) |
kn – 1 |
||||||
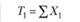
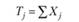
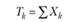
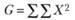
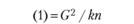
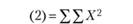
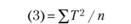
Как видно, табл. 3.4 состоит из трех блоков. Верхний блок резюмирует логику однофакторного экспериментального плана, который предполагает выделение одной независимой переменной с произвольным числом уровней, равным k. На основании этого экспериментального плана формируется выборка испытуемых, включающая в себя k независимых экспериментальных групп по п испытуемых в каждой. По результатам эксперимента с этой выборкой испытуемых оцениваются значения зависимой переменной Хij и вычисляется их общая сумма и сумма значений по каждой группе. Эти данные необходимы на следующем этапе работы, представленном в среднем блоке табл. 3.4, который содержит вычислительные символы или элементы формул для вычислений. Они используются на следующем этапе работы. Наконец, нижний блок обобщает основные результаты требуемых дисперсионным анализом вычислений. Крайняя левая колонка содержит список аддитивных (независимых) частей общей дисперсии, на которые она разлагается. Вторая колонка содержит принятые в математической статистике англоязычные индексные наименования этих источников. Третья и четвертая колонки содержат формулы для вычислений суммарных квадратов и числа степеней свободы для каждого источника дисперсии, причем формулы суммарных квадратов даны в терминах вычислительных символов, приведенных в средней части табл. 3.4. На основе этих данных вычисляются средние квадраты для каждого источника дисперсии и строится F-статистика.
Вычисления с помощью компьютера
Значительно более эффективно сравнение двух и более выборок с помощью стандартных процедур дисперсионного анализа может быть осуществлено с использованием статистических пакетов. Рассмотрим в качестве примера, каким образом можно выполнить сравнение нескольких независимых выборок с помощью статистического пакета IBM SPSS Statistics. Более детальное описание этой процедуры с использованием конкретных экспериментальных данных приводится в параграфе 3.7. Здесь же ограничимся лишь описанием общей схемы анализа.
Прежде всего требуется правильно подготовить данные. Для этого после запуска программы нужно перейти на вкладку "Переменные" и создать лишь две переменные – независимую и зависимую. Например, если бы мы хотели обработать данные, представленные в табл. 3.3, нам было бы необходимо создать переменные "Методика" (или "Группа") и "Оценка". Переменная "Методика" – это независимая переменная, и она принимает три различных значения. Эти значения нужно указать в поле "Значения" так, как мы это уже делали, рассматривая практический пример использования t-теста в параграфе 2.7 (см. рис. 2.8). Переменная "Оценка" является зависимой переменной. Ее значения нужно ввести для каждого испытуемого каждой группы, вернувшись на вкладку "Данные".
После того как все данные будут правильно введены, для проведения дисперсионного анализа в меню "Анализ" можно будет выбрать раздел "Сравнение средних", а в нем – "Однофакторный дисперсионный анализ...". Так как дисперсионный анализ относят классу общих линейных моделей, то для проведения однофакторного дисперсионного анализа для несвязных выборок в меню "Анализ" можно выбрать раздел "Общие линейные модели", а в нем – "ОЛМ-одномерная...". Этот вариант предоставляет нам несколько больше возможностей анализа данных, но для простоты дальнейшего изложения будем считать, что мы выбрали первый, более простой вариант.
Итак, выбрав последовательно "Анализ", "Сравнение средних", "Однофакторный дисперсионный анализ", мы откроем окно выбора переменных. Оно содержит три поля. В большом левом поле будет представлен полный список переменных. В нашем случае это переменные "Методика" и "Оценка". Справа мы увидим два поля: "Список зависимых переменных" и под ним – "Фактор". В первое поле необходимо ввести все репликации зависимой переменной, которые используются в эксперименте. В нашем случае это одна переменная – переменная "Оценка". Во втором поле нужно указать независимую переменную. В пашем случае это переменная "Методика".
Нажимаем кнопку "ОК". После непродолжительной паузы открывается окно с результатами дисперсионного анализа. Эти результаты должны быть представлены в виде таблицы, в которой (в соответствующих столбцах) указаны:
• источники дисперсии – между группами и внутри группы (первый столбец);
• результаты вычисления суммарных квадратов для этих источников дисперсии (второй столбец);
• число степеней свободы, соответствующих этим суммарным квадратам (третий столбец);
• результаты деления суммарных квадратов на соответствующее им число степеней свободы – средние квадраты (четвертый столбец);
• значения F-статистики (пятый столбец);
• величина квантиля, отсекаемого этой статистикой, которая указывает на уровень значимости полученного результата (шестой столбец).
Аналогичным образом для дисперсионного анализа можно использовать статистический пакет STATISTICA.
Следует отметить, что стандартные процедуры однофакторного дисперсионного анализа можно применить, используя электронную таблицу MS Excel. Для этого необходимо установить специальную надстройку, которая называется "Пакет анализа". Эта возможность, однако, недоступна на компьютерах и планшетах, работающих под управлением Windows RT. Следует также отметить, что в отличие от полноценных статистических пакетов, "Пакет анализа" MS Excel реализует лишь базовые процедуры дисперсионного анализа, и в нем, в частности, недоступны возможности оценки контрастов и проведение предварительных статистических тестов, которые обсуждаются ниже.