Экспертная валидизация методики
Одно из крайне дефицитных умений при анализе валидности оценочных методов – это не столько расчет самого коэффициента корреляции ("щелкнуть" на название функции в электронной таблице – дело не хитрое), сколько формирование адекватной структуры данных. Как, например, следует сформировать структуру данных, чтобы подсчитать корреляцию между тестовыми баллами и экспертными оценками? В табл. 11.3 для наглядности представлена очень простая структура данных: и тест, и эксперты оценивают один и тот же конструкт (критерий, компетенцию). Чаще всего нас интересует в данном случае коэффициент корреляции между двумя столбцами таблицы – между тестовым баллом и усредненной (по принципу медианы) экспертной оценкой в последнем столбце.
Таблица 11.3
Структура данных при расчете корреляций между тестом и экспертными оценками по испытуемым
|
Испытуемый |
Тест |
Эксперт 1 |
Эксперт 2 |
Усредненная экспертная оценка |
|
|
Испытуемый 1 |
Балл |
Оценка |
|||
|
Испытуемый 2 |
|||||
|
Испытуемый N |
Если между тестом, направленным на измерение, например, креативности, и экспертными оценками, выставленными тем же
самым испытуемым по оценочной шкале "креативность", обнаружена значимая корреляция, то это означает сразу две вещи:
1) тест обладает конвергентной валидностью с экспертными оценками по данному диагностическому конструкту;
2) эксперты адекватно осмыслили и применили данный конструкт для оценивания именно "креативности" – того самого свойства, которое подвергалось тестированию.
Данный прием взаимной валидизации теста и экспертных оценок особенно эффективен в тех случаях, когда:
а) срок ожидания появления критериального события (возможность измерения КПЭ) слишком велик, а принимать кадровые решения надо сегодня;
б) мы не располагаем доступом к высокообразованным экспертам (специализирующимся в области проф- и психодиагностики), которые могут оценить сами тестовые задания, так что к роли экспертов фактически привлекаем включенных наблюдателей (руководителей, коллег и т.п.);
в) измеряемый тестом конструкт не слишком сложен для включенных наблюдателей.
Например, по конструкту "общительность" вполне возможна такая несложная схема валидизации теста. А вот по очень специальному конструкту "полезависимость", пожалуй, вряд ли удастся использовать эту схему. Впрочем, можно попробовать на небольшой группе убедиться в том, что оценщики дают несогласованные результаты (трактуя сложный для них конструкт по-разному), и отказаться от дальнейшего наращивания выборки.
Нередко к экспертным оценкам на практике прибегают в тех случаях, когда сами реальные показатели КПЭ просто отсутствуют. Это возможно для некоторых сложных видов управленческой и вспомогательной деятельности специалистов, у которых результативность либо очень плохо формализуема, либо реально является слишком отсроченной (нужны годы ожиданий, чтобы оценить, например, эффективность сложного проекта). Тогда экспертные оценки заменяют показатели реальной производительности труда.
Впрочем, использование экспертных оценок для проверки одной лишь конвергентной валидности в строгом смысле не является достаточным основанием для вывода о валидности методики профотбора. Нужно проверить еще и дискриминантную валидность. Это становится возможным, если множество компетенций (оценочных конструктов), которые измеряются с помощью теста, находится в отношениях "наложения" (или приближенного номинального тождества) со множеством компетенций, которые подвергаются экспертной оценке. В табл. 11.4 приведена более сложная структура данных, которая возникает в таких случаях.
Таблица 11.4
Структура данных, иллюстрирующая массив тестовых баллов и экспертных оценок по одному и тому же множеству испытуемых и по одному и тому же множеству оценочных конструктов (компетенций, или критериев оценивания)
|
Испытуемый |
Тестовые баллы |
Усредненные экспертные оценки |
||||
|
Конструкт 1 |
Конструкт 2 |
Конструкт 3 |
Конструкт 1 |
Конструкт 2 |
Конструкт 3 |
|
|
Испытуемый 1 |
Балл |
Балл |
Балл |
Оценка |
Оценка |
Оценка |
|
Испытуемый 2 |
||||||
|
Испытуемый N |
||||||
Если для всех столбцов, представляющих баллы в табл. 11.4, посчитать попарные корреляции со всеми столбцами, представляющими экспертные оценки, то мы получим матрицу, весьма похожую на известную матрицу Кэмпбелла и Фиске – "многих черт и многих методов" (multi-traits and multi-method matrix). Эта матрица проиллюстрирована схематическим примером ниже, в табл. 11.5. Так же, как и в табл. 11.4, рассматривается пример оценивания только трех оценочных конструктов, но этот пример читатель легко может обобщить для произвольного множества К одноименных конструктов.
Таблица 11.5
Матрица корреляций между гипотетическими тестовыми и экспертными шкалами, иллюстрирующая проверку дискриминантной валидности
|
Эксперты Тесты |
Экспертная шкала 1 "Организованность" |
Экспертная шкала 2 "Стрессо-устойчивость" |
Экспертная шкала 3 "Инновационность" |
|
Тестовая шкала 1 "Организованность" |
|
|
|
|
Тестовая шкала 2 "Стрессоустойчивость" |
|
|
|
|
Тестовая шкала 3 "Инновационность" |
|
|
|
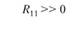
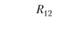
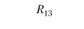
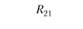
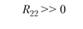
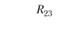
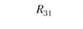
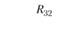
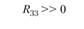
Итак, в каком случае мы говорим о конвергентной валидности двух систем шкал – тестовых и экспертных? В том случае если по главной диагонали матрицы стоят значимо высокие и положительные коэффициенты корреляции между одноименными шкалами – R11, R22 и R33. Чтобы подчеркнуть это значимое отличие от нуля, автор поставил на главной диагонали удвоенный значок "больше". А вот вне главной диагонали, по идее, должны стоять незначимые, близкие к пулю коэффициенты корреляции. Именно отсутствие корреляций между разноименными шкалами является свидетельством дискриминантной валидности тестовых и экспертных шкал относительно друг друга.
Тут принципиально важно подчеркнуть относительность двух источников информации – теста и экспертных оценок – в качестве источников информации о валидности. Ни первый, ни второй источник нельзя считать априори идеальным. Например, в табл. 11.5 мы можем получить значимую корреляцию R13 между тестовой шкалой 1 "Организованность" и экспертной шкалой 3 "Инновационность". О чем это говорит? Не столько о дефектах в конструкции теста, сколько о недифференцированности (недискриминативности) экспертных оценок, т.е. о том, что эксперты считают "инновационно ориентированными" сотрудниками более организованных сотрудников, смешивая (склеивая в сознании) два разных оценочных конструкта. А вот если бы при нулевом (практически нулевом) значении R13 мы получили бы значимо высокий коэффициент R31 то следовало бы делать противоположный вывод – о низкой дискриминативности именно теста, который приписывает высокую инновационность тем испытуемым сотрудникам, которых эксперты оценили как "организованных". Впрочем, для большей уверенности в том, в какой системе шкал произошла "склейка", надо проанализировать не только матрицу корреляций между тестовыми и экспертными шкалами, но и две матрицы внутренних корреляций (матрицы интракорреляций) – внутри тестовых шкал и внутри экспертных шкал. Если тестовые шкалы не дают высоких попарных корреляций, а экспертные дают такие корреляции, то корректнее сделать вывод о низкой дифференцированности экспертных оценок, чем о низкой дифференцированности тестовых измерений.
Логически более ясным критерием валидности является бинарный критерий, основанный на так называемых контрастных (или экстремальных) группах. Это как раз то самое "попадание в группу эффективных", о котором мы и стараемся главным образом говорить в этой главе.
Как формируются на практике группы высокопродуктивных и низкопродуктивных сотрудников? Нередко кажется, что самое простое в организационном (и интеллектуальном) плане решение – это взять в качестве "высокой" контрастной группы (группы эффективных) тех сотрудников, которые просто долго работают в организации и не имеют никаких документированных нареканий по работе, а в качестве "низкой" контрастной группы – тех, кто либо часто переходит с одного места на другое ("летуны"), либо имеет явные документированные нарекания (штрафы, выговоры и т.н.). Но как только выяснится, что по этому простому критерию оказывается невалидным (не дает значимых корреляций) ваш кейс-тест – довольно-таки дорогой по затратам на разработку (суммарному времени интеллектуальных усилий), выглядящий вполне разумным и для разработчиков, и для самих испытуемых, – то тут же возникнут вполне уместные (хотя и запоздалые) сомнения, а правильно ли выбран сам критерий. Вскоре может выясниться, что "документированные нарекания" отражают главным образом дисциплинарное поведение сотрудников: в "высокую" критериальную группу попадают за своевременное появление на рабочем месте, а в "низкую" – едва ли не самые продуктивные работники, некоторые из тех, кто, засиживаясь за компьютерами сверхурочно, добиваясь результата в заданные сроки, на следующее утро просто физически не могут подняться заблаговременно, чтобы избежать риска транспортных пробок и т.п. Оказывается, что надо учесть сроки выполнения производственных заданий (хотя бы сроки сдачи отчетности об их выполнении), сложность решаемых задач (а кто ее может корректно оценить, если руководитель сам является скорее "универсальным менеджером" и не знает технологического процесса в деталях?). Вот так возникает проблема построения множества различных показателей эффективности (отдельных КПЭ) и системы их интеграции – сводного индекса. В нашем руководстве "Практическая тестология. Тестирование в образовании, прикладной психологии и управлении персоналом" более подробно описываются (на расчетных примерах) приемы такого нормирования шкал эффективности (показателей КПЭ), которые позволяют сделать поправку на трудность решаемых производственных задач и зачислить в группу "эффективных" тех сотрудников, у которых количественные показатели формально ниже, но они трудятся на более сложных участках [6]. Специалисты согласятся, что наша рекомендация знаменует необычный, очень активный подход психологов к решению проблемы валидности – не передоверять формирование КПЭ кому-то другому, но самим активно вторгаться в эту область и использовать свои знания в области тестологии для формирования корректных показателей КПЭ.