Автоматизированные системы нормативнометодического обеспечения управления предприятиями и организациями
Автоматизированная система нормативно-методического обеспечения управления (АСНМОУ) предприятием (организацией) [1] должна содержать нормативно-правовые, нормативно-методические, нормативно-технические и организационно-распорядительные документы (НПД, НМД, НТД и ОРД), которые обеспечивают реализацию принятых проектных и управленческих решений в процессе функционирования предприятия (организации).
Пример структуры СНМОУ и АСНМОУ, соответствующей основным функциям, которые должна выполнять СНМОУ, приведен на рис. 7.1.
В качестве методической основы создания АСНМОУ используют идею стратифицированного представления процедуры поиска информации с углублением на каждой страте анализа документов, содержащихся в АСНМОУ, путем структуризации их текстов (рис. 7.2):
– на верхней страте – поиск документов по функциям управления;
– на второй сверху – поиск разделов документов в соответствии с запросом пользователя, взаимоотношений между разделами связанных друг с другом документов;
– на третьей страте – вывод текстов на дисплей или принтер (полного текста или его разделов);
– на четвертой страте (которая реализуется не для всех документов) – аналитико-синтетическая обработка (АСО) текстов документов (что, например, требуется при поиске информации в текстах законов и других НПД).
Виды баз данных определяются спецификой конкретного предприятия (организации).
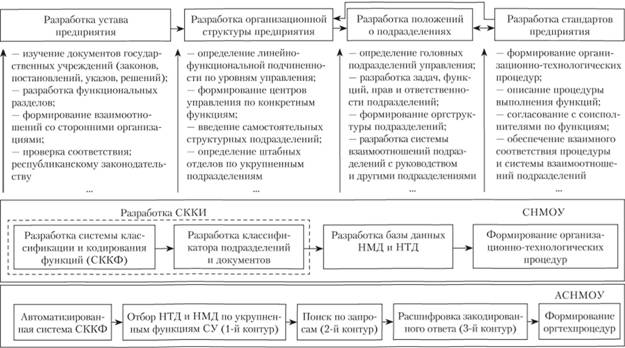
Рис. 7.1. Структуры СНМОУ и АСНМОУ
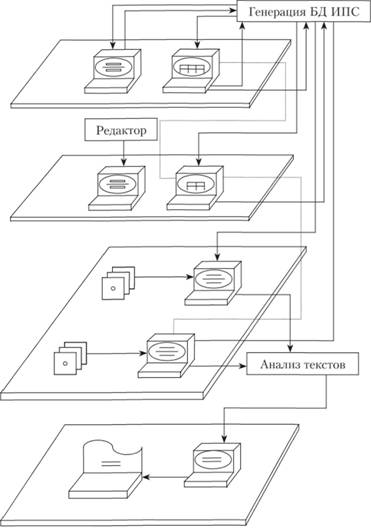
Рис. 7.2. Структуризация текстов, содержащихся в АСНМОУ
Например, базы данных можно выделить таким образом: создать базу данных НПД (общегосударственных, региональных), базу данных об НМД, НТД и ОРД органов отраслевого управления и предприятия. Для АСНМОУ предприятия может оказаться целесообразным создать отдельные базы СТП, должностных инструкций, положений о подразделениях и т.п. Базы данных для крупных предприятий и организаций имеют значительный объем, поэтому для организации эффективных процедур поиска и корректировки информации их нужно структурировать. Исследование особенностей БД АСНМОУ и работы с ними показало, что выбрать наиболее целесообразную жесткую структуру БД практически невозможно, так как, с одной стороны, подразделения предприятия принимают участие в выполнении нескольких укрупненных функций управления, а с другой – одна и та же функция выполняется несколькими подразделениями.
Базы данных для крупных предприятий и организаций имеют значительный объем. Для организации эффективных процедур поиска и корректировки информации их нужно структурировать. Исследование особенностей БД АСНМОУ и работы с ними показало, что выбрать наиболее целесообразную жесткую структуру БД практически невозможно, так как, с одной стороны, подразделения предприятия принимают участие в выполнении нескольких укрупненных функций управления, а с другой, одна и та же функция выполняется несколькими подразделениями.
Кроме того, нужно иметь в виду, что одна и та же функция может быть регламентирована в документах разного вида – и в положениях о подразделениях, и в СТП, и в ОРД и др. При этом одинаковые или сходные с различной степенью детализации и с несколько модифицированными формулировками функции в разных документах закодированы по-разному, в соответствии с группированием и индексированием функций, принимаемых при разработке документа его авторами.
Для того чтобы объединить все документы АСНМОУ в единую систему и реализовать идею стратифицированного углубления анализа их текстов, необходим единый информационно-поисковый язык (ИПЯ), с помощью которого можно описывать наименования и ОГЛАВЛЕНИЕ документов, что позволит их сопоставлять и осуществлять поиск по запросам, также переведенным на этот язык.
Такой язык можно реализовать в виде системы классификации и кодирования фасетного типа, основу которой составляет классификатор целей (основных направлений) и функций системы управления.
Изучение опыта практической реализации ИПС (включая все ее элементы – ИПЯ, систему индексирования, выбор КСС) с применением традиционного подхода к разработке ИПЯ, основанного на использовании в качестве его словаря терминов естественного языка, показало, что обычно разработка таких ИПЯ и ИПС в целом требует не менее трех – пяти лет. Далее необходим также довольно длительный период проверки ИПЯ и ИПС с точки зрения критериев релевантности и пертинентности. За такой длительный период в системе управления могут произойти существенные изменения и процесс корректировки ИПЯ снова потребует времени и значительных затрат труда разработчиков. Заимствовать же ИПЯ практически невозможно, можно говорить только о заимствовании структуры тезауруса, принципов системы индексирования, видов КСС. В результате известные разработки в области создания ИПС документально-фактографического типа для систем научно-технической информации плохо внедряются в практику автоматизации управления предприятиями и организациями.
С учетом сказанного в качестве информационно-поискового языка, связывающего все уровни АСНМОУ, разработана система классификации и кодирования информации (СККИ) фасетного типа, основной составляющей фасетной формулы которой является классификатор целей и функций системы управления предприятием.
Выбор классификации фасетного типа позволяет использовать различные виды классификации для разных фасет: часть – составляющих фасетной формулы (в том числе названная основная составляющая) использует иерархическую классификацию, часть – порядковую, серийную (классификаторы подразделений, видов документов), часть – смешанную (принятую при индексировании ОРД, ППД в конкретной организации). Достоинством фасетной классификации является также возможность изменения фасетной формулы (состава и порядка расположения фасет) с учетом особенностей конкретного предприятия, организации при сохранении общих принципов разработки АСНМОУ и СККИ.
Предложенная система классификации и кодирования информации в АСНМОУ позволяет структурировать базы данных под запрос по различным признакам: по функциям (классификатора целей и функций СОУ предприятия), по видам документов, по подразделениям и т.д.
Структуры записей в БД АДФИПС, создаваемых для ППД, НМД, ПТД различного типа, могут быть разными, но в каждой из них должны быть обязательно предусмотрены поля (и соответствующие фасеты в классификаторе) для индексов функций классификатора целей и функций СОУ предприятия.
Экспериментальные исследования показали, что наиболее удобно использовать трехуровневую структуру ЦФ, т.е. для этих индексов целесообразно отвести три поля. Тогда соответствующая фасета также должна содержать три поля и для индексов классификатора функций внутри документа (с учетом формата и особенностей индексирования документов конкретного вида), что и обеспечивает взаимосвязи между всеми документами, т.е. объединение их в единую систему.
В соответствии с идеей стратификации необходимо создавать сопряженные базы данных для различных страт. Используя терминологию теории НТИ, удобно говорить не о создании баз данных для различных страт, а о создании двух-, трех- или более контурных АДФИПС.
В частности, при создании БД нормативно-правовых документов исследовалось два варианта АДФИПС: двухконтурный – с поиском документов в первом контуре и извлечения из них разделов (которые содержат сведения о правовых нормах или производственных нормативах, представляющих собой фактографическую информацию для пользователя) во втором; трехконтурный с поиском в контурах последовательно в первом – документов, во втором – разделов и в третьем – статей (содержащих еще более конкретную фактографическую информацию о правовых нормах или нормативах).
Аналогично могут быть организованы БД нормативно-методических документов.
Например, при создании АДФИПС положений о подразделениях предприятия или БД НМД, НТД и ОРД могут быть образованы следующие контуры: 1) отбор положений или других НМД, НТД, ОРД, соответствующих запросу, т.е. структуризация под запрос (например, по укрупненным функциям, по группам подразделений); 2) поиск в базе отобранных документов по запросам пользователя необходимых ему сведений о функциях, сроках и способах их выполнения и тому подобной фактографической информации (поиск может осуществляться по признакам, предусмотренным при разработке АДФИПС); 3) вывод фрагментов документов, отобранных в соответствии с запросами во втором контуре, на дисплей или принтер в удобной для пользователя форме (например, разделов положений, содержащих необходимые сведения о функциях, сроках их выполнения, исполнителях, в виде таблицы и т.п.).
Пример трехконтурной АДФИПС нормативно-методических документов АСНМОУ (положений о подразделениях оргструктуры предприятия) приведен на рис. 7.3.
Структуры БД в этом примере имеют следующий вид (в приводимом примере принята фасетная классификация).
Структура первого контура БД положений о подразделениях:
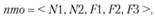
где N1 – номер отдела в существующей СНМОУ; N2 – наименование отдела; F1, F2, F3 – индексы укрупненной функции в структуре целей и функций предприятия, выполнение которой регламентируется в положении.
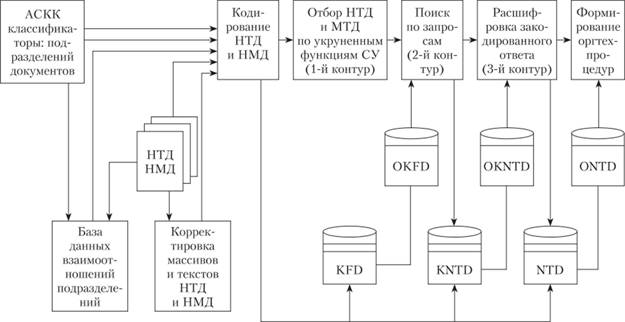
Рис. 7.3. Структура трехконтурной АДФИПС нормативно-методических документов АСНМОУ
Структура БД раздела "Взаимосвязь" положений о подразделениях предприятия (второго контура АД ФИПС), составляющими которой являются функции положения:
пто = <FI, F2, F3, NI, DI, FJ, DK, NP>,
где Fi, F2, F3 – индексы укрупненной функции в структуре целей и функций предприятия, выполнение которой регламентирует подготавливаемый документ; N1 – номер отдела-изготовителя документа в существующей СНМОУ; DI – наименование вида исходного документа (или конкретного документа), для подготовки которого выполняется функция; FJ – индекс функции внутри положения; DK – индекс документа, получаемого в результате выполнения функции; NP – номер отдела, в который передается документ для дальнейшей обработки (согласования). Поиск фактографической информации в этом контуре может осуществляться по любому параметру.
Третий контур – вывод соответствующих отобранных текстов.
В приведенном примере АДФИПС предусмотрен также блок формирования и анализа организационно-технологических процедур (ОТП) подготовки и реализации управленческих решений, на основе формирования и анализа которых можно уточнить структуру АДФИПС.
Соответственно для БД – нормативно-правовых документов.
Структура БД НПД первого контура может быть представлена следующим образом:
npd = <N, Т, D, М, F1, F2, F3, IF>,
где N – номер документа в БД НПД; Т – тип документа (закон, постановление и т.п.); D – наименование документа; М – место опубликования или хранения документа; Fi, F2, F3 – индекс укрупненной функции, регламентируемой документом; IF– имя файла, в котором хранится текст документа (или фрагменты текста).
Структура БД НПД второго контура будет иметь вид:
npd = <N, D, R, F1, F2, F3, F4, F5, F6, IFR>,
где N – номер документа в БД НПД; D – наименование документа (закона, постановления, и т.п.); R – наименование раздела документа; Fi, F2, F3, F4, F5, F6 – индекс функции, регламентируемой разделом; IFR – имя файла, п котором хранится раздел текста документа.
При необходимости может быть сформирован контур для статей НПД или контур аналитико-синтетической обработки информации.
Для ускорения разработки АСНМОУ для конкретных предприятий и организаций разрабатываются системы ее генерации АДФИПС, с примерами которых можно познакомиться в 11, 191.
Приведенные примеры ДФИПС относятся к классу ИПС, в которых фактографический поиск понимается как процесс отыскания уже готовых данных и фактов, которые извлекаются из текстов в процессе подготовки и индексирования входных данных и вводятся в массивы ИПС. В этом случае теория и методика разработки таких ИПС практически не отличается от чисто документальных ИПС, и нередко ДИПС развивались и преобразовывались в ДФИПС.