Анализ потоков данных
Для построения базы данных необходимо хорошо понимать процессы, происходящие с данными в течение их обработки и преобразования. Такие процессы представляются моделями потоков данных. Ранее уже были рас-
смотрены некоторые представления моделей потоков данных, но совершенно не был рассмотрен вопрос, связанный с представлением данных и их передачей для обработки. Данные в информационных системах передаются электронными сообщениями, структура которых определяется потребностями в данных для выполнения соответствующей операции.
Часть сведений в электронных сообщениях формирует пользователь, основываясь на сведениях, содержащихся во входящих документах. В результате же обработки данных, если дальнейшая обработка не предусматривается, электронное сообщение преобразовывается в выходной документ, который может представляться в электронном или бумажном виде. Именно это преобразование данных и работу с документами отражают модели потоков данных.
Наряду с пониманием того, какие данные обрабатываются и в какой последовательности происходит эта обработка, разработчик также, описывая модель потоков данных, определяет множество информационных потребностей пользователей в данных, где под пользователем рассматриваются не только люди, использующие информационную систему для работы с данными, но и сама информационная система, а точнее, ее модули и подсистемы, которые обращаются к базе данных для получения дополнительных вспомогательных сведений.
Моделирование потоков данных предполагает указания от разработчика не только задач, выполняемых над данными, используемых хранилищ в форме базы данных, но также входящих и выходящих сообщений, которые будут представляться бумажными или электронными документами, формируя дополнительный поток данных, необходимый для корректного выполнения задач. Наряду с этим, разработчик разделяет задачи на два вида: неавтоматизированные и автоматизированные, — определяя в потоке данных задачи, когда пользователь должен провести обработку данных без использования автоматизированной системы. Обычно такие задачи связаны с формированием исходных данных, которые впоследствии автоматизированная задача будет использовать для получения результирующих сведений, представляемых в виде электронных форм документов.
Модель потоков данных может представляться в двух вариантах: диаграмма потоков данных (ДПД/ОРО), где указываются задачи участника процесса по преобразованию исходных сведений в результирующие, и диаграмма работ с данными, когда описываются операции обработки данных, проводящих в автоматизированной системе преобразование сведений, включая их сохранение в базе данных или удаление существующих сведений.
В первом случае, при формировании диаграммы потоков данных в рамках рассмотрения бизнес-процесса или вспомогательного процесса, появление элементов "Хранилище" и отражение задач обработки данных приводит к необходимости их отражения в дереве функций, определяя необходимые структуры данных для выполнения соответствующего процесса.
Во втором случае, при формировании диаграммы работ, дерево функций не пополняется новыми задачами, но формируется дерево связей функций, отражающее последовательность использования операций выборки, добавления, модификации и удаления в рамках применения основных и вспомогательных функций, отраженных в дереве функций. Эта модель (дерево связей функций) позволяет разработчику выделить укрупненный алгоритм преобразования данных и определить функции, реализация которых позволяет выполнить соответствующие операции.
Формирование дерева связей функций обусловлено возможностями реализации многих процессов работы с данными в рамках СУБД, не перенося их на уровень приложения, отделяя, тем самым, задачи работы с данными от задач организации интерфейса. По сути, современное программное приложение работы с базой данных может быть реализовано на основе трех условно-независимых программных модулей (рис. 2.27).
|
Рис. 2.21. Технология взаимодействия компонентов программного приложения |
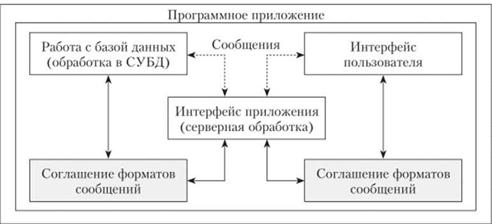
При работе с базой данных пользователь с ней напрямую не взаимодействует, а посылает через интерфейс приложения (серверная обработка) сообщения о необходимости выполнить какое-либо действие и передать ответный результат, представляемый на экран. Это позволяет четко разделить отдельные этапы обработки данных и явно указать модули программного приложения, отвечающие за соответствующие задачи:
• интерфейс пользователя:
— представление экранных форм для ввода исходных данных,
— представление результата обработки данных в удобном для пользователя виде,
— визуализация интерфейса пользователя;
• интерфейс приложения:
формирование структуры и наполнения экранных форм пользователя,
— передача сведений от пользователя в обработку на уровень СУБД,
— передача пользователю результата обработки в СУБД,
— специфическая обработка данных с использованием механизмов, не реализуемых в СУБД;
• работа с базой данных:
— модификация данных в базе данных,
— выборка данных по информационным потребностям пользователей,
— алгоритмическая обработка данных в базе данных с использованием инструментов программирования.
Для такого четкого разделения функций между модулями программного приложения должно быть определено соглашение форматов сообщений, что де-факто сформировалось на уровне стандартов коммуникации, которые определяют:
• на уровне СУБД:
— получение базой данных сообщений в виде команд на языке SQL но выполнению программных процедур или выполнения отдельных запросов,
— возврат результата обработки в форме сообщения простого типа данных или множества данных в форме массива, легко преобразуемого в плоскую (двумерную) таблицу;
• на уровне интерфейса пользователя:
— получение сформированного сообщения для визуализации в виде кода экранной формы, данных для отдельных элементов управления экранной формы, кода отчетной формы и т.д.,
— передача в обработку массива данных, введенных пользователем в элементы управления экранной формы.
На уровне интерфейса приложения происходит соответствующая обработка получаемых и передаваемых сведений для последующего использования в СУБД или пользовательском интерфейсе. Особенно такой подход очевиден для реализации wеЬ-приложения, где эти модули приложения в явном виде отделены друг от друга. Если рассматривается консольное приложение, работающее в виде клиентского и серверного приложения, то такое разделение не всегда очевидно, поскольку возможна реализация операций обработки как на серверном, так и на клиентском уровне. Тем не менее, этот подход к разделению модулей на три условно-независимых компонента также допустим, и он может быть реализован.
Именно такой подход к работе программного приложения позволяет разработчикам явно выделить обработку данных в СУБД, не задумываясь о вариантах реализации серверной обработки и пользовательского интерфейса. Достаточно знания о том, какие сообщения должны перемещаться между модулями программного приложения. Их структура и наполнение определяются теми элементами управления, которые используются в экранных формах. Именно это зачастую является основанием в принятии решения об использовании того или иного классификатора в базе данных.
Процесс же обработки данных, который представляется деревом связей функций, дает возможность выделить разные уровни выполнения операций: внутренний (уровень работы базы данных), внешний (уровень пользовательского интерфейса), промежуточный (уровень серверной обработки). При этом, надо понимать, что интерфейс пользователя определяет правила визуализации данных на экране пользователя, а интерфейс приложения — правила коммуникации пользователя с базой данных и не содержит элементов визуализации.