Виды и классификации ИПЯ
В зависимости от используемых компонентов ИПЯ бывают разных видов.
К числу первоначально использовавшихся видов ИПЯ Ч. Мидоу [13] относит виды, представленные на рис. 6.6:
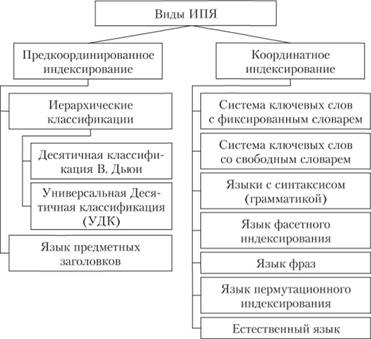
Рис. 6.6. Классификация ИПЯ по Ч. Мидоу
Иерархические классификации. Например, получившая широкое применение Десятичная классификация Дьюи [1], классификация библиотеки Конгресса США, Универсальная Десятичная классификация (УДК) [2], которая представляет собой модификацию системы Дьюи.
Иерархические классификации обеспечивают возможность расширения "вниз", т.е. уточнения описания документа, но они отличаются жесткостью, их достаточно трудно изменять.
• Язык предметных заголовков.
Подобно иерархической классификации использует фиксированное число предметных классов (часто располагаемых по алфавиту), но для его терминов обычно не используется определенный код. Язык позволяет любому документу приписывать более чем один термин, почти не имеет структуры и средств для выражения взаимоотношений между терминами. Предметные заголовки используются, например, в журналах (рубрики), классификаторах специальностей вузов и Высшей аттестационной комиссии (ВАК) при Минобрнауки России. Этот язык можно считать языком иерархической классификации, но с ослабленной структурой, что облегчает его разработку, но затрудняет изучение и применение.
Рассмотренные языки иногда называют предкоордииированнъши (pre-coordinate) системами, поскольку семантические комбинации терминов не определены в словарном составе ИПЯ, а составляются его разработчиками. Такие языки неизбежно имеют пробелы, в них трудно отражать новые предметные области (что легко видеть на примере системы УДК).
Поэтому для более совершенного описания содержания документа стало применяться индексирование ключевыми словами – координатное индексирование.
• Система ключевых слов с фиксированным словарем.
Такие языки могут применяться для узкоспециализированных ИПС с достаточно формализованной (унифицированной) терминологией (например, система "Унитерм", разработанная М. Таубе [3]). Эта система подобна системе предметных заголовков, но в отличие от нее, во-первых, ключевые слова короче предметных заголовков (обычно это единичные слова, иногда – короткие словосочетания) и, во-вторых, объем полного словарного состава существенно больше. Словарный состав здесь, как правило, фиксирован, и отсутствуют средства установления связей между словами (синтаксис), но включение набора слов в ПОД или ПОЗ позволяет пользователю как бы угадывать эти связи, что помогает более полно описать исходный документ или запрос.
• Система ключевых слов со свободным словарем.
Такие языки позволяют пользователю выбирать для описания документа любые слова (за исключением союзов и предлогов), руководствуясь их ролью в отображении содержания документа. Это позволяет точнее отобразить ОГЛАВЛЕНИЕ документа, но может снизить релевантность поиска, поскольку составители ПОЗ не могут предусмотреть точки зрения составителей ПОД.
• Языки с синтаксисом (грамматикой).
В качестве простейшего из ИПЯ этого вида Ч. Мидоу [13] выделяет язык помеченных дескрипторов (tagged descriptors), с помощью которого отображение смысла в ПОД и ПОЗ осуществляется путем присоединения к основному дескриптору (или ключевому слову) уточняющих дескрипторов (ключевых слов), роль которых состоит в том, чтобы либо классифицировать основной дескриптор как имя собственное, характерный признак или действие, либо объединить в одну группу дескрипторы, относящиеся к одному и тому же предмету документа. В современных поисковых системах Интернет применяются операции AND, OR, отображающие логические операции дизъюнкции и конъюнкции, в простейшем варианте – слова заключают в кавычки.
В дальнейшем были разработаны ИПЯ с грамматикой, содержащей более сложные правила.
• Язык фасетного индексирования.
В более развитых в синтаксическом отношении вариантах такого языка различные дескрипторы могут изменять значения друг друга. Простейшим примером такого синтаксиса является запись команды ЭВМ, состоящей из собственно оператора и адреса хранения информации. В качестве примера можно также привести уточненное описание товара, включая фасон, цвет, цену и тому подобные характеристики товара. Такой синтаксис основан на известном в теории множеств положении: в результате помещения рядом элементов разных множеств возникает эффект появления нового смысла. Языки такого вида позволяют частично устранять омонимию с учетом контекста.
Различные роли, которые играют дескрипторы в таких языках, называют фасетами [4]. Для фасет могут быть использованы дескрипторы из одного и того же словаря. Располагаются фасеты в порядке значимости дескрипторов для отображения содержания индексируемого документа. В отличие от иерархических классификаций фасеты можно располагать в произвольном порядке.
• Язык фраз.
В качестве ПОД используются индексирующие фразы. В этом случае контекст ключевых слов позволяет частично снять проблемы семантической неоднозначности.
Трудность здесь состоит в выборе фраз, включаемых в язык. Кроме того, отсутствует возможность расширения ПОД.
• Язык пермутационного индексирования.
Пермутационный указатель включает контекст каждого слова, содержащегося в фразе и называется указателем ключевых слов, взятых в контексте, или указателем типа KWIC [5].
Идею такого указателя легче пояснить примером:
Системы индексирования документов
Системы индексирования документов
Системы индексирования документов
При этом ПОД образует колонка ключевых слов в центре, расположенных в порядке алфавита. Можно считать этот ПОД фразой, но он эффективнее предыдущего с точки зрения смысловыражающих возможностей. Однако пермутационное индексирование трудоемко и неэффективно экономически.
• Естественный язык.
Наиболее точно может отразить семантику текста, однако помимо трудоемкости и экономической неэффективности возникают проблемы синонимии, омонимии и другой неоднозначности естественного языка, затрудняющие алгоритмизацию поиска.
Уменьшить неоднозначности языка помогает словарь.
В истории развития информационного поиска разрабатывались и применялись разнообразные словари: словарь синонимичных пар; словарь с многократными связями (например, двуязычный словарь); классификационная таблица; словарь с определениями на естественном языке; отрицательный словарь (содержащий запрещенные словосочетания); словарь-тезаурус ("Тезаурус ASTIA" [6] и др.).
Таким образом, существуют ИПЯ, использующие ключевые слова; дескрипторные ИПЯ без грамматики и с грамматикой, ИПЯ с отрицательным словарем, ИПЯ с тезаурусом и т.д.
Существуют и иные классификации ИПЯ.
Так, в [24, с. 31–36] предлагается следующее разделение ИПЯ (рис. 6.7):
1. Предкоординированные ИПЯ.
1.1. Перечислительные классификации: иерархические, алфавитно-предметные (по Мидоу – язык предметных заголовков).
1.2. Фасетные классификации.
2. Посткоординированные (координатные по Мидоу) ИПЯ.
2.1. Дескрипторные языки (с координацией посредством использования операции логического умножения или пересечения Ç).
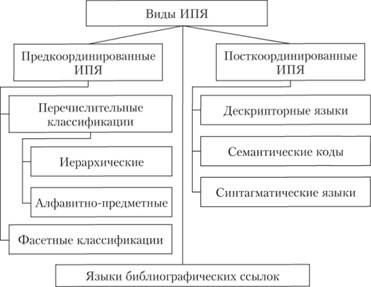
Рис. 6.7. Классификация ИПЯ А. И. Чёрного
2.2. Семантические коды, задающие парадигматические отношения структурами лексических единиц (код Перри – Кента [7], RX-коды языка "Бит" [8]).
2.3. Синтагматические языки с развитой системой средств отображения синтагматических отношений (см., например, язык СИНТОЛ [9]).
3. Языки библиографических ссылок.
Предлагались классификации ИПЯ по типу их словарного состава (см. ссылки в [24]), типам языковых единиц, степени их сложности, характеру отношений между этими единицами (виду грамматики), системам индексирования и т.п.
При этом следует иметь в виду, что на практике конкретный ИПЯ нельзя строго отнести к тому или иному классу, поскольку: во-первых, некоторые ИПС могут работать и в режиме без грамматики, и в режиме с грамматикой (например, системы СИНТОЛ [10], СМАРТ [11]); а во-вторых, ИПС развиваются, и основой является развитие ИПЯ. Поэтому обычно ИПС и ИПЯ описывают рядом характеристик с тем, чтобы пользователь мог выбрать желаемые.
При выборе ИПЯ необходимо оценивать их эффективность. При опенке эффективности ИПЯ используют различные критерии. Проблема оценки ИПЯ, в свою очередь, является составной частью более общей проблемы – оценки качества информационного поиска (см. 6.9).