Состав и работа РБД
Схема РБД может быть представлена в виде, показанном на рис. 10.2. В ней выделяют пользовательский, глобальный (концептуальный), фрагментарный (логический) и распределенный (локальный) уровни представления данных (рис. 10.3), определяющие сетевую СУБД [11].
Общий набор (система таблиц) данных, хранимых в РБД, приведен в табл. 10.1. Это глобальный уровень, который определяется при проектировании теми же методами, что и концептуальная модель централизованной БД.

Рис. 10.2. Схема РБД

Рис. 10.3. Уровни представления данных в РБД
Таблица 10.1
Данные в РБД (глобальный уровень)
а) Служащий
|
N |
Имя |
Завод |
Тариф |
|
100 |
Иванов |
1 |
6 |
|
101 |
Петров |
1 |
6 |
|
102 |
Сидоров |
2 |
10 |
|
103 |
Артемов |
2 |
12 |
|
104 |
Печкин |
3 |
5 |
|
105 |
Крамов |
3 |
11 |
б) Завод
|
N |
Расположение |
|
1 |
С.-Петербург |
|
2 |
Вологда |
|
3 |
Сыктывкар |
в) Сырье
|
N |
Название |
Количество |
|
1 |
Картон |
500 |
|
2 |
Картон |
100 |
|
2 |
Открытки |
940 |
|
3 |
Брошюры |
75 |
В табл. 10.1 разными шрифтами выделены фрагменты БД.
Не все данные глобального уровня доступны конкретному пользователю. Наиболее полные данные (пользовательский, внешний уровень) имеются в узле 1 головного предприятия. В узлах (участках) 2, 3 данные менее полные. Так, в узле 3 они имеют вид, показанный в табл. 10.2.
Таблица 10.2
Пользовательский уровень в РЕД
а) Служащий
|
N |
Имя |
Завод |
Тариф |
|
104 |
Печкин |
3 |
5 |
|
105 |
Крамов |
3 |
11 |
б) Завод
|
N |
Расположение |
|
1 |
С.-Петербург |
|
2 |
Вологда |
|
3 |
Сыктывкар |
в) Сырье
|
N |
Название |
Количество |
|
3 |
Брошюры |
75 |
Пользовательский уровень состоит из фрагментов (например, строки 1, 2, 3 таблица "Завод" табл. 10.1) глобальною уровня, которые составляют фрагментарный, логический уровень.
Выделяют горизонтальную и вертикальную фрагментации (расчленение). Горизонтальная фрагментация связана с делением данных по узлам. Горизонтальные фрагменты нс перекрываются. Вертикальная фрагментация связана с группированием данных по задачам.
Фрагментация чаще всего не предполагает дублирования информации в узлах. В то же время при размещении фрагментов по узлам (локализации) распределенного уровня в узлах разрешается иметь копии той или иной части РБД. Так, например, локализация для примера в табл. 10.1 может иметь вид, показанный в табл. 10.3.
Таблица 10.3
Локализация данных
|
Имя таблицы |
Распределение фрагментов по узлам |
|
Служащие |
1 |
|
1. 2 |
|
|
1. з |
|
|
Завод |
1, 2, 3 |
|
I, 2, 3 |
|
|
1, 2, 3 |
|
|
Сырье |
1 |
|
2 |
|
|
3 |
Очевидно, что для таблицы "Завод" осуществляется дублирование, а для таблицы "Сырье" – расчленение.
После размещения данных каждый узел имеет локальное, узловое представление (локальная логическая модель). Физическую реализацию (логического) фрагмента называют хранимым фрагментом.

Рис. 10.4. Схема работы РБД
Иначе говоря, РБД можно представить в виде, показанном на рис. 10.3.
Сеть в РБД образуют сетевые операционные системы (например, Windows NT, Novell NetWare). В качестве СУБД, изначально предназначавшихся для использования в сети, следует назвать BTrieve, Oracle, InterBase, Sybase, Informix.
В силу распределенности данных особую значимость приобретает словарь данных (справочник) РБД, который в отличие от словаря централизованной БД имеет распределенную, многоуровневую структуру.
В общем случае могут быть выделены сетевой, общий внешний, общий концептуальный, локальные внешние, локальные концептуальные и внутренние составляющие словаря РБД.
Естественно, что для работы в РБД необходимы администраторы РБД и локальных БД, рабочими инструментами которых являются перечисленные словари.
Схема работы РБД показана на рис.
10.4.
Пользовательский запрос, определяемый приложением, поступает в систему управления распределенной базы данных (СУРБД), через сетевую и локальную операционные системы попадает в локальную СУБД. Если запрос связан с локальными данными, СУБД осуществляет вызов данных из локальной БД, которые поступают пользователю. Если часть данных для выполнения приложения находится в другой локальной БД, локальная СУБД дополнительно через локальные и сетевую операционные системы осуществляет удаленный вызов процедуры (Remote Procedure Call – PRC), после выполнения которой данные передаются пользователю.
Возможны четыре стратегии хранения данных: централизованная (часто обеспечиваемый архитектурой клиент–сервер), расчленение (фрагментации), дублирование, смешанная.
Сравнительные характеристики стратегий хранения приведены в табл. 10.4. На ее основе может быть построен простейший алгоритм выбора стратегии, приведенной на рис. 10.5.
Таблица 10.4
Стратегии хранения данных
|
Название |
Суть стратегии |
Достоинство |
Недостатки |
|
Централизация (в том числе технология клиент- сервер) |
Единственная копия в одном узле |
Простота структуры |
Скорость обработки ограничена одним узлом Ограниченный доступ Малая надежность Долговременная память определяет объем БД |
|
Локализация (расчленение) |
Единственная копия, расчленение по узлам (полная копия БД не допускается) |
Объем БД определяется памятью сети Снижение стоимости РБД Время отклика при параллельной обработке уменьшается Малая чувствительность к узким местам Повышенная надежность при высокой локализации данных |
Запрос может быть по всем узлам Доступ хуже, чем при централизации Рекомендация применения: долговременная память ограничена по сравнению с объемом БД; должна быть повышена эффективность функционирования при высокой степени локализации |
|
Дублирование |
В каждой локальной БД полная копия |
Выше надежность, доступ и эффективность выборки, простота восстановления. Локальная асинхронная обработка в узлах Получение быстрых ответов |
Объем БД ограничен долговременной памятью Потребность синхронизации многих копий Потребность в дополнительной памяти Слабая реализация параллельной обработки Рекомендации применения: фактор надежности превалирует; БД невелика; интенсивность обновления невысока; интенсивные запросы |
|
Смешанная |
Несколько копий хранимого логического фрагмента в каждом узле |
Любая степень надежности Большая доступность Меньше пересылок данных Параллельная обработка |
Надо хранить словари Рост стоимости согласования данных Разная частота обращения узла к различным частям БД Потеря надежности из-за расчленения данных Малая свободная долговременная память из-за дублирования |
Отметим, что в обычной сети имеет место равноправие компьютеров, что может вызвать дополнительные осложнения в части доступа к данным в процедурах обновления и запросов.

Рис. 10.5. Алгоритм выбора стратегии хранения:
А – запрос локален
В связи с этим часто используют архитектуру клиент-сервер (рис. 10.6) – структуру локальной сети, в которой применено распределенное управление сервером и рабочими станциями (клиентами) для максимально эффективного использования вычислительной мощности.
В этой структуре один из компьютеров, имеющий самый большой объем памяти и наиболее высокое быстродействие, становится приоритетным, называемым сервером. На сервере чаще всего хранятся только данные, запрашиваемые клиентами.
К клиентам не предъявляются столь жесткие требования по памяти и быстродействию. На них располагаются словари и приложения, служащие своеобразными фильтрами для данных сервера. В связи с этим обмен информацией в архитектуре (рис. 10.6) фактически минимизируется.
Работа в архитектуре клиент-сервер может поддерживаться и с помощью схемы Open DataBase Connectivity (ODBC), как показано на рис. 10.7. В этом случае сеть образуется путем соединения серверов. Такое соединение обеспечивается или средствами СУБД (SQL Server) или мониторами транзакций (TUXEDO).
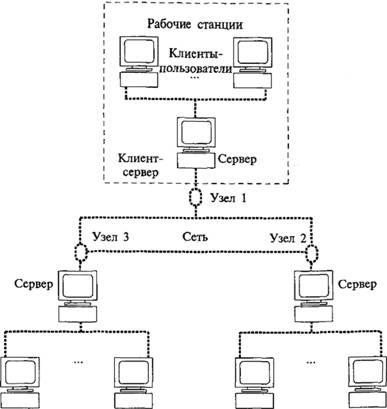
Рис. 10.6. Архитектура клиент-сервер
Обсудим более подробно вариант реализации РБД – архитектуру клиент-сервер.

Рис. 10.7. ODBC в архитектуре клиент-сервер
Совместно с термином "клиент-сервер" используются три понятия.
1. Архитектура: речь идет о концепции построения варианта РБД.
2. Технология: говорят о последовательности действий в РБД.
3. Система: рассматриваются совокупность элементов и их взаимодействие.
Об архитектуре клиент-сервер говорилось ранее.
Технология клиент-сервер позволяет повысить производительность труда:
• сокращается общее время выполнения запросов за счет мощного сервера;
• уменьшается доля и увеличивается эффективность использования клиентом (для вычислений) центрального процессора;
• уменьшается объем использования клиентом памяти "своего" компьютера;
• сокращается сетевой трафик.
К таким крупномасштабным системам предъявляются следующие требования: I) гибкость структуры; 2) надежность; 3) доступность данных; 4) легкость обслуживания системы; 5) масштабируемость приложений; 6) переносимость приложений (на разные платформы); 7) многозадачность (возможность выполнения многих приложений).
Отметим, что архитектуре клиент-сервер предшествовала архитектура файл-сервер, в которой возможны следующие варианты.
1. На компьютерах-клиентах имеется копия БД. Работа по такому варианту имеет следующие сложности: синхронизация данных различных копий в конце работы БД; высокий трафик (потоки данных между сервером и клиентами, поскольку передается в любом случае содержимое всей БД).
2. В СУБД Access, которая изначально создана как локальная, предусмотрен режим деления базы данных. Таблицы остаются на сервере (back-end), а остальные объекты (запросы, отчеты) передаются клиентам (front-end). В этом случае по-прежнему большой трафик, в силу чего при использовании файл-серверов количество подключаемых клиентов – при их надежной работе – до четырех.
В то же время требовалось подключение десятков и даже сотен клиентов [1-3]. Этого удалось достичь в архитектуре (режиме, технологии) клиент-сервер. В этом режиме трафик резко уменьшается, поскольку по сети передаются только те данные, которые соответствуют запросам клиентов [2].
Для этого пришлось построить СУБД, изначально предназначенные для работы в сети. Фирма Microsoft [27-29] вынуждена была – в дополнение к СУБД Access, которая использовалась с помощью приложения ODBC только для клиентских целей – предложить в качестве сервера Microsoft SQL Server. Такая структура оказалась тяжеловесной и неудобной, так как разработчику требовалось знать уже две СУБД.
Из других предложений очень удачным оказался программный продукт Delphi [30-36], в рамках которого могут использоваться СУБД dBase, Paradox, и, при отдельной инсталляции, InterBase (режим клиент-сервер). При этом СУБД InterBase поддерживается, наряду с языком программирования SQL, мощным, понятным, простым и широко распространенным языком программирования (Object) Pascal [11], построенным с применением объектно-ориентированного подхода [33].
Последнее обстоятельство позволяет легко строить объектно-реляционные базы данных (см. гл. 9). Высокая степень автоматизации программирования дает возможность резко упростить и снизить трудоемкость процедур создания интерфейса пользователя, и особенно алгоритма приложения.
В системе клиент-сервер возможно выделить следующие составляющие: сервер, клиент, интерфейс между клиентом и сервером, администратор.
Сервер осуществляет управление общим для множества клиентов ресурсом. Он выполняет следующие задачи:
• управляет общей БД;
• осуществляет доступ и защиту данных, их восстановление;
• обеспечивает целостность данных.
К БД на сервере предъявляются те же требования, как и к централизованной многопользовательской БД.
Следует отметить, что результаты запросов клиента помещаются в рабочую область памяти сервера, которая в ряде СУБД (например, Oracle) называют "табличная область". Поскольку она не занимает много места, для каждого клиента-пользователя целесообразно создавать свою табличную область. В этом случае исходные таблицы становятся для пользователя недоступными, а архивация (копирование) БД приложения клиента упрощается.
Клиент хранит в компьютере свои приложения, с помощью которых осуществляется запрос данных на сервере. Клиент решает следующие задачи:
• предоставляет интерфейс пользователю;
• управляет логикой работы приложений;
• проверяет допустимость данных;
• осуществляет запрос и получение данных с сервера.
Средством передачи данных между клиентом и сервером является сеть (коаксиальный кабель, витая пара) с сетевым (сетевая операционная система – СОС) и коммуникационным программным обеспечением.
В качестве СОС могут использоваться Windows NT, Novell NetWare. Коммуникационное программное обеспечение позволяет компьютерам взаимодействовать на языке специальных программ – коммуникационных протоколов.
В общем случае такое взаимодействие осуществляется с помощью семиуровневой схемы ISO с соответствующими протоколами. Для локальных сетей схема упрощается. Протоколоми для Windows NT служит Transmission Control Program/Internet Program (TCP/IP), для NetWare – Sequenced Packed eXchange/Intemet Packed eXchaned (SPX/IPX).
Разнообразие сетевых средств делает необходимым создание стандартного промежуточного программного обеспечения клиент-сервер, находящегося на сервере и клиентах. Говорят о прикладном программном интерфейсе (Application Programming Interface – API). Сюда относятся Open DataBase Connectivity (ODBC) и Integrated Database Application Programming Interface (IDAPI), используемый в приложении Delphi и СУБД InterBase.
Взаимодействие клиентов и сервера можно представить себе следующим образом.
При обращении пользователя к приложению компьютер-клиент запрашивает у пользователя имя и пароль. После этого – при правильном ответе – приложение может быть запущено клиентом. Приложение дает возможность подключиться к серверу, которому сообщается имя и пароль пользователя.
Если подключение осуществлено, начинает работать сервер, выполняющий два вида процессов: переднего раздела и фоновые.
Процессы переднего раздела непосредственно обрабатывают запросы, фоновая составляющая связана с управлением процессом обработки.
Работа сервера может иметь такой порядок.
1. После поступления запроса диспетчер ставит его в очередь по схеме "первым пришел – первым обслужен".
2. Процесс переднего раздела выбирает "самый старый" запрос и начинает его обработку. После завершения результаты помещаются в очередь для передачи клиенту.
3. Диспетчер посылает результаты из очереди соответствующему клиенту.
При обработке запроса фоновые процессы выполняют другие важные операции, основными из которых являются следующие:
• запись данных из БД в промежуточную (буферную) память рабочей области (при чтении) и обратно (при обновлении);
• запись в журнал транзакций;
• архивация (копирование) групп транзакций;
• аварийное завершение транзакций;
• периодическая запись на диск контрольных точек для обеспечения восстановления данных в РБД после аппаратного сбоя.
Администратор РБД (АРБД) должен решать следующие задачи [39].
1. Планирование РБД и распределение памяти.
2. Настройка конфигурации сети.
3. Создание РБД.
4. Работа с разработчиками приложений.
5. Создание новых пользователей и управление полномочиями.
6. Регулярная архивация БД и выполнение операций по ее восстановлению.
7. Управление доступом к БД с помощью ОС и СОС, средств защиты и доступа.
В больших системах AРБД может состоять из ряда лиц, отвечающих, например, за ОС, сеть, архивацию, защиту.
Таким образом, система клиент-сервер своеобразна: с одной стороны, ее можно считать разновидностью централизованной многопользовательской БД, с другой стороны, она является частным случаем РБД.
В связи с этим имеется специфика и в процессе проектирования. Оно по-прежнему начинается с создания приложения, затем – интерфейса и БД. Однако в силу специфики системы этапы фрагментации и размещения отсутствуют и есть свои особенности.
Основное ограничение для работы такой системы – минимальный трафик. Поэтому при разработке приложения, помимо обычных задач (уяснения цели приложения, логики обработки, вида интерфейса) особое внимание следует обратить на разработку DLL- сценария и распределение функций между клиентами и сервером.
Использование для составления сценария CASE-средств значительно сокращает трудоемкость работ по проектированию. Иначе эта процедура выполняется вручную с помощью команд языка SQL.
Важнейшей является задача распределения функций. По самой сути технологии на сервере расположена БД, а на компьютерах- клиентах – приложения. Однако при прямолинейных процедурах обеспечения целостности и запросах в сети может возникнуть объемный сетевой трафик.
Чтобы его снизить, возможно использовать следующие рекомендации.
1. Обеспечение целостности для всех приложений лучше централизовать и осуществлять на сервере. Это позволит не только сократить трафик, но и рационально использовать СУРБД, улучшив управление целостностью (ссылочной, ограничений, триггеров) данных.
2. Целесообразно использовать на сервере хранимые процедуры, совокупность которых можно инкапсулировать в виде пакета (модуля). В результате трафик уменьшится: клиент будет передавать только вызов процедуры и ее параметры, а сервер – результаты выполнения процедуры.
3. В ряде случаев клиентам следует получать уведомления базы данных (например, заведующему складом – о нижнем уровне запасов, при котором следует выполнять новый заказ). Если уведомление производится по запросу клиента, трафик увеличивается. Проще эту (хранимую) процедуру разместить на сервере, который будет автоматически уведомлять клиента о возникновении события. В то же время клиент при необходимости может получать информацию с помощью простых вызовов процедур.
В режиме клиент-сервер выделяют две разновидности структуры: одноуровневую, о которой шла речь до сих пор, и многоуровневую (рис. 10.8).
При использовании режима "толстого" клиента (одноуровневая структура) клиентские приложения находятся непосредственно на машинах пользователей, либо частично на сервере в виде системы хранимых процедур. Сложность клиентской части порой требует ее
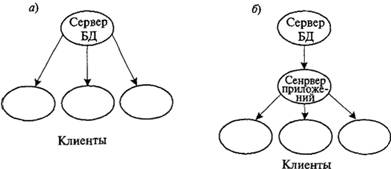
Рис. 10.8. Одноуровневая – "толстый" клиент (а) и многоуровневая – "тонкий" клиент (б) структуры клиент-сервер
администрирования. Использование системы хранимых процедур в значительной мере снижает нагрузку на сеть. При использовании "тонкого" клиента (многоуровневая структура) приложения пользователей лежат и выполняются на отдельном мощном сервере (сервере приложений, который может быть и на одном компьютере с сервером БД), что в значительной мере снижает требования к пользовательским машинам.
Так, в СУБД InterBase в одноуровневой структуре в каждом клиенте имеется утилита Borland Database Engine (BDE – ядро Delphi) объемом 8 Мбайт. В многоуровневой структуре BDE-утилита имеется только в сервере приложений, а объем памяти, занимаемой клиентом, снижается до 212 кбайт. Достигается этот результат за счет усложнения структуры.