Системы индексирования
Процедуру перевода с естественного языка на ИПЯ называют индексированием [1]. Результатом такого перевода является ПОД (при вводе документов в ИПС) или ПОЗ (при индексировании запроса пользователя).
Проблема индексирования связана с семантическим анализом текстов документов. Сложность ее связана с тем, что индексирование документов, вводимых в поисковые массивы, и запросов пользователя разнесены во времени.
Для алгоритмизации и автоматизации индексирования необходимо решить проблему выбора для включения в ПОД или ПОЗ наиболее значимых ключевых слов, дескрипторов, фраз (в зависимости от лексических единиц ИПЯ).
Важность можно определить несколькими признаками:
• статистическими, т.е. на основе частоты использования термина в документе;
• на основе высказываний автора (его мнения, отраженного в заглавии документа или подзаголовках, выделяемых автором в документе);
• с помощью грамматики, позволяющей отразить взаимосвязи между лексическими единицами, содержащимися в контексте;
• по критериям важности, сформулированным пользователем, для чего при индексировании документов могут быть указаны весовые коэффициенты дескрипторов.
Система индексирования конкретной ИПС определяется в основном возможностями ИПЯ, имеющимися в нем лексическими и синтаксическими средствами. Однако есть и некоторые специфические правила и рекомендации, исследование которых позволило выявить некоторые разновидности систем индексирования.
Существуют различные типы систем индексирования.
1. К первому типу относят системы свободного индексирования.
При этом способе из индексируемого документа выписываются в ПОД слова или словосочетания, которые отражают ОГЛАВЛЕНИЕ индексируемого документа. Кроме этого, элементами ПОД могут быть слова, отсутствующие в этих документах, но отражающие более точно смысл их текстов с точки зрения целей создания ИПС. Выписанные элементы упорядочиваются в алфавитном порядке. Такой упорядоченный набор слов (словосочетаний) представляет собой ПОД при этом типе индексирования. Аналогично – из текста запроса пользователя формируется ПОЗ.
Такой процесс индексирования является принципиально неалгоритмическим, т.е. неавтоматизируемым.
2. При втором методе, который условно называют методом полусвободного индексирования, из документа выписывают слова и словосочетания вначале так же, как и при свободном индексировании.
Однако выписанные элементы сравнивают затем с фиксированным словарем, не найденные в нем – устраняют, а оставшиеся, упорядочиваемые в алфавитном порядке, представляют собой ПОД (или ПОЗ).
3. Третий способ индексирования основан на статистическом подходе.
Выбор слов (выражений) исходного текста, подлежащих включению в ПОД, производится на основе статистического анализа текста, при котором его слова рассматриваются как знаки, не имеющие семантических значений. При этом предлагались различные статистические критерии, основанные на сопоставлении относительной частоты употребления слова в документе и относительной частоты употребления слова в представительном массиве документов (т.е. в репрезентативной статистической выборке).
Например, в [14] предлагаются следующие количественные критерии:
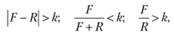
где F – относительная частота употребления слова в документе; R – относительная частота употребления слова в представительном массиве документов.
Легко видеть, что в основе приведенных соотношений лежит идея, согласно которой информационная значимость слова определяется расхождением частоты его употребления в данном документе и во всем потоке рассматриваемых документов.
Возможны различные подходы к определению расхождения:
• согласно первому вычисляется расхождение между частотой употребления слов в потоке документов данной тематики (монотематический поток) и частотой встречаемости этого слова в многотемном потоке документов (политематический поток);
• второй принцип основан на вычислении расхождения частоты употребления слова в потоке текстов данной тематики и частоты этого же слова в потоке текстов тематики, далекой от данной ("противоположной" тематики).
Статистический способ индексирования может быть алгоритмизирован и автоматизирован, и в настоящее время имеются средства автоматизированного статистического анализа текстов.
Однако самостоятельного практического применения в ИПС этот способ не нашел, он используется как вспомогательный в сочетании с семантическим анализом текстов документов.
4. К четвертому типу относят системы индексирования, контролируемые заданным словарем (тезаурусом).
Алгоритм индексирования сводится к тому, что каждое слово текста сравнивается с точностью до основы со словарем, совпавшие слова записываются в ПОД.
В некоторых системах словарь используется как помощник специалисту, занимающемуся индексированием текста.
К таким системам относится, например, УДК. В других – такой словарь является элементом алгоритма индексирования: слово, одновременно встретившееся в тексте и в словаре, записывается в ПОД. В дескрипторных ИПЯ в ПОД
(ПОЗ) записываются не само слово текста, а соответствующий ему дескриптор.
Перспективным представляется индексирование документов с использованием специально разработанных иерархических классификаций, отражающих цели поиска и использования документов.
Такие классификаторы могут использоваться в качестве ИПЯ в информационных системах нормативно-методического обеспечения управления: иерархический классификатор, объединяющий нормативно-методические документы, разрабатывается на основе структуры целей (основных направлений) и функций деятельности предприятия.
Иерархический классификатор ИПЯ может быть основой системы избирательного распределения информации (ИРИ): разрабатывается классификатор потребностей категории работников, пользующихся системой ИРИ.