Сетевая модель
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 3.2). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).

Рис. 3.2. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: "запись" и "связь". Тип "связь" определяется для двух типов "запись": предка и потомка. Переменные типа "связь" являются экземплярами связей.
Сетевая БД (например, IDS) состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины (например такие, как элементы и агрегаты данных, записи, наборы, области и т.д.).
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
• поиск записи в БД;
• переход от предка к первому потомку;
• переход от потомка к предку;
• создание новой записи;
• удаление текущей записи;
• обновление текущей записи;
• включение записи в связь;
• исключение записи из связи;
• изменение связей и т.д.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатками сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
Реляционная модель
Реляционная модель данных (РМД) предложена сотрудником фирмы IBM Эдгаром Коддом в начале 1970-х гг. и основывается на понятии "отношение" {relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица (рис. 3.3). Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам – атрибуты отношения (домены).
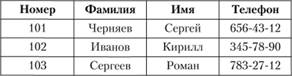
Рис. 3.3. Реляционное представление данных
Таким образом, реляция – это название в математике двумерной таблицы, состоящей из строк и столбцов данных.
Значение атрибута-идентификатора (различителя) для конкретной записи называется ключом записи. В некоторых случаях ни один атрибут не может быть использован в качестве ключа. В этом случае в качестве ключа используется комбинация атрибутов. Единственное требование к этой комбинации атрибутов, чтобы они однозначно выделяли (идентифицировали) конкретные объекты. В этом случае ключ называется составным. Если же ключ состоит из одного атрибута, то его называют простым.
В каждом типе записи может быть несколько вариантов ключей, и в этом случае они называются возможными ключами. Один ключ, конкретно выбранный из возможных, принято называть первичным (или внутренним) ключом.
Атрибуты называются внешним ключом, если они являются внутренним (первичным) ключом любой другой реляции, Одним из фундаментальных понятий теории реляционных БД является понятие нормализации. Единственными отношениями, допустимыми в РМД, являются те, которые удовлетворяют следующему условию: каждое значение в отношении, т.е. значение каждого атрибута в каждом кортеже, должно быть атомарным (единственным), т.е. на пересечении любой строки и любого столбца и в таблице должно быть только одно значение, а не множество значений.
Если значение атрибута/1 в кортеже однозначно определяет значение другого атрибута/} в этом же кортеже, то считается, что между этими атрибутами имеет место функциональная зависимость. Это означает, что если два кортежа в реляции имеют одно и то же значение, то они имеют одно и то же значение функционально зависимого от них атрибута В.
Эта зависимость записывается в виде
ФЗ: А → В.
Атрибуты в левой части функциональной зависимости называются детерминантом. Понятие функциональной зависимости (ФЗ) применимо к реляциям, у которых имеется составной внутренний ключ. Следует заметить, что внутренний ключ всегда является детерминантом (по определению ключа).
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и пр.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
В логической структуре массива данных указываются возможные логические связи между отдельными типами записей. Могут иметь место следующие варианты связей:
• один к одному (1:1):
• один ко многим (1: N);
• многие ко многим (N: М).
Вариант 1: 1 определяет такую связь между типами записей, когда с каждым типом записи А связан только один тип записи В и наоборот. Примером такой связи типов записей является связь "автомобиль" – "владелец автомобиля".
Вариант 1: N указывает, что с каждым типом записи А может быть связано множество N типов записей В. Примером такой связи типов записей является связь "факультет" – "кафедра".
Вариант N: М указывает, что с каждым типом записи А может быть связано множество М типов записей В и, наоборот, с каждым типом записи В может быть связано множество N типов записи А. Примером такой связи является связь "студент" – "учебный курс".
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство РМД заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной широкого использования данной модели данных.
Основными недостатками РМД являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.