Расширенные ОРБД
К расширенным ОРБД относится СУБД Informix Universal Server [41,42]. С помощью этой разновидности ОРБД решают две группы задач: 1) хранение в БД данных большого объема; 2) трансформация реляционной модели (собственно БД) в объектно-реляционную модель данных.
Обсудим состояние решения этих задач.
Задача 1. Первоначально графические базы данных создавались так: отдельно формировались графические файлы, а в столбцах СУБД были лишь ссылки на эти файлы. Это требовало от программиста знания не только БД, но и системы файлов. В связи с этим в состав СУБД были первоначально введены "простые большие объекты" (рис. 8.6) TEXT и BYTE с объемом до 1 Гбайт.
Вскоре выяснилось, что и такая размерность поля порой недостаточна, и были созданы интеллектуальные большие объекты Binary Large Object (BLOB) и CLOB размером до 4 Тбайт. Работа с такими объектами возможна только "по частям", для чего пришлось создать специальные дополнительные технологии.
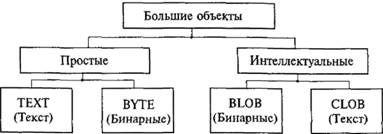
Рис. 8.6. Большие объекты
Задача 2. Идею расширения (системы данных) удобно иллюстрировать на примере [41] программы (среда Delphi, язык Object Pascal):
unit polimor_;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs,
StdCtrls;
type
TForml = class(TForm)
Editl: TEdit;
Edit2: TEdit;
GroupBoxI: TGroupBox;
RadioButtonl: TRadioButton;
RadioButton2: TRadioButton;
Label 1: TLabel;
Label2: TLabel;
Button1:TButton;
Button2:TButton;
procedure Button 1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
private
{ Private declarations}
public
{Public declarations}
end;
type
TPerson=class
fname:string;{имя}
constructor Create(name:string);
function info:string; virtual;
end;
TStud=class(TPerson)
fgrrinteger; {номер группы} constructor Create(name:string;gr:integer); function infoistring; override;
end;
TProf=class(TPerson)
fdep:string; {название кафедры}
constructor Create(name:string;dep:string);
function info:string; override;
end;
const
SZL=10; // размер списка
var
Forml: TFormt;
List: array[1 ..SZL] of TPerson; // список
n:integer; // кол-во людей в списке
implementation
{$R*.DFM}
constructor TPerson.Create(name:string);
begin
fname:=name;
end;
constructor TStud. Create( name :string ;gr: integer);
begin
inherited create(name);
fgr:=gr;
end;
constructor TProf.create(name:string; dep:string);
begin
inherited create(name);
fdep:=dep;
end;
function TPerson.lnfo:string;
begin
result:=fname;
end;
function TStud.lnfo:string;
begin
result:=fname+'гр .' +lntT oStr(fgr);
end;
function TProf.lnfo:string;
begin
result:=fname+'каф .'+fdep;
end;
procedure TForml .Button1Click(Sender: TObject);
begin
if n<=SZL then begin
if Radiobutton 1 .Checked
then // создадим объект TStud
List[n]:=TStud.Create(Edit1.Text,StrTolnt(Edit2.Text))
else
List[n]:=TProf.Create(Edit1.Text,Edit2.Text);
n:=n+1;
end
else ShowMessage('Список заполнен!');
end;
procedure TForml .Button2Click(Sender: TObject);
var
i: integer;
st: string;
begin
for i:=1 toSZL do
if list[i] <> NIL then st:=st+list[i].info+# 13;
ShowMessage('Список'+# 13+st);
end;
end.
Из нее видно, что классы "Студент" (TStud) и "Профессор" (TProi) являются производными от класса "Личность" (TPerson). В качестве
методов доступа к ним выступают функции TStud.Info.string, TProf.Info.string и TPerson.lnfo.string соответственно.
Язык программирования Object Pascal редко используется для формирования объектно-ориентированной модели базы данных. Чаще для этих целей применяют языки С++ и SQL.
Покажем на примерах использование языка SQL3 в СУБД Informix Universal Server.
В SQL3 используются те же типы данных, что и в SQL2. Однако SQL3 оперирует не таблицами, как SQL2, а объектами. В качестве таких объектов выступают новые (абстрактные) типы данных и система таблиц, образующих иерархию.
А. Абстрактные типы данных (рис. 8.7). Абстрактные типы данных, получившие в последнее время название "типы данных, определяемые пользователем" [2], – типы, задающие характеристики [3], но не реализации, наследуемые подтипом. Они непосредственно не порождают экземпляров.
В иерархии типов участвуют (рис. 8.7) ROW (неименованные строки), ROW TYPE (именованные строки), SET (неупорядоченный набор одного типа без повторения данных), MULTISET (то же, что и SET, с возможностью повторения данных), LIST (упорядоченный набор неуникальных данных одного типа, фактически – одномерный массив). Разнородные структуры добавляют каждый раз по одной строке к предыдущей строке, тогда как однородные структуры могут добавлять по нескольку строк к каждой предыдущей строке.
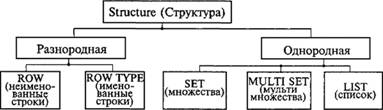
Рис. 8.7. Новые абстрактные типы данных
Использование новых типов рассмотрим на системе таблиц, показанных на рис. 8.8. Иерархия требует множественного наследования. Поскольку оно не реализовано в рамках СУБД Informix Universal Server, ограничимся рассмотрением части иерархии, обведенной на рис. 8.8 пунктиром.
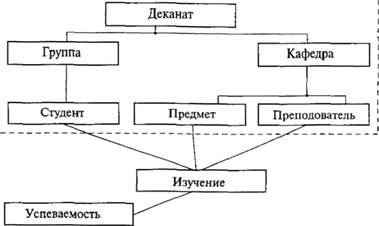
Рис. 8.8. Иерархия абстрактных типов данных и таблиц
Речь должна пойти о построении типов данных, их заполнении и обновлении. Первоначально покажем использование типа данных ROW для элементов иерархии "Деканат", "Группа", "Студент", "Кафедра". Для иллюстрации в каждом структурном элементе используем только по два поля, а названия таблиц и полей выполним на русском языке.
CREATE ROW TABLE Деканат(
Шифр_деканата integer,
Название varchar( 15),
Группа ROW(
Шифр_группы varchar(8),
Название_группы varchar(5),
Студент ROW( Шифр_студента varchar(8),
Фамилия varchar( 15)),
Кафедра ROW(
Шифр_кафедры integer,
Название_кафедры varchar{50))
);
Выборка данных осуществляется следующим образом.
SELECT шифр_деканата, группа.название_группы, группа.студент.фамилия
FROM Деканат
WHERE группа.название_группы='И5';
Заполнение (вставка) в такую структуру проводится так:
INSERT INTO Деканат
VALUES (1/ПТИО',
ROW('И-99', 'И4',
ROW('И-99/15', 'Петров')),
ROW(1, 'ИиУС'));
В типе данных ROW структура строки (записи) каждый раз должна определяться отдельно. Это не позволяет использовать структуру ROW многократно.
Такую возможность предоставляет именованная запись ROW TYPE. В этом случае Назад структура "Деканат" задается иначе.
Первоначально формируются именованные записи.
CREATE ROW TYPE Студент_TYРЕ(
Шифр_студента varchar(8),
Фамилия varchar( 15)
);
CREATE ROW TYPE Гpyппa_TYPE(
Шифр_группы varchar(8),
Название_группы varchar(5),
Студент Студент_ТУРЕ
);
CREATE ROW TYPE Кафедра_TYPE(
Шифр_кафедры integer,
Название_кафедры varchar(50)
);
Из именованных записей составляется структура "Деканат"
CREATE ROW TABLE Деканат(
Шифр_деканата integer,
Название varchar( 15),
Г руппа Гpyппa_TYPE,
Кафедра Кафедра TYPE
);
При этом сформируется таблица с нелинейной структурой (табл. 8.1).
Таблица 8.1
Сформированная таблица "Учебный процесс"
|
Шифр деканата |
Название деканата |
Группа |
Студенты |
Кафедра |
|||
|
Шифр группы |
Название группы |
Шифр студента |
Фамилия |
Шифр кафедры |
Название кафедры |
||
|
1 |
ПТиО |
И-99 |
И4 |
И-99/12 |
Петров |
1 |
ИиУС |
|
1 |
ПТиО |
И-99 |
И4 |
И-99/11 |
Смирнов |
1 |
ИиУС |
|
... |
... |
... |
... |
... |
... |
... |
... |
Можно таблицу построить и другим способом.
CREATE ROW TYPE Деканат_ТУРЕ(
Шифр_деканата integer,
Название varchar( 15),
Группа Гpynna_TYPE,
Кафедра Кафедра_ТУРЕ
);
и
CREATE TABLE Деканат OF TYPE Деканат_ТУРЕ;
Последняя таблица получила название типизированной. Заметим, что при вставке в тип ROW проблем не возникает:
INSERT INTO Деканат
VALUES (','ПТИО',
ROW('И-99', 'И4',
ROW('И-99/15',
'Петров')::Студент_ТУРЕ)::Группа_Туре,
ROW( 1, 'ИиУС')::Кафедра_ТУРЕ);
где знак :: обозначает перевод записи в элемент ROW.
Операторы заполнения ROW TYPE сложнее, чем ROW, и требуют написания хранимых процедур или функций. Например, список групп в деканате формируется следующим образом:
CREATE FUNCTION Список_групп(Деканат.ГpyппaTYPE)
RETURNS(varchar(8), varchar(5)) AS
RETURN(группа.Шифр_группы, Группа.Название_группы)
END FUNCTION;

Рис. 8.9. Иерархия абстрактных типов данных (наследование)
Таблицу "Преподаватель" на рис. 8.8 временно заменим на таблицу "Работающий", подразумевая, что преподаватель одновременно и преподаватель, и (научный) сотрудник (рис. 8.9).
CREATE ROW TYPE адрес_ТУРЕ(
Город varchar(15),
Улица varchar(15),
Дом integer,
Корпус integer,
Квартира integer
);
CREATE ROW TYPE Работающий_ТУРЕ(
Шифр_работающего integer,
Фамилия varchar( 15),
Адрес адрес_ТУРЕ
);
В составе "Работающий" имеются подчиненные ему элементы "Преподаватель" и "Сотрудник". Тогда иерархия подчинения (наследования) типов данных формируется так:
CREATE ROW TYPE Преподаватель_ТУРЕ(
Дисциплина varchar(20),
Вид_занятий varchar(10),
UNDER Работающий TYPE;
CREATE ROW TYPE Сотрудник_ΤΥΡΕ(
Шифр_работы varchar(5),
Название работы varchar(40),
UNDER Работающий_TYРЕ;
Тогда типизированные таблицы имеют вид:
CREATE TABLE Преподаватель OF TYPE Преподаватель_ТУРЕ;
CREATE TABLE Сотрудник OF TYPE Сотрудник_ТУРЕ;
Два последних определения могут включать и внешние ключи.
Фактически сформирована система таблиц. Она отличается тем, что заполнение таблиц идет автономно. Если заполняются поля в таблице "Сотрудник", то одноименные поля в таблице "Работающий" не заполняются.
Б. Иерархия таблиц. Указанное заполнение порой неудобно и потому используют наследование не абстрактных типов данных, а таблиц, которые связывают так:
CREATE TABLE Преподаватель
OF TYPE Преподаватель_ТУРЕ
UNDER Работающий;
CREATE TABLE Сотрудник
OF TYPE Сотрудник_ТУРЕ
UNDER Работающий;
В этом случае таблицы становятся вложенными (рис. 8.10).
Если создать запрос
SELECT * FROM Работающий;
то будут выданы поля как объекта "Работающий", так и объектов "Преподаватель" и "Сотрудник".
Для получения данных только из определенной таблицы (например, "Сотрудник") необходимо создать запрос
SELECT * FROM ONLY(Сотрудник);
Аналогично и с процедурами обновления
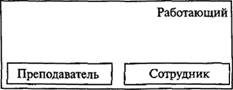
Рис. 8.10. Пример вложенной таблицы
DELETE FROM ONLY(Сотрудник)
WHERE Шифр_работы=254;
До сих пор использовались (см. рис. 8.6) разнородные структуры. Однако таблицы могут быть пополнены и однородными структурами (коллекциями).
Добавим к таблицам "Сотрудник" и "Преподаватель" коллекции:
а) участие сотрудника в научных темах:
ALTER TABLE Сотрудник
ADD Проект SET (integer);
б) учебные пособия преподавателя:
ALTER TABLE Преподаватель
ADD Пособия MULTISET (ROW(
Название varchar(30),
Год_издания integer)
);
Заметим, что MULTISET состоит из наборов ROW.
Тогда таблица "Преподаватель" получает новый вид (табл. 8.2).
Таблица 8.2
Новая таблица "Преподаватель"
|
Шифр работающего |
Фамилия |
Шифр предмета |
Вид занятия |
Адрес |
Пособия |
|||||
|
Город |
Улица |
Дом |
Корпус |
Квартира |
Название |
Год издания |
||||
|
28 |
Петров |
1 |
Лекции |
СПб |
Кима |
21 |
2 |
321 |
А Б В |
1999 1998 1995 |
Отметим также, что коллекция – понятие гибкое. Она может быть полем записи и в то же время записи могут играть роль элементов коллекции.
Запросы к коллекциям могут быть составлены лишь в простейших случаях. Запрос на выборку для таблицы "Преподаватель" имеет вид
SELECT шифр_работающего, фамилия,
Пособия.Название
FROM Преподаватель WHERE 1999 IN (Пособия);
Вставка может осуществляться таким оператором
INSERT INTO Преподаватель
VALUES (', 'Иванов', 1, 'преподаватель',
ROW('CПб', 'Московский', 137, 2, 118),
ROW('Информатика', 'лекция'),
“MULTISET{ROW('A1',1996),
ROW('AZ,1997),
ROW('A4',1997)}”);
Следует отметить, что в СУБД Informix Universal Server введен новый тип переменной COLLECTION, в которой в процессе работы программы (хранимой процедуры) могут храниться значения данных.
Для более сложных запросов требуется использовать хранимые процедуры, возможно, с циклами.
С помощью хранимых процедур формируются и необходимые дополнительные методы, поскольку в СУБД Informix Universal Server нет механизма превращения хранимых процедур в методы. Таким образом, язык SQL3 обладает значительно большими возможностями по сравнению с языком SQL2.
В то же время разработчиков БД, видимо, настораживает более сложная структура объектов и, главное, методов. Кроме того, SQL3 характеризуется неполнотой операторов: часть операторов разработчику приходится создавать самому в рамках хранимых процедур, для чего необходимо хорошо знать язык SQL2.
Названные обстоятельства и инерционность привычного, широко распространенного реляционного мышления объясняют, по всей видимости, тот факт, что расширенные ОРБД не нашли пока масштабного применения.
Вместе с тем широкое распространение получила гибридная разновидность ОРБД, являющаяся серьезным усовершенствованием реляционных БД.
Расширенные ОРБД – серьезный шаг в направлении объектно- ориентированных баз данных. Сфера применения таких ОРБД будет, по мнению авторов, расти. Они формируют средства как для революционного перехода к ООБД, так и для постепенного, эволюционного движения в будущее баз данных.
Чтобы понять перспективы развития ОРБД, следует оцепить их достоинства и недостатки
К достоинствам следует отнести [2]:
• устранение ряда недостатков реляционных БД (см. § 8.1);
• повторное использование компонентов;
• использование накопленных знаний по реляционным БД.
К недостаткам ОРБД возможно отнести:
• усложнение структуры БД и частичную утрату простой обозримости результатов, как в реляционных БД;
• сложность построения абстрактных типов данных и методов, связывающих типы в иерархию;
• менее широкий набор типов связей, определяемых языком программирования SQL, чем в объектно-ориентированных БД;
• менее продуманный, отлаженный и стандартизованный набор типов данных, чем в ООБД.
ОРБД, по-видимому, будут существовать еще достаточно долго, чему есть по меньшей мере два объяснения.
1. Быстрое накопление с помощью ОРБД опыта, который можно использовать при создании ООСУБД.
2. Необходимость иметь средства для постепенного эволюционного "перевода" многочисленных реляционных БД в разряд ООБД, за которыми, видимо, будущее.