Подходы к реализации ETL-процесса
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
· что такое процесс ETL;
· место процесса ETL в архитектуре системы бизнес аналитики на основе хранилищ данных;
· что такое реализация ETL-процесса с использованием промежуточной области;
· что такое реализация ETL-процесса без использования промежуточной области;
· основные элементы ETL-процесса ;
и научитесь:
· строить диаграммы движения данных, диаграммы преобразования данных, диаграммы управления потоком преобразования данных ;
· выполнять общее планирование реализации ETL-процесса;
· проектировать ETL-процессы.
Литература: [3], [14], [33], [ [ 32 ] 32], [51].
Введение
Для того чтобы заставить ХД заработать, необходимо не просто обеспечить взаимодействие многих источников данных – важно тщательно спланировать это взаимодействие. Поэтому процессы извлечения, преобразования и загрузки данных играют важную роль в создании и эксплуатации ХД.
Чтобы процесс преобразования данных протекал без сбоев, необходимо обеспечить наличие необходимой документации и метаданных. Процесс извлечения данных влияет на производительность других систем, поэтому его следует рассматривать в аспекте управления изменениями и конфигурацией систем – источников данных.
Под аббревиатурой ETL (extraction, transformation, loading — извлечение, преобразование и загрузка данных ) понимается составной процесс переноса данных одного приложения или автоматизированной информационной системы в другие.
Процесс ETL реализуется путем либо разработки приложения ETL, либо создания комплекса встроенных программных процедур, либо использования ETL-инструментария. Приложения ETL извлекают информацию из исходных БД источников, преобразуют ее в формат, поддерживаемый БД назначения, а затем загружают в эту БД преобразованные данные.
Цель любого ETL-приложения состоит в том, чтобы своевременно доставить данные из внешних систем в систему, с которой работают пользователи. Как правило, ETL-приложения используются при переносе данных внешних источников в ХД систем бизнес-аналитики. Поэтому организация процесса ETL является составной частью проекта разработки практически любого ХД.
Проектирование и разработка ETL-процесса является одной из самых важных задач проектировщика ХД. Для ХД процесс ETLимеет следующие свойства. Во-первых, объем данных, который выбирается из систем источников данных и помещается в ХД, как правило, бывает достаточно большим, до десятков Гб. Во-вторых, процесс ETL является необходимой составной частью эксплуатации ХД. Периодичность процесса ETL определяется не только потребностью пользователя в своевременных данных, но и размером загружаемой порции данных. По оценкам специалистов, ETL-процесс может занимать до 80% времени. В-третьих, на разных стадиях процесса ETL формируются метаданные ХД и обеспечивается качество данных. В-четвертых, во время процессаETL может произойти потеря данных, поэтому необходимо обеспечивать контроль за поступлением данных в ХД. В-пятых, процесс ETL обладает свойством восстанавливаемости после сбоев без потери данных.
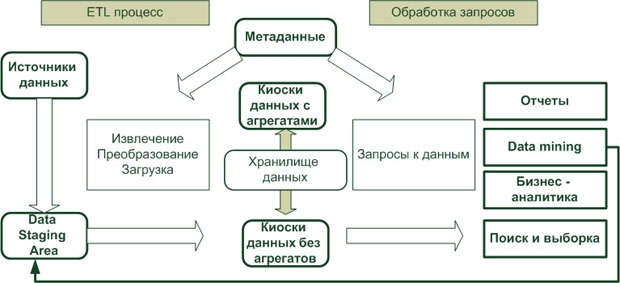
На рис. 15.1 показано место процесса ETL в архитектуре системы бизнес-аналитики на основе ХД.
увеличить изображение
Рис. 15.1.Процесс ETL в архитектуре хранилища данных
Как видно из рисунка, на процесс ETL возложена вся работа по подготовке данных для доставки их в ХД, формирование и обновление метаданных ХД, а также управление данными, извлеченными в результате Data mining.
Таким образом, процесс ETL состоит из трех основных стадий.
· Извлечение данных На этой стадии отбираются и описываются данные внешних источников (начинают формироваться метаданные ХД), которые должны храниться в ХД (релевантные данные).
· Преобразование данных На этой стадии релевантные данные преобразуются в формат представления данных в ХД, правилапреобразования сохраняются в метаданных ХД, формируются ключевые поля таблиц физической структуры ХД, выполняетсяочистка данных.
· Загрузка данных На этой стадии данные загружаются в ХД, выполняется построение агрегатов.
Подходы к реализации ETL-процесса
Существует несколько подходов к реализации процесса ETL. Общепринятый подход состоит в извлечении данных из систем источников, размещении их в промежуточной области дисковой памяти (Data Staging Area), выполнении в этой промежуточной области процедур преобразования и очистки данных, а затем загрузки данных в ХД, как показано на рис. 15.2.
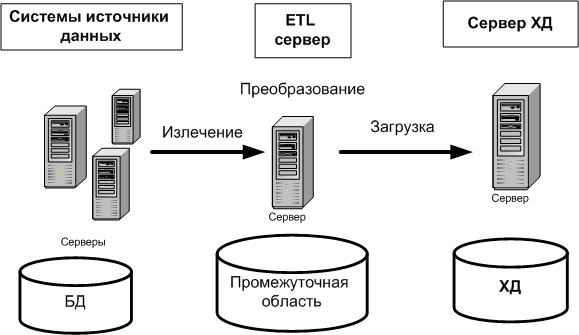
Рис. 15.2.Реализация ETL-процесса с использованием промежуточной области
Размещение извлеченных данных в промежуточной области означает запись данных в БД или файлы дисковой подсистемы. Альтернативным подходом к реализации процесса ETL является выполнение преобразований в оперативной памяти ETL-сервера и непосредственную загрузку в ХД, как показано на рис. 15.3.
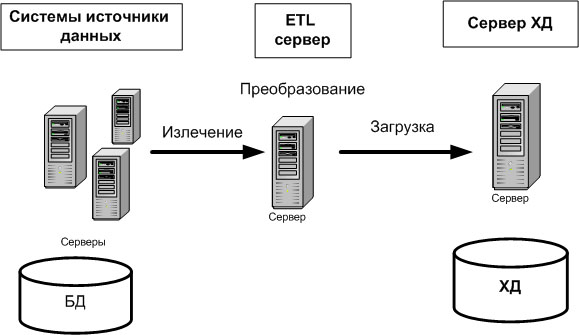
Рис. 15.3.Реализация ETL-процесса без использования промежуточной области
Преобразование данных в оперативной памяти выполняется быстрее, чем при размещении их предварительно на диске. Однако применение такого подхода лимитируется размером порции загружаемых данных. Если размер порции загружаемых данных достаточно большой, то необходимо использовать промежуточную область.
Иногда применяется еще один подход к реализации процесса ETL, когда преобразование данных выполняется на сервере ХД, в процессе их загрузки. Использование такого подхода определяется вычислительными возможностями сервера ХД. Обычно такой подход применяется для MPP серверов ХД.
В зависимости от того, кто извлекает данные из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
1. ETL-сервер периодически подключается к системам, источникам данных, опрашивает их, извлекает результаты выполнения запросов и размещает их у себя для дальнейшей обработки.
2. Триггеры систем источников данных отслеживают изменения в данных и размещают измененные данные в отдельных таблицах, которые затем экспортируются на ETL-сервер.
3. Специально разработанное приложение в системах источниках данных периодически опрашивает их и экспортирует данные наETL-сервер.
4. Используются log-журналы БД систем источников, которые содержат все транзакции изменения данных. Измененные данные извлекаются из log-журналов и сохраняются на сервере системы источника данных для последующего импорта в ETL-сервер.
В зависимости от того, где выполняется процесс извлечения данных из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
1. ETL-процесс выполняется на выделенном ETL-сервере, который располагается между системами источниками данных и сервером ХД. В этом случае процесс ETL не использует вычислительных ресурсов сервера ХД и серверов систем источников данных.
2. ETL-процесс выполняется на сервере ХД. В этом случае сервер ХД должен иметь достаточное дисковое пространство для выполнения ETL-процесса, использование ресурсов сервера не должно сильно влиять на производительность запросов пользователей к ХД.
3. ETL-процесс выполняется на серверах систем источников данных для ХД. В этом случае изменения в данных сразу же отражаются в ХД. Такой подход используется при разработке ХД реального времени.
Таким образом, при проектировании процесса ETL проектировщик ХД должен на основе анализа требований к функционированию ХД совместно с руководителем ИТ-проекта выбрать программно-аппаратное решение для реализации ETL-процесса, а именно – точно определить, где и каким способом будет выполняться ETL-процесс. На это решение может сильно повлиять бюджет проекта. Например, может быть недостаточно финансовых средств, чтобы реализовать процесс ETL на выделенном сервере.
Разработка ETL-процесса
Как правило, при конструировании процесса ETL для ХД придерживаются следующей последовательности действий.
· Планирование ETL-процесса, которое включает в себя разработку диаграммы потоков данных от систем-источников, определение преобразований, метода генерации ключей и последовательности операций для каждой таблицы назначения.
· Конструирование процесса заполнения таблиц измерений, которое включает в себя разработку и верификацию процесса заполнения статических таблиц измерений, разработку и верификацию механизмов изменения для каждой таблицы измерений.
· Конструирование процесса заполнения таблиц фактов, которое включает в себя разработку и верификацию процесса первоначального заполнения и периодического дополнения таблиц фактов, построение агрегатов и разработку процедур автоматизации процесса ETL.
Планирование ETL-процесса
Процесс преобразования данных играет весьма важную роль в достижении успеха реализации проекта ХД, поэтому он должен быть хорошо спланирован. Разработка плана носит интерактивный характер.
Сначала создается обобщенный план, в котором отражается перечень систем –источников данных и указываются планируемые целевые области данных (данных, которые будут размещаться в ХД). Источник целевых данных определяется на основе сформулированных бизнес-требований к ХД. Как правило, источники данных существенно различаются: от БД и текстовых файлов до SMS-сообщений. Это обстоятельство может значительно усложнить задачу преобразования данных.
Назначение таких высокоуровневых описаний источников дает, с одной стороны, разработчикам представление и о создаваемой системе, и о существующих источниках данных, а с другой, руководству организации, — понимание сложности, связанной с процессами преобразования данных.
К составлению обобщенного плана лучше всего приступать, когда разработана многомерная модель ХД. Тогда для каждой таблицы многомерной схемы можно определить таблицы – источники данных.
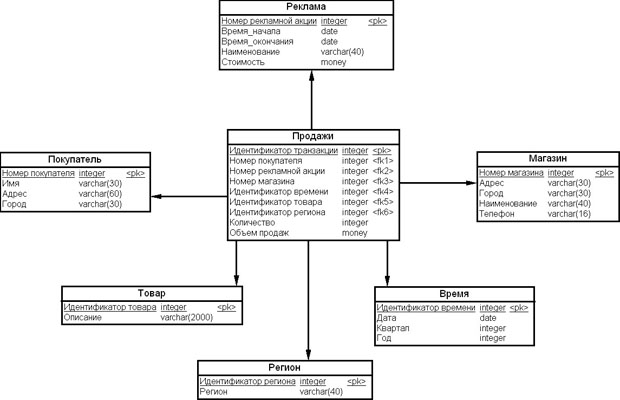
Рассмотрим пример многомерной схемы ХД системы поддержки принятия решений на рис. 15.4.
Связи между таблицами многомерной схемы ХД и таблицами – источниками данных можно указать с помощью стрелочек, как на диаграмме на рис. 15.5.
увеличить изображение
Рис. 15.4.Многомерная схема ХД системы поддержки принятия решений
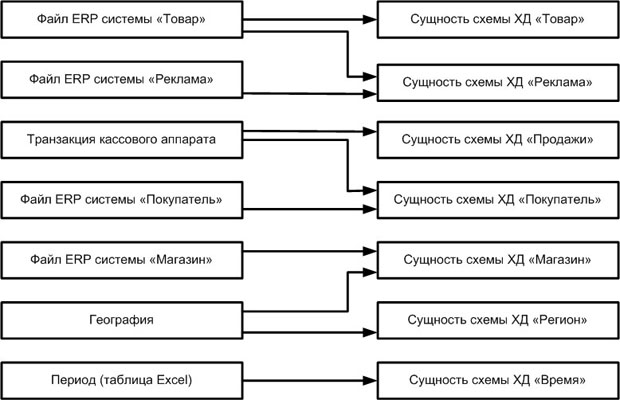
увеличить изображение
Рис. 15.5.Планирование систем источников для ETL-процесса
Каждую стрелочку на диаграмме следует пронумеровать и сопроводить комментарием, который должен служить напоминанием разработчикам о необходимости следить за целостностью ссылочных данных или других определенных бизнес-правилами особенностях обработки каждой таблицы источника.
На этой стадии планирования необходимо зафиксировать все обнаруженные расхождения в определениях данных и схемах кодирования.
Детальное планирование ETL-процесса во многом зависит от использования выбранных ETL-инструментов. К настоящему времени разработано достаточно много таких инструментов как компаниями производителями комплексных решений в области ХД (IBM, Oracle, MicroSoft), так и сторонними производителями программного обеспечения (Sunopsis). Поэтому задача выбора подходящихETL-инструментов должна быть решена до того, как приступать к детальному планированию.
Программное обеспечение этого класса предназначено для извлечения, приведения к общему формату, преобразованию, очисткии загрузки данных в хранилище. Существуют два подхода к написанию ETL-процедур: 1) их можно написать вручную; 2) можно воспользоваться специализированными средствами ETL.
Каждый из подходов имеет ряд преимуществ и недостатков, поэтому выбор того или иного метода реализации процедур ETLопределяется требованиями к подсистеме загрузки данных в каждом конкретном случае. Выделим наиболее важные достоинства каждого из способов написания ETL-процедур.
Написание вручную:
· возможность использования широко распространенных парадигм программирования, например, объектно-ориентированного программирования;
· возможность применения многих существующих методик и программных средств, позволяющих автоматизировать процесс тестирования разрабатываемых процедур загрузки данных ;
· доступность человеческих ресурсов;
· возможность построения наиболее производительного решения с использованием при программировании всех преимуществ систем управления базами данных (СУБД), задействованных в проекте;
· возможность построения наиболее гибкого решения.
Применение ETL-инструментов:
· упрощение процесса разработки, и, главное, процесса поддержания и модификации процедур ETL;
· ускорение процесса разработки системы, возможность использования готовых наработок, поставляемых вместе со средствамиETL;
· возможность использования встроенных систем управления метаданными, позволяющих синхронизовать метаданные между СУБД, средством ETL, а также инструментами визуализации данных;
· возможность автоматической документации написанных процедур;
· многие средства ETL предоставляют собой средства увеличения производительности подсистемы загрузки данных, которые включают в себя возможность распараллеливания вычислений на различных узлах системы, использование хеширования и многие другие.
Следует обратить внимание на выбор технологии для реализации процедур ETL, в случае если одной из систем-источников данных выступает ERP-система. Системы данного класса являются наиболее сложными, так как обладают очень запутанной моделью данных и зачастую содержат десятки тысяч таблиц. Для реализации процедур загрузки данных из ERP-систем в команду разработчиков должен быть включен специалист, хорошо знакомый с данной системой-источником, так как анализ подобного рода систем с нуля занимает слишком длительное время. Кроме того, большинство поставщиков средств ETL предоставляют коннекторы ко многим ERP-системам, позволяющим импортировать метаданные ERP-систем и работать с ними на более высоком уровне. Наличие коннекторов к ERP-системам предоставляет специализированным средствам ETL большое преимущество над написанием вручную процедур загрузки данных, в случае если в качестве источника данных выступает ERP-система.
После выполнения предварительного планирования приступают к детальному планированию.
Детализированные планы преобразования данных составляются для всех таблиц, участвующих в процессе преобразования.
В настоящей лекции мы не даем рекомендаций по формированию детального плана, поскольку в каждом конкретном случае детальное планирование выполняется руководителем проекта создания ХД и включает в себя учет различных факторов, связанных со спецификой предметной области ХД. Так, например, для банковских ХД, возможно, будет необходимо выполнить проверку корректности бухгалтерской базы по бизнесправилам (провести в процессе ETL подсчет остатков и оборотов по отдельным лицевым и/или балансовым счетам).
УДК: 336.71: 004.73
Н. В. Ситник, канд. екон. наук,
доц. кафедри ІСЕ,
Є. А. Труш, аспірантка кафедри ІСЕ,
ДВНЗ “КНЕУ імені Вадима Гетьмана”
СХОВИЩЕДАНИХ — ДЖЕРЕЛО
БАГАТОВИМІРНОГО OLAP-АНАЛІЗУВБАНКАХ
АНОТАЦІЯ. У даній статті розкрито питання побудови сховищ даних для
аналізу банківської діяльності. Проаналізовано основні види архітектур по-
будови сховищ даних та обґрунтована необхідність побудови корпоратив-
ного сховища банківської інформації. Розглянуто та проаналізова-
ні концептуальні підходи до побудови моделі сховища даних. Визначено
основні види аналізу банківської діяльності на основі сховищ даних та підходи
до побудови інформаційно-аналітичної системи банку на основі OLAP.
КЛЮЧОВІ СЛОВА. Сховище даних, вітрина даних, OLAP-система,
ETL-система, OLTP-система, аналітична задача.
АННОТАЦИЯ. В данной статье раскрыты вопросы построения храни-
лищ данных для анализа банковской деятельности. Проанализированы
основные виды архитектур построения хранилищ данных та обоснована
необходимость построения корпоративного хранилища банковской ин-
формации. Рассмотрены и проанализированы концептуальне подходы к
построению модели хранилища данных. Определены основные виды
анализа банковской информации на основе хранилищ данных та подходы
к построению информационно-аналитической системы банку на основе
OLAP.
КЛЮЧЕВЫЕ СЛОВА. Хранилище данных, вирина данных, OLAP-система,
ETL-система, OLTP-система, аналитическая задача.
ANNOTATION. Current article describes the data warehouse (storage) creation
for a bank. DW will help to analyze the banking activity. It was analyzed the main
data warehouse architectures and was shown the necessity of the DW creation
for the banking data. It was reviewed and analyzed conceptual approaches for
the building a data warehouse model. The article presents the main types of
analysis of the banking activity on the base of the data warehouse and shows the
methods for creation of the information-analytical banking system on the OLAP
technology base.
KEY WORDS. Data warehouse (storage), data mart, OLAP-system,
EТL-system, OLTP-system, analytical task.
Розробка сховища даних — це один з інноваційних напрям-
ків у розвитку інформаційних банківських технологій. Акту-
альність створення сховища даних для банку пояснюється тим,
що існуючі автоматизовані банківські системи (АБС) склада-
ються з фронт-офісних та бек-офісних систем і автоматизують
лише задачі функціонального контролю та оперативного
© Н. В. Ситник, Є. А. Труш, 2011 управління на основі інформації традиційних баз даних.
Фронт-офісна частина БІС, що пов’язана з первинним обліком,
обслуговуванням клієнтів та формуванням банківських доку-
ментів, представлена системами оброблення трансакцій
(OLTP- OnLine Transactional Processing ). Бек-офісна частина
АБС — це наступне оброблення фронт-офісних даних з метою
обліку банківських операцій, вона представлена інформацій-
ними системами управління (МІS —Management Information
Systems), які формують внутрібанківську звітність та звітність,
яку необхідно формувати для НБУ та податкових органів.
Тобто існуючі на сьогодення банківських системи, в перева-
жній більшості автоматизують облікові операції, формують
необхідну звітність, але не завжди мають засоби реалізації
консолідованих аналітичних технологій. Розвиток інфор-
маційних технологій показав, що автоматизація лише задач
трансакційного класу є недостатньою з точки зору ефектив-
ності управління банківським бізнесом.
У банках існує потреба в оперативному багатоаспектному бі-
знес-аналізі. Для задоволення цих потреб банки застосовують
нову технологію вирішення аналітичних задач, яка дістала на-
зву OLAP (On-Line Analytical Processing ). Ця технологія призна-
чена забезпечувати аналітиків динамічним багатовимірним ана-
лізом консолідованих даних. Виконання аналітичних запитів на
традиційній базі даних нераціонально, а іноді навіть не можливе.
Зручним способом зберігання даних для вирішення оперативних
аналітичних задач є різновид баз даних, який носить назву схо-
вище даних (Data Warehouse).
Сховище даних необхідно для зберігання і накопичення різ-
нопланових даних з різних джерел за великі періоди часу, а також
для швидкого доступу та пошуку релевантноїзапитам інформації.
Спочатку сховища даних створювалися в переважній біль-
шості для вирішення задач класу OLAР (On-Line AnalyticalProcessing), але враховуючи стабільність сховищ, значні об-
сяги накопиченої інформації, сховища даних стали
перспективною платформою для інтелектуального аналізу
даних (Data Mining). Основною задачею Data Mining є пошук
логічних та функціональних закономірносей у накопчених
даних, побудова моделей та правил, що можуть пояснити
найдені закономірності, а також можуть бути використаними
при прогнозуванні. Тому на сьогодні одним із нових напрямів
використання сховищ даних є інтеграція технологій OLAР і
Data Mining. У роботах [7, 8] висвітлено основні проблеми такої інтеграції і введено новий термін — багатовимірний ін-
телектуальний аналіз — OLAР Mining або OLAM.
За визначенням Інмона сховище даних — це предмет-
но-орієнтована, інтегрована, прив’язана до часу та незмінна су-
купність даних, призначена для підтримки прийняття рішень [5].
Розрізняють такі види сховищ даних: централізоване схо-
вище даних і кіоски чи вітрини даних. Корпоративне сховище
даних чи корпоративна інформаційна фабрика (Corporate
Information Factory — CIF) або більш рання назва корпоративне
сховище даних (Еnterprise Data Warehouses — EDW) вміщують
інтегровану інформацію, зібрану із певної множити оператив-
них БДта зовнішніх джерел, яка характеризує всю корпорацію і
необхідна для виконання консолідованого аналізу діяльності
корпорації у цілому. Такі сховища охоплюють усі багаточисе-
льні напрями діяльності корпорації і використовуються для
прийняття як тактичних, так і стратегічних рішень. Розробка
корпоративного сховища даних дуже трудоємкий процес, який
може становити від одного до кількох років.
Кіоски чи вітрини даних (data marts) це певна підмножина кор-
поративних даних, які характеризують конкретний аспект діяль-
ності, наприклад, роботу якогось підрозділу. Кіоск може вміщу-
вати як агреговані, так і первинні дані певної предметної область
Кіоск може отримувати дані з корпоративного сховища даних
(залежний кіоск) чи бути незалежним і тоді джерелом поповнення
його даними будуть оперативні бази даних. Розробка кіоска даних
потребує значно менше часу і в середньому займає приблизно
3—4 місяці.
Корпоративне сховище даних та вітрини будуються за подіб-
ними принципами і використовують практично одинакові техно-
логії.
Авторами і першими розробниками сховищ даних було за-
пропоновано дві основні архітектури: так звана корпоративна
інформаційна фабрика (Corporate Information Factory, скорочено
CIF) Білла Інмона [5] і сховище даних з архітектурою шини (Data
Warehouse Bus, скорочено BUS) Ральфа Кімболла (Ralph Kim-
ball) [6].
Сховище даних з архітектурою CIF будується поетапно на
базі “спірального” підходу, в основу якого покладено центра-
лізоване сховище іззалежними вітринами даних. Тому іноді цей
підхід називають низхідним, тобто таким при якому створення
сховища виконується за принципом “зверху-вниз”. Така архі-
тектура розробляється на основі аналізу корпоративних вимогдо даних. Виззначившись з даними, що підлягають зберіганню в
сховищі, їх спочатку вибирають з успадкованих систем-джерел.
Якщо ці детальні атомарні дані не є нормалізованими, то їх
приводять до 3НФ. Тобто детальні атомарні даніз успадкованих
систем джерел зберігаються в реляційній моделі в нормалізо-
ваному представленні. На основі детальних атомарних даних
будується просторова модель для зберігання узагальнених да-
них.
Cховище даних з архітектурою шини (data-mart bus
architecture with linked dimensional data marts — BUS) Ральфа
Кімболла (Ralph Kimball) будується на принципах побудови
незалежних взаємопов’язаних вітрин. Перша вітрина даних
будується для одного бізнес-процесу з використанням вимірів
та показників, що в подальшому будуть використовуватись в
інших вітринах. Наступні вітрини даних розробляються з ви-
користанням попередньо створених вимірів, що в підсумку доз-
воляє створити логічно інтегровану сокупність (шину) вітрин,
яка буде виконувати роль корпоративного сховища даних.
Створення сховище даних при такому підході починається із
відбору даних, необхідних для бізнес-аналізу, з успадкованих
систем-джерел і підготовки їх для просторового зберігання.
Просторова модель при цьому може зберігати як деталізовані
атомарні дані так і агрегати даних. Цей підхід до створення
сховищ даних іноді називають висхідним, тобто таким, при
якому створення сховища виконується за принципом “зни-
зу-вверх”.
Крім цих архітектур, запропонованих основоположниками
концепції сховищ даних, на сьогодні використовується велика кіль-
кість різних архітектур, які описані в роботах [1, 3].
Згідно [4] формалізовано сховище даних можна описати на-
ступним чином:
DW = < DB, rf, RF, rm, RМ, func>,
де DB — множина баз даних — джерел сховища даних;
rf — множина відношень фактів;
RF — схема rf;
rm — множина відношень метаданих;
RМ — схема rm;
func — множина процедур (рішень).
Важливим при побудові сховища даних банку вирішення пи-
тання його концептуальної архітектури. Вибір архітектури побу-
дови сховища для банку обумовлюється організацією обробленняданих у банку: децентралізоване (розподілене) та централізоване
оброблення даних.
Є два можливих варіанти децентралізованої технології:
повна децентралізація та децентралізація на рівні філії банку.
Повна децентралізація полягає в тому, що у кожному з орга-
нізаційних підрозділів банку установлюється окрема незалеж-
на копія АБС, яка працює зі своєю автономною базою даних.
Обмін інформацією виконується підсумковими, консолідо-
ваними даними по завершенню банківського дня електрон-
ними чи паперовими документами. Децентралізація на рівні
філії полягає в тому, що у кожній з філій установлюється
окрема незалежна копія АБС, яка працює зі своєю автономною
базою даних, а всі її безбалансові відділення працюють з нею в
on-line-режимі. Системи організації інформаційної технології
з децентралізацією на рівні філії є найбільш поширеними в
Україні.
Централізована система працює з єдиною базою даних у
головному офісі банку, забезпечуючи режим on-line доступу
до даних всіх інших підрозділів банку. В єдиній базі даних
зберігається вся нормативно-довідкова інформація, а також
дані про всіх клієнтів та про всі операції, що забезпечує від-
сутність дублювання та протирічивості даних, спрощує про-
цедури їх адміністрування та надає можливіcть співставлення
даних та контролю за операціями, які виконані одним клієнтом
у різних підрозділах банку. Тобто централізоване оброблення
даних ліквідує “прив’язку” клієнта до певної дирекції чи філії
банку, надаючи йому можливість виконання операцій у
будь-якому офісі банку. Централізація надає переваги при
виконанні операцій та їх бухгалтерському проведенні в режимі
реального часу.
На перший погляд, для банків з централізованим обробленням
даних підходить централізована архітектура, тобто корпоративне
банківське сховище з залежними вітринами, а для банків з деце-
нтралізованим обробленням даних — сховище даних з архітек-
турою шини.
Не дивлячись на те, що централізація банківських інфор-
маційних систем вимагає значних капіталовкладень на прид-
бання централізованої АБС, обладнання, каналів зв’язку,
створення нових технологій безперебійної роботи системи,
дана тенденція відображає стратегічний напрямок розвитку
інформаційних технологій у банківському бізнесу, яка буде
переважати в майбутньому. Крім того, враховуючи щоденну консолідацію та централізоване формування банківського ба-
лансу і звітності на рівні головного офісу банку, вважаємо за
доцільне для банків з децентралізованим обробленням фор-
мувати також централізоване корпоративне банківське схо-
вище. Це дозволить централізовано аналізувати діяльність
головного банку та його філій. Крім того такий підхід не буде
потребувати внесення радикальних змін у сховищі даних при
переході банку на централізоване оброблення даних. Аналіз
показав, що на сьогодення українські банки використовують
тематичні вітрини даних для аналізу окремих аспектів бан-
ківської діяльності, тому за цих умов корпоративне банківське
сховище краще будувати з архітектурою шини.
Дуже часто в банках використовується кілька облікових
OLTP-систем, які виступають джерелом для сховища даних. Кіль-
кість таких систем залежить від стану інформатизації банку та
політики щодо впровадження ІT-технологій.
Взаємозв’язок сховищ даних з OLTP-системами показано на
рис. 1.
Тематичні вітрини даних
...
OLTP-система
роздрібного
обслуговування
фізичних осіб
OLTP-система
роздрібного
обслуговування
юридичних осіб
OLTP-система
підтримки
карткових
операцій банку
OLTP-система
формування
звітності для НБУ
Зовнішні
джерела
Файли
звітності
НБУ
Підсумки
про проведені
операції
за день
Підсумки
про проведені
операції
за день
Дані
про виконані
карткові
транзакції
за день
Сиситема
ELT
КОРПОРАТИВНЕ
СХОВИЩЕ ДАНИХ
Деталізовані
дані
Агреговані
дані
Репозитарій
метаданих
OLAP (OLAM) і Data Mining системи
Рис. 1. Взаємозв’язок сховищ даних з OLTP-системами
Сховище даних містить деталізовані дані та агреговані, тобто
узагальнені дані. Ступінь деталізації та узагальнення даних, ви-
значається потребами банківських аналітиків. Обов’язковою ком-
понентою сховища даних є репозиторій метаданих, який склада-ється з бази метаданих і браузера для їх перегляду. Метаданими
називають бізнес-інформацію, що описує елементи сховища да-
них, бізнес-правила, процеси та джерела даних.
Ключовою компонентою при побудові сховища даних
є ETL-система (Extraction, Transformation, Loading), що виконує
процедури відбору, перетворення та завантаження даних до схо-
вища. В першу чергу ETL-системою виконується відбір з баз да-
них OLTP-систем інформації, що необхідна для бізнес-аналізу.
Враховуючи, що дані в сховище надходять з різних джерел, де
вони можуть мати різні імена, формати, одиниці вимірювання і
способи кодування, тому першніжвиконати їх завантаження, дані
перевіряються на коректність, очищаються від помилок, приво-
дяться до одного єдиного способу кодування, виду та формату, в
необхідній мірі узагальнюються і агрегуються. З цього моменту
дані представляються користувачеві у вигляді єдиного інформа-
ційного простору, які набагато простіше аналізувати.
Для здійснення того чи іншого виду банківського аналізу за
допомогою OLAP-технології доцільно виділити окремі тематичні
вітрини даних. У вітринах зберігається необхідна інформація для
певного виду аналізу, наприклад для аналізу кредитного порт-
фелю, причому дуже часто у вітрині може бути відсутні дані ни-
жнього рівня, тобто деталізована інформація, а лише агреговані
дані.
Важливим моментом створення банківського корпорати-
вного сховища є побудова базової моделі сховища, тобто
визначення основних бізнес-цілей для яких створюється
сховище, переліку інформаційних об’єктів (сутностей) та
зв’язків між ними. У практиці впровадження банківських
сховищ відомі дві конценції до побудови моделі сховища
даних [2]: перший варіант оснований на Головній книзі банку,
коли в основу моделі покладено облікова схема “Рахунки +
Клієнти + Проведення”, другий варіант — побудова сховища
на базі банківських угод (модель угод), коли за основу бе-
реться наступна схема “Угода—Рахунки—Операція” чи
“Угода—Операція—Проведення”. При використанні моделі
угод кожній угоді відповідають певні операцій (видача, по-
гашення, нарахування), вид (вимога чи зобов’язання), сума,
фінансовий інструмент і дата виконання, а також рахунки.
Модель угод добре зарекомендувала себе в системі
RS-DataHouses для ресурсних угод: кредити, депозити, між-
банківські кредити (залучені та розміщені), кредитні лінії,
угоди з цінними паперами і репо, Forex-угоди і SWAP, гара-
нтії і акредитиви. Необхідно зауважити, що концепція схо-
вища, яка побудована на обліковій схемі більш підходить для
банків, що використовують вітчизняні АБС, друга концепція
на базі угод — для банків, що експлуатують АБС західних
розробників.
Дані сховища використовуються для аналізу фінансової
діяльності банку, яка охоплює задачі управління активами,
пасивами, ліквідністю, дохідністю, співвідношенням між
активами і пасивами, власним капіталом, кредитним порт-
фелем, портфелем цінних паперів, ризиком (валютним, від-
сотковим, операційним, ризиком позабалансових операцій
тощо).
Кожна з перерахованих задач аналізу фінансової діяльності
характеризується своїми методами здійснення аналізу, і в той же
час вони є взаємопов’язаними. В основному, всі аналітичні бан-
ківськізадачізводяться до наступних напрямів аналізу:
1. Аналіз брутто-показників банку — величини активів, паси-
вів, власного капіталу, прибутків, кредитів тощо. Часто оцінка
здійснюється на основі співставлення власних показників з ана-
логічними показниками інших банків.
2. Аналіз ресурсної бази за обсягами, структурою та основ-
ними тенденціями розвитку складових. При цьому здійснюється
класифікація окремих статей ресурсів банку, розрахунок та ви-
вчення динаміки структурних показників.
3. Аналіз активів банку за обсягами, структурою та основними
тенденціями розвитку складових. Активи банку класифікуються
за окремими статтями, розраховується та вивчається динаміка
структурних показників.
4. Аналіз ліквідності банку на основі розрахунку фінансових
коефіцієнтів та їх порівняння з критеріальним рівнем.
5. Аналіз та визначення ступеня збалансованості активів і па-
сивів за строками та сумами, ГЕП-аналіз, спред-аналіз.
6. Аналіз дохідності банку на основі аналізу даних балансу
та звітів про прибутки та збитки. Розраховуються якісні та кіль-
кісні показники, що характеризують дохідність банку, ефек-
тивність використання активів, структуру доходів та витрат
банку.
Крім вище перерахованих видів аналізу, здійснюється аналіз
окремих видів діяльності: аналіз кредитного портфелю, портфелю
цінних паперів, кредитоспроможності клієнтів, достатності вла-
сного капіталу, відсоткової маржі, прибутковості окремих опера-
цій та підрозділів, показників ліквідності тощо. Розробка сховищ даних потребує їх ретельного проектування
та вибору способу представлення даних на логічному рівні. Пи-
тання проектування сховищданих детально викладені в роботі [9].
Враховуючи те, що переважна більшість банківських
OLTP-систем реалізована під управлінням реляційних СКБД
(Oracle, SQLServer, Sybase, DB2), то для банківських установ пі-
дходять традиційні просторові моделі (dimensional model) сховищ
даних “зірка” (star schema) та “сніжинка” (snowflake schema), що
підтримуються цими системами.
Згідновимог Basel II, банкунеобхіднонакопичуватистатистикуне
меншеніжза сімроків, томунаявність сховища єнеобхідноюумовою
функціонування сучасного банку. Західні банки приступили до ство-
рення сховищоперативноїінформації, що надаєможливість у режимі
реального часу відстежувати шахрайські трансакції, проводити моні-
торинг платіжних операцій для боротьби з відмиванням “брудних”
грошей.
На основі сховищ даних у банках розробляються інформа-
ційно-аналітичні системи, основними типовими компонентами
яких є:
• банківські OLTP-системи, як основне джерело інформації
для сховища даних;
• ELT-засоби відбору, перетворення узгодження та транспор-
тування даних до сховища;
• репозитарій для зберігання моделей даних і метаданих;
• інструментальнізасоби для реалізації OLAP -запитів;
• інструментальнізасоби для реалізації інтелектуальних запитів.
Для побудови інформаційно-аналітичної системи банку краще
використовувати інструменти IBM Cognos і SAP Business Objects,
які признані лідерами ринку OLAP. Для бізнес-аналізу (Business
Intelligence, BI) і використання в банківських інформаційно-ана-
літичних системах також можна використовувати розробки на-
ступних компаній: Actuate, Arcplan, Brio, Computer Associates,
Crystal, Hummingbird, Hyperion, Informatica, Information Builders,
Microsoft, MicroStrategy, Oracle, Peoplesoft, ProClarity, SAP, SAS,
Siebel.
Література
1. АсадуллаевС. “Архитектуры хранилищ данных — I”. —
http://www.ibm.com/developerworks/ru/library/sabir/axd_1/index.html. 2. Михеев А., Савкин Г. Становление модели RS-DataHouse // Жур-
нал RS-Club. — № 4. — 2006. — С. 64—68.
3. Корпоративные хранилища данных. Планирование, разработка,
реализация. Том. 1: Пер. с англ. — М.: Вильямс, 2001
4. Медиковський М.О., Шаховська Н.Б. Формалізація операцій над
джерелами даних у просторі даних.http://www.vstu.vinnica.ua/~oeipt/-
files/index_18.files/6.pdf
5. W. H. Inmon, Building the Data Warehouse, QED/Wiley, 1991 .
6. Data-Warehousing-Kimball-Model-vs-Inmon-Model
http://www.scribd.com/doc/15487492/
7. Hap J. OLAР Mining An Integration of OLAР with Data Mining //
Proc. IFIP Conf jn Data Semantics Switzerland. — 1997
8. Parsaye K. OLAР and Data Mining: Bridging the Gap// Database
Programming and Design. — 1997. — № 2.
9. СитникН. В.Проектування базі сховищданих: Навч. посібник. —
К.: КНЕУ, 2004. — 348 с.
Стаття надійшла до редакції 12.05.2011 р.
Презентация на тему: "ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИЙ ETL И OLAP В АНАЛИЗЕ ФИНАНСОВЫХ ОРГАНИЗАЦИЙ Мелащенко А. О. аспирант Института Кибернетики." — Транслит презентации:
·
| Слайд 1 |
| ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИЙ ETL И OLAP В АНАЛИЗЕ ФИНАНСОВЫХ ОРГАНИЗАЦИЙ Мелащенко А. О. аспирант Института Кибернетики |
·
| Слайд 2 |
| Постановка задачи Количество балансовых счетов бухгалтерского анализа состоит из порядка 1000 счетов, которые характеризируются так называемыми активностью и пассивностью. Эти счета сгурпирированы, но каждый банк имеет практику выстраивать свою иерархию для отображения «видения» управляющего персонала. Каждый балансовый счет ниже по иерархии содержит лицевые счета, которые составляют сумму балансового счета. Задача: построить разрез структурированного баланса, по дням с отображением остатков по категориям. |
·
| Слайд 3 |
| ЭТАПЫ ПОСТРОЕНИЯ OLAP РЕШЕНИЯ Создание схемы OLAP БД Загрузка и преобразование (опционально) данных из OLTP БД в OLAP БД Построение необходимого куба(кубов), метрик и измерений. Построение отображения данных пользователю |
·
| Слайд 4 |
| ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ OLAP РЕШЕНИЯ |
·
| Слайд 5 |
·
| Слайд 6 |
·
| Слайд 7 |
·
| Слайд 8 |
| ИСПОЛЬЗОВАНИЕ РЕЗУЛЬТАТОВ ПРИ ПРОГНОЗИРОВАНИИ СОСТОЯНИЯ БАНКА Основная идея построения прогноза заключалась в: Выборе показателя функционирования банка, состоящего из определенного аналитиком набора балансовых счетов. Построение динамики этого показателя Поиске среди макроэкономических показателей наиболее «подходящего», т.е. инварината к выбранному показателю, используя корреляцию и автокорреляцию Построении или выборе прогноза макроэкономического показателей Построения прогноза показателя банка |
·
| Слайд 9 |
| «Деньги на текущих счетах в долларах США» и «Курс доллара США» автокорелограма |
·
| Слайд 10 |
| «Деньги на текущих счетах в долларах США» и «Курс доллара США» анализ трендов |
·
| Слайд 11 |
| «Параметр М1» и «Деньги на текущих и депозитных счетах в гривне» автокорелограма |
·
| Слайд 12 |
| «Параметр М1» и «Деньги на текущих и депозитных счетах в гривне» анализ трендов |
·
| Слайд 13 |
| «Деньги на текущих счетах в долларах США» и «Курс доллара США» прогноз |
·
| Слайд 14 |
| «Параметр М1» и «Деньги на текущих и депозитных счетах в гривне» прогноз |
·
| Слайд 15 |
| Ошибки прогноза ГодКвартал Курс доллара США Деньги на текущих счетах в долларах США Параметр М1 Деньги на текущих и депозитных счетах в гривне 2007I5051059341828813,823398274185 Прогнозное 504,051387501229592443301392 MAPE 0,450131,54610,85 MAD 2,35562375730151432 158 800 |
·
| Слайд 16 |
| Выводы Построение OLAP решений на базе MS SQL Server 2005 достаточно хорошо структурировано, практично и востребовано. На практике такие решения создаются в тесном сотрудничестве со специалистами конкретной предметной области Изначально корректно построенная схема OLAP БД экономит время используя VSFSS, так как в этот продукт включено множество визардов и интеллектуальных систем, позволяющих построить 80% OLAP-куба, основываясь на схеме БД. В докладе освещены актуальные проблемы финансового сектора Украины. Приведено решения одной из таких проблем, на примере задача прогнозирования данных бухгалтерского баланса. Показана практичность используемых методов и инструментов. |
ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИЙ ETL И OLAP В АНАЛИЗЕ
ФИНАНСОВЫХ ОРГАНИЗАЦИЙ
А.О. Мелащенко
Институт кибернетики им. В.М. Глушкова НАН Украины,
03028, Киев, проспект Науки 43, кв. 70.
Тел.: 524 5330, javatask@ukr.net
Рассматриваются вопросы использования решений BI в финансовых организациях Украины. Приводятся практические
рекомендации по построению OLAP решений и их применению для прогнозирования бухгалтерского баланса.
In the report questions of use of decisions BI in the financial organisations of Ukraine are considered. Practical recommendations about
construction OLAP of decisions and their application for forecasting of accounting balance are resulted.
Введение
Потребность в постоянном совершенствовании бизнес-процессов, повышения прибыльности, снижение
себестоимости, расширение рынков сбыта предприятий невозможно без анализа. Как правило, бизнес анализ
необходим на всех стадиях жизненного цикла продукта и во всех подразделениях предприятия. Что в свою
очередь привод к потребности обработки громадных объемов информации, ее структурирование, написание
интерфейсов доступа к ней, обеспечения безопасности, целостности и других проблем связанных с анализом.
Все это требует высокопрофессиональных сотрудников отдела IT, что в свою очередь является дорогим
«удовольствием».
С другой стороны, в частности, деятельность финансовых организаций, в частности банков, достаточно
формализована для создания типовых решений. Основными составляющими базиса анализа качества
функционирования банка являются:
1. Клиентская база, которая в свою очередь делится на:
а) связанных лиц;
б) несвязанных лиц.
2. Баланс банка в разрезе балансовых счетов.
3. Кредитный портфель.
4. Депозитный портфель.
Имея удобные и гибкие средства, позволяющие отобразить нужные разрезы этой информации,
управленцам и аналитикам, можно принимать оптимальные решения для улучшения всех показателей
функционирования. Как технология обработки информации OLAP, допускают многомерные представления
данных плюс оптимизацию скорости доступа к данным в сравнении с OLTP.
Но OLAP является законченной формой хранения данных, которые извлекаются из OLTP БД. Для
преобразования данных в нужные структуры используются, так называемые ETL инструменты.
Также для доступа к данным OLAP нужны «красивые» средства, нежели API или MDX. Такими
средствами являются или программы обработки электронных таблиц, которые обычно включают клиента
OLAP БД или широко используются системы построения отчетов и клиенты pivot-таблиц.
Три технологии ETL, OLAP и генераторы отчетов совместно работают на BI.
В этом докладе, приведена концепция построения типовых OLAP решения и пример предоставления
базового отчета для анализа баланса банка.
Ключи: OLAP, BI, SSIS, REPORTS, ETL
ГЛОССАРИЙ
БД – База данных
OLAP (Online analysis processing) –Аналитическая
обработка в реальном времени
OLTP (Online transaction processing) – Обработка
транзакций в реальному времени
ETL (Extract Transform Load) – Извлечь
Преобразовать Загрузить
MDX (Multidimensional Expressions) –
Многомерный язык запросов
BI (Business Intelligent) – Бизнес анализ
VSFSS – Visual studio for sql server
ПО – Программное обеспечение
SQL (Structural query language) – Структурированный
язык запросов
DDL (Data definition language) – Язык описания
структуры данных
НБУ – Национальный банк Украины
ОДБ – Операционный день банкаМоделі і засоби систем баз даних і знань
1. Постановка задачи
В любом банке более 80% отчетов и нормативов строится на основе бухгалтерского баланса,
соответственно при проверке нормативов и отчетности аналитику и управленцу критично необходимо «видеть»
баланс в удобной структурированной форме.
Использования готовых западных OLAP-решений сомнительна и даже невозможна. Это связанно с
громадным количеством отчетности, требуемых контролирующими органами в Украине, как
государственными так и частными. В связи с этим, отечественные разработчики идут по пути наименьшего
сопротивления и создают продукты, которые учитывают множество избыточной информации, необходимой для
построения отчетности. Поэтому множество тонких моментов, важных для функционировании банка, теряются
в громадных объемах информации.
Выходом из такой ситуации является ведения двух БД, одна содержит всю необходимую информацию
для построения отчетности, как правило, это OLTP БД, вторая содержит «чистые данные», позволяющие
адекватно оценивать качество функционирования банка, как правило, это OLAP БД. Так что приходиться
заново преодолевать путь построения OLAP систем.
Краткое изложения основных этапов построения OLAP решений продемонстрировано на задаче
построения пользовательского разреза баланса. Эта задача поставлена в отделе аналитики одного крупного
банка. Также продемонстрированы результаты прогнозирования состояния банка.
Детали задачи. Количество балансовых счетов бухгалтерского анализа состоит из порядка 1000 счетов,
которые характеризируются так называемыми активностью и пассивностью. Эти счета сгрупирированы, но
каждый банк имеет практику выстраивать свою иерархию для отображения «видения» управляющего
персонала. Каждый балансовый счет ниже по иерархии содержит лицевые счета, которые составляют сумму
балансового счета.
Задача стоит так: построить разрез структурированного баланса, по дням с отображением остатков по
категориям.
Эта задача демонстрирует основный подход и предположения используемые при построении системы
BI на предприятии.
2. Этапы построения OLAP решения
Этап построения законченного аналитического приложения можно разбить на три базовых этапа.
1. Создание схемы OLAP БД.
2. Загрузка и преобразование (опционально) данных из OLTP БД в OLAP БД.
3. Построение необходимого куба (кубов), метрик и измерений.
4. Построение отображения данных пользователю.
Этап 1. Создание схемы OLAP БД. На данном этапе строиться реляционная схема OLAP БД. Как
правило, она состоит из:
- таблиц фактов – содержит в себе факты, например, остаток на счете, объем продаж, число
привлеченных клиентов;
- таблиц измерений – содержит в себе возможные разрезы таблицы фактов, например, дата,
менеджеры, типы продукции;
- отношений между таблицами.
Более детальную информацию о возможных схема OLAP БД можно найти в [1, 2]
Этап 2. Загрузка и преобразование данных из OLTP БД в OLAP. Основное различие OLAP и OLTP –
это степень нормализации данных в БД. Как правило, OLTP БД имеют высокую степень нормализации, а OLAP
глубоко денормализированы для повышения быстродействия операций выборки. Ввиду этого различия, чаще
всего необходимы преобразования данных из OLTP в OLAP.
В реальных системах введется, как минимум, ежедневное обновление аналитических БД. Для
автоматизации актуализации данных в OLAP БД используется комплекс программ под общим названием ETL,
он в буквальном смысле означает:
- извлечь, т.е. получить данные из указанных таблиц OLTP БД;
- преобразовать, т.е. преобразовать схемы OLTP БД в схему OLAP БД;
- загрузить, т.е. непосредственно загрузить данные в OLAP БД.
Этап 3. Построение куба, метрик и измерений. Над реляционной схемой OLAP БД строятся куб(ы).
Куб – концепт, состоящий из множества метрик (measures), таблиц фактов и измерений (dimensions)
(таблиц измерений).
Ключевыми составляющими являются метрики, состоящие из данных содержавшихся в таблице
фактов; измерения – данные содержащиеся в таблице измерений и связанные с мерами, использующие связи
один ко многим. Отметим, что измерения могут выстраиваться в иерархии.
Этот этап необходим для того, чтобы аналитик мог выбрать нужные ему разрезы и проводить анализ
без помощи технического специалиста. На основе описанной схемы проходит проверка целостности,
оптимизация, выборки.
Этап 4. Построение отображения данных пользователю. Этот этап отвечает за создание удобного и
функционального интерфейса для пользователя. Интерфейс должен быть в состоянии: Моделі і засоби систем баз даних і знань
- подключиться к соответствующей службе OLAP;
- иметь понятный и удобный интерфейс;
- обеспечить пользователю выбирать измерения по рядкам и столбцам, а также метрики, которые ему
нужны для анализа;
- возможность экспортировать данные в нужные пользователю форматы;
- опционально, фильтровать данные.
3. Практическая реализация OLAP-решения
Для конкретной реализации выбран BI-инструментарий MS SQL Server 2005, как один из удобных и
гибких для построения решений такого типа. Наличие утилит и инструментов разработчика позволяет в полной
степени покрыть процесс построения аналитического решения, концепция которого раскрыта в разделе 2.
Краткий обзор утилит и инструментов:
1. Для создания реляционной схемы OLAP БД можно использовать любой инструмент, который
генерирует на выходе SQL DDL. Специально для целей MS SQL Server 2005 использует расширение Visio 2003
(2007).
2. Типы проектов в приложении к Visual Studio 2005, которое идет вместе с поставкой MS SQL Server
2005 (этапы 2, 3, 4):
а) проект службы интеграции (Integration services project). Этот проект отвечает за выгрузку,
преобразование и загрузку данных в OLAPо БД (и не только), т.е. это ETL;
б) проект аналитической службы (Analysis services project). В этом проекте создается куб с
измерениями и мерами. Концепция построения состоит в выборе источника данных, определения отношений
между таблицами, создание дополнительных вычислимых полей, создания базового куба непосредственно,
создание/редактирование/удаления измерений/мер и множественного другого функционала, который не
является стандартным, и который мы не будем трогать в данном приложении;
в) проект службы отчетов (Report server project (Report server project wizard)). В этом проекте
создаются базовые виды отчетов для отображения конечному пользователю, включая pivot-таблицы, отчеты,
графики, диаграммы и т.п.
На этап 1 создаются схемы OLAP БД.
Схема БД показана на рис. 1.
Рис. 1. Схема БД
Где DimBalance – таблица, содержащая стандартную разбивку НБУ баланса; DimDayDate – таблица,
содержащая даты. Выделена отдельная таблица для возможностей поделить даты на месяцы, годы, дни недели
и т.п.; DimAlgArticle – иерархия групп счетов, может быть уникальной для каждого банка, департамента и т.п.;
DimAlgItem – балансовые счета групп; FactAmounts – таблица, содержащая факты, как остатки на счетах.
Этап 2 для загрузки и преобразования данных из OLTP БД в OLAP. Этот этап опущен из соображений
высокой сложности и необходимости привязки к конкретным ОДБ. 2.3.
Этап 3 для построение необходимого куба(кубов), метрик и измерений . Моделі і засоби систем баз даних і знань
Общая схема нашего куба, показана на рис. 2.
Где, источник данных является БД (также возможны множественные
источники данных). Здесь указана БД, именуемая Bank Analit.ds;
отображение источника данных(Data Sources Views), является схема БД
указанная на этапе, описанном в подразделе 3.1. Здесь именуемая, как Bank
Analit.dsv; куб, именуемый Bank Analit.cube. Куб содержащий группу мер,
рис 3:
а) сальдо – остаток на балансовом счету в гривне;
б) сальдо в номинале – остаток на балансовом счете в валюте счета;
в)
измерения, соответствуют назначению таблиц, см. подраздел 3.1:
DimBalance.dim; DimDayDate.dim; DimAlgItem.dim; DimAlgArticle.dim.
Этап 4. Построение отображения данных пользователя. Для
отображения пользователю конечных результатов будут использованы два
интерфейса MS Excel 2003, рис. 4; MS SQL Server 2005 Reports Services,
браузерный рис. 5.
Отметим, что MS Excel 2003 имеет встроенные средства для работы
с pivot-таблицами, которые предоставляют конечному пользователю
удобный интерфейс для работы с данными и позволяют строить любые
разрезы без помощи технического специалиста.
Для построения браузерных отчетов, приложения VSFS содержат удобные и понятные визарды для
быстрого построения и установки отчетов на сервер отчетов.
Рис. 4. Пример отображения данных пользователю в MS Excel 2003
Рис. 2. Схема OLAP БД
Рис. 3. Меры OLAP кубаМоделі і засоби систем баз даних і знань
Рис. 5. Пример отображения данных пользователя в браузере
4. Прогнозирование состояния банка
Результаты построения, вышеизложенные использованы в [4] для построения прогнозов данных,
основанных на макроекномических инвариантов выбранных показателей банка. Отметим, что построения
прогноза и поиск инвариантов был бы чрезвычайно сложен или невозможен, без построения аналитических
разрезов баланса банка.
Основная идея построения прогноза такая:
1. Выбор показателя функционирования банка, состоящего из определенного аналитиком набора
балансовых счетов.
2. Построение динамики этого показателя.
3. Поиск среди макроэкономических показателей наиболее «подходящего», т.е. инварината к
выбранному показателю, используя корреляцию и автокорреляцию.
4. Построение или выбор прогноза макроэкономического показателя.
5. Построение прогноза показателя банка.
В работе [4] продемонстрированы, практические результаты этого подхода. Некоторые из них
представлены далее.
Для проверки практичности методологии проведен эксперимент на примере крупного Украинского
банка. Как генеральные совокупности выбраны «средства на текущих счетах в долларах США» и «средства на
текущих и депозитных счетах в гривне», а инвариантами служили такие макропоказатели НБУ, как «курс
доллара США» и «Параметр М0» соответственно. Генеральная выборка состояла из усредненных данных
поквартально с 2001 года по 2006. «Средства на текущих и депозитных счетах в гривне» и «Параметр М0»
скорректированы на инфляцию за период анализа.
Корреляция составила (рис. 6 и 7):
1. «Средства на текущих счетах в долларах США» и «курс доллара США» – -0,774.
2. «Средства на текущих и депозитных счетах в гривне» и «Параметр М0» – 0,947.
2 4 6 8 10 12 14 16 18 20 22 24
2 4 6 8 10 12 14 16 18 20 22 24
500Моделі і засоби систем баз даних і знань
Рис. 6. Анализ тренда для «Средства на текущих счетах в долларах США» и «курс доллара США»
2 4 6 8 10 12 14 16 18 20 22 24
2 4 6 8 10 12 14 16 18 20 22 24
Рис. 7. Анализ тренда для «Средства на текущих и депозитных счетах в гривне» и «Параметр М0»
Исходя из анализа тренда видно, что при отрицательной корреляции имеем зеркально отображенный
тренд на графике «курс доллара США». Также тренды генеральных совокупностей и инвариантов повторяют
тенденции один другого, что позволяет сделать вывод о правильности выбора инвариантов.
Результаты автокорреляционного анализа, показаны на рис. 8 и 9, показывает соответствие
генеральных выборок и инвариантов.
Наличие инвариантов позволяет прогнозировать состояние макропоказателей (или использовать уже
готовые прогнозы). Поскольку макропоказатели агрегируют большие объемы данных, таким образом
сглаживая аномалии, прогнозы построенные на их базе являются более точными. В таблице приведены
результаты прогнозирования для 4-х вышеуказанных выборок.
1 2 3 4 5 6
1,0
0,8
0,6
0,4
0,2
0,0
-0,2
-0,4
-0,6
-0,8
-1,0
1 2 3 4 5 6
1,0
0,8
0,6
0,4
0,2
0,0
-0,2
-0,4
-0,6
-0,8
-1,0
Рис. 8. Автокорреляционный анализ для «Средства на текущих счетах в долларах
США» и «курс доллара США»
1 2 3 4 5 6
1,0
0,8
0,6
0,4
0,2
0,0
-0,2
-0,4
-0,6
-0,8
-1,0
1 2 3 4 5 6
1,0
0,8
0,6
0,4
0,2
0,0
-0,2
-0,4
-0,6
-0,8
-1,0
Рис. 9. Автокорреляционный анализ для «Средства на текущих и депозитных
счетах в гривне» и «Параметр М0»
Таблица 2. Прогнозные значения
Год Квартал
Курс
доллара
США
Средства на
текущих счетах
в долларах
США
Параметр
М0
Средства на
текущих и
депозитных
счетах в
гривне
2007 I 505 10593418 28813,82289 398274185,2
Прогнозное 504,05 13875012 29592 443301392
MAPE 0,4501 31,54 6 10,85
MAD 2,3556 2 375 730 1514 32 158 800 Моделі і засоби систем баз даних і знань
Как видно из результатов прогнозирования, MAPE как минимум в 1,8 раза меньше для инвариантов, чем для
генеральных совокупностей.
Эксперимент поставлен на обычном персональном компьютере, что обусловлено отсутствием
ресурсоемкости задач. При анализе больших объемов данных можно воспользоваться распараллеливанием