ХАРАКТЕРИСТИКИ АССОЦИАТИВНЫХ ПРАВИЛ
Ассоциативное правило имеет вид: «Из события A следует событие B».
В результате такого видеоанализа устанавливаем закономерность следующего вида: «Если в транзакции встретился набор товаров (или набор элементов) A, то можно сделать вывод, что в этой же транзакции должен появиться набор элементов B)» Установление таких закономерностей дает нам возможность находить очень простые и понятные правила, называемые ассоциативными [13–15].
Основными характеристиками ассоциативного правила являются поддержка и достоверность правила.
Рассмотрим правило «из покупки геля для душа следует покупка мыла» для базы данных, которая была приведена выше в таблице 2.2. Понятие поддержки набора уже рассмотрели. Существует понятие поддержки правила.
Правило имеет поддержку s, если s% транзакций из всего набора содержат одновременно наборы элементов A и B или, другими словами, содержат оба товара.
Гель для душа – это товар A, мыло это товар B. Поддержка правила «из покупки геля для душа следует покупка мыла» равна 3, или 50%.
Достоверность правила показывает, какова вероятность того, что из события A следует событие B.
Правило «Из A следует B» справедливо с достоверностью с, если c% транзакций из всего множества, содержащих набор элементов A, также содержат набор элементов B. Число транзакций, содержащих гель для душа, равно четырем, число транзакций, содержащих мыло, равно трем, достоверность правила равна (3/4)*100%, т.е. 75%.
Достоверность правила «из покупки геля для душа следует покупка мыла» равна 75%, т.е. 75% транзакций, содержащих товар А, также содержат товар B [13–15].
Рассмотрим границы поддержки и достоверности ассоциативного правила. При помощи использования алгоритмов поиска ассоциативных правил аналитик может получить все возможные правила вида «Из A следует B», с различными значениями поддержки и достоверности. Однако в большинстве случаев, количество правил необходимо ограничивать заранее установленными минимальными и максимальными значениями поддержки и достоверности.
Если значение поддержки правила слишком велико, то в результате работы алгоритма будут найдены правила очевидные и хорошо известные. Слишком низкое значение поддержки приведет к нахождению очень большого количества правил, которые, возможно, будут в большей части необоснованными, но не известными и не очевидными для аналитика. Таким образом, необходимо определить такой интервал, «золотую середину», который с одной стороны обеспечит нахождение неочевидных правил, а с другой – их обоснованность [14–16].
Если уровень достоверности слишком мал, то ценность правила вызывает серьезные сомнения. Например, правило с достоверностью в 3% только условно можно назвать правилом.
МЕТОДЫ ПОИСКА АССОЦИАТИВНЫХ ПРАВИЛ
На сегодняшний день существует большое количество методов поиска ассоциативных правил в разных источниках данных. Основными являются методы AIS и SETM. Рассмотрим более подробно каждый из этих методов.
АЛГОРИТМ AIS
Первый алгоритм поиска ассоциативных правил, называвшийся AIS, (предложенный Agrawal, Imielinski and Swami) был разработан сотрудниками исследовательского центра IBM Almaden в 1993 году. С этой работы начался интерес к ассоциативным правилам; на середину 90-х годов прошлого века пришелся пик исследовательских работ в этой области, и с тех пор каждый год появляется несколько новых алгоритмов [14–16].
В алгоритме AIS кандидаты множества наборов генерируются и подсчитываются «на лету», во время сканирования базы данных. Каждая транзакция проверяется на наличие больших наборов, выявленных при предыдущем проходе. Соответственно, новые наборы формируются путем расширения имеющихся наборов. Этот алгоритм неэффективен, поскольку генерирует и учитывает слишком много наборов-кандидатов, которые недостаточно большие (нечастые).
АЛГОРИТМ SETM
Создание этого алгоритма было мотивировано желанием использовать язык SQL для вычисления часто встречающихся наборов товаров. Как и алгоритм AIS, SETM также формирует кандидатов «на лету», основываясь на преобразованиях базы данных. Чтобы использовать стандартную операцию объединения языка SQL для формирования кандидата, SETM отделяет формирование кандидата от их подсчета [14–16].
Неудобство алгоритмов AIS и SETM излишнее генерирование и подсчет слишком многих кандидатов, которые в результате не оказываются часто встречающимися. Для улучшения их работы был предложен алгоритм Apriori.
Работа данного алгоритма состоит из нескольких этапов, каждый из этапов состоит из следующих шагов:
а) формирование кандидатов;
б) подсчет кандидатов.
Формирование кандидатов (candidate generation) этап, на котором алгоритм, сканируя базу данных, создает множество i-элементных кандидатов (i – номер этапа). На этом этапе поддержка кандидатов не рассчитывается.
Подсчет кандидатов (candidate counting) этап, на котором вычисляется поддержка каждого i-элементного кандидата. Здесь же осуществляется отсечение кандидатов, поддержка которых меньше минимума, установленного пользователем (min_sup). Оставшиеся i-элементные наборы называем часто встречающимися.
Рассмотрим работу алгоритма Apriori на примере базы данных D. Иллюстрация работы алгоритма приведена на рисунке 2.1. Минимальный уровень поддержки равен 3.
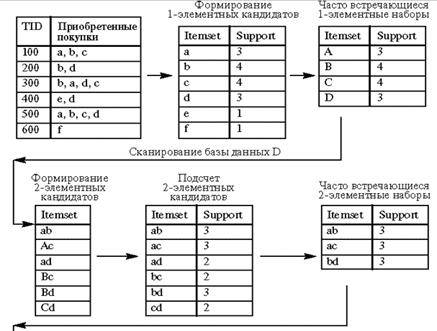

Рисунок 2.1 – Алгоритм Apriori
На первом этапе происходит формирование одноэлементных кандидатов. Далее алгоритм подсчитывает поддержку одноэлементных наборов. Наборы с уровнем поддержки меньше установленного, то есть 3, отсекаются. В нашем примере это наборы e и f, которые имеют поддержку, равную 1. Оставшиеся наборы товаров считаются часто встречающимися одноэлементными наборами товаров: это наборы a, b, c, d.
Далее происходит формирование двухэлементных кандидатов, подсчет их поддержки и отсечение наборов с уровнем поддержки, меньшим 3. Оставшиеся двухэлементные наборы товаров, считающиеся часто встречающимися двухэлементными наборами ab, ac, bd, принимают участие в дальнейшей работе алгоритма.
Если смотреть на работу алгоритма прямолинейно, на последнем этапе алгоритм формирует трехэлементные наборы товаров: abc, abd, bcd, acd, подсчитывает их поддержку и отсекает наборы с уровнем поддержки, меньшим 3. Набор товаров abc может быть назван часто встречающимся.
Однако алгоритм Apriori уменьшает количество кандидатов, отсекая – априори тех, которые заведомо не могут стать часто встречающимися, на основе информации об отсеченных кандидатах на предыдущих этапах работы алгоритма [14–16].
Отсечение кандидатов происходит на основе предположения о том, что у часто встречающегося набора товаров все подмножества должны быть часто встречающимися. Если в наборе находится подмножество, которое на предыдущем этапе было определено как нечасто встречающееся, этот кандидат уже не включается в формирование и подсчет кандидатов.
Так наборы товаров ad, bc, cd были отброшены как нечасто встречающиеся, алгоритм не рассматривал товаров abd, bcd, acd.
При рассмотрении этих наборов формирование трехэлементных кандидатов происходило бы по схеме, приведенной в верхнем пунктирном прямоугольнике. Поскольку алгоритм априори отбросил заведомо нечасто встречающиеся наборы, последний этап алгоритма сразу определил набор abc как единственный трехэлементный часто встречающийся набор (этап приведен в нижнем пунктирном прямоугольнике).
Алгоритм Apriori рассчитывает также поддержку наборов, которые не могут быть отсечены априори. Это так называемая негативная область (negative border), к ней принадлежат наборы-кандидаты, которые встречаются редко, их самих нельзя отнести к часто встречающимся, но все подмножества данных наборов являются часто встречающимися.
В зависимости от размера самого длинного часто встречающегося набора алгоритм Apriori сканирует базу данных определенное количество раз. Разновидности алгоритма Apriori, являющиеся его оптимизацией, предложены для сокращения количества сканирований базы данных, количества наборов-кандидатов или того и другого. Были предложены следующие разновидности алгоритма Apriori: AprioriTID и AprioriHybrid [14–16].
а) AprioriTid.
Интересная особенность этого алгоритма то, что база данных D не используется для подсчета поддержки кандидатов набора товаров после первого прохода.
С этой целью используется кодирование кандидатов, выполненное на предыдущих проходах. В последующих проходах размер закодированных наборов может быть намного меньше, чем база данных, и таким образом экономятся значительные ресурсы.
б) AprioriHybrid.
Анализ времени работы алгоритмов Apriori и AprioriTid показывает, что в более ранних проходах Apriori добивается большего успеха, чем AprioriTid; однако AprioriTid работает лучше Apriori в более поздних проходах. Кроме того, они используют одну и ту же процедуру формирования наборов-кандидатов. Основанный на этом наблюдении, алгоритм AprioriHybrid предложен, чтобы объединить лучшие свойства алгоритмов Apriori и AprioriTid. AprioriHybrid использует алгоритм Apriori в начальных проходах и переходит к алгоритму AprioriTid, когда ожидается, что закодированный набор первоначального множества в конце прохода будет соответствовать возможностям памяти. Однако, переключение от Apriori до AprioriTid требует вовлечения дополнительных ресурсов.
Некоторыми авторами были предложены другие алгоритмы поиска ассоциативных правил, целью которых также было усовершенствование алгоритма Apriori. Кратко изложим суть нескольких, для более подробной информации можно рекомендовать [14–16].
Один из них алгоритм DHP, также называемый алгоритмом хеширования. В основе его работы вероятностный подсчет наборов-кандидатов, осуществляемый для сокращения числа подсчитываемых кандидатов на каждом этапе выполнения алгоритма Apriori. Сокращение обеспечивается за счет того, что каждый из k-элементных наборов-кандидатов помимо шага сокращения проходит шаг хеширования. В алгоритме на k-1 этапе во время выбора кандидата создается так называемая хеш-таблица. Каждая запись хеш-таблицы является счетчиком всех поддержек k-элементных наборов, которые соответствуют этой записи в хеш-таблице. Алгоритм использует эту информацию на этапе k для сокращения множества k-элементных наборов-кандидатов. После сокращения подмножества, как это происходит в Apriori, алгоритм может удалить набор-кандидат, если его значение в хеш-таблице меньше порогового значения, установленного для обеспечения [14–16].
К другим усовершенствованным алгоритмам относятся: PARTITION, DIC, алгоритм «выборочного анализа».
PARTITION алгоритм. Этот алгоритм разбиения (разделения) заключается в сканировании транзакционной базы данных путем разделения ее на непересекающиеся разделы, каждый из которых может уместиться в оперативной памяти. На первом шаге в каждом из разделов при помощи алгоритма Apriori определяются «локальные» часто встречающиеся наборы данных. На втором подсчитывается поддержка каждого такого набора относительно всей базы данных. Таким образом, на втором этапе определяется множество всех потенциально встречающихся наборов данных.
Алгоритм DIC, Dynamic Itemset Counting. Алгоритм разбивает базу данных на несколько блоков, каждый из которых отмечается так называемыми «начальными точками» (start point), и затем циклически сканирует базу данных.