THE STRUCTURALIST APPROACH
At the beginning of the twentieth century, Ferdinand de Saussure had developed a new theory of language. He considered natural language as a structure of mutually linked elements, similar or opposed to each other. Later, several directions arose in general linguistics and many of them adhered to the same basic ideas about language. This common method was called structuralism, and the corresponding scientific research (not only in linguistics, but also in other sciences belonging to the humanities) was called structuralist.
Between the 1920’s and the 1950’s, several structuralist schools were working in parallel. Most of them worked in Europe, and European structuralism kept a significant affinity to the research of the previous periods in its terminology and approaches.
Meantime, American structuralists, Leonard Bloomfield among them, made claims for a fully “objective” description of natural languages, with special attention to superficially observable facts. The order of words in a sentence was considered the main tool to become aware of word grouping and sentence structures. At this period, almost every feature of English seemed to confirm this postulate. The sentences under investigation were split into the so-called immediate constituents, or phrases, then these constituents were in their turn split into subconstituents, etc., down to single words. Such a method of syntactic structuring was called the phrase structure, or constituency, approach.
INITIAL CONTRIBUTION OF CHOMSKY
In the 1950’s, when the computer era began, the eminent American linguist Noam Chomsky developed some new formal tools aimed at a better description of facts in various languages [12].
Among the formal tools developed by Chomsky and his followers, the two most important components can be distinguished:
· A purely mathematical nucleus, which includes generative grammars arranged in a hierarchy of grammars of diverse complexity. The generative grammars produce strings of symbols, and sets of these strings are called formal languages, whereas in general linguistics they could be called texts. Chomskian hierarchy is taught to specialists in computer science, usually in a course on languages and automata. This redeems us from necessity to go into any details. The context-free grammars constitute one level of this hierarchy.
· Attempts to describe a number of artificial and natural languages in the framework of generative grammars just mentioned. The phrase structures were formalized as context-free grammars (CFG) and became the basic tool for description of natural languages, in the first place, of English. Just examples of these first attempts are extensively elaborated in the manuals on artificial intelligence. It is a good approach unless a student becomes convinced that it is the only possible.
A SIMPLE CONTEXT-FREE GRAMMAR
Let us consider an example of a context-free grammar for generating very simple English sentences. It uses the initial symbol S of a sentence to be generated and several other non-terminal symbols: the noun phrase symbol NP, verb phrase symbol VP, noun symbol N, verb symbol V, and determinant symbol D. All these non-terminal symbols are interpreted as grammatical categories.
Several production rules for replacement of a non-terminal symbol with a string of several other non-terminal symbols are used as the nucleus of any generative grammar. In our simple case, let the set of the rules be the following:
S® NP VP
VP ® V NP
NP® D N
NP® N
Each symbol at the right side of a rule is considered a constituent of the entity symbolized at the left side. Using these rules in any possible order, we can transform S to the strings DN V D N, or D N V N, or N V D N, or N V N, etc.
An additional set of rules is taken to convert all these non-terminal symbols to the terminal symbols corresponding to the given grammatical categories. The terminals are usual words of Spanish, English, or any other language admitting the same categories and the same word order. We use the symbol “|” as a metasymbol of an alternative (i.e. for logical OR). Let the rules be the following:
N ® estudiante | niña | María | canción | edificio...
V ® ve | canta | pregunta...
D ® el | la | una | mi | nuestro...
Applying these rules to the constituents of the non-terminal strings obtained earlier, we can construct a lot of fully grammatical and meaningful Spanish sentences like María ve el edificio (from N V D N) or la estudiante canta una canción (from DN V D N). Some meaningless and/or ungrammatical sentences likecanción ve el María can be generated too. With more complicate rules, some types of ungrammaticality can be eliminated. However, to fully get rid of potentially meaningless sentences is very difficult, since from the very beginning the initial symbol does not contain any specific meaning at all. It merely presents an abstract category of a sentence of a very vast class, and the resulting meaning (or nonsense) is accumulated systematically, with the development of each constituent.
On the initial stage of the elaboration of the generative approach, the idea of independent syntax arose and the problem of natural language processing was seen as determining the syntactic structure of each sentence composing a text. Syntactic structure of a sentence was identified with the so-called constituency tree. In other words, this is a nested structuresubdividing the sentence into parts, then these parts into smaller parts, and so on. This decomposition corresponds to the sequence of the grammar rules applications that generate the given sentence. For example, the Spanish sentence la estudiante canta una canción has the constituency tree represented graphically in Figure II.1. It also can be represented in the form of the following nested structure marked with square brackets:
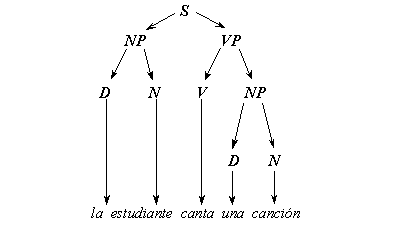 FIGURE II.1. Example of constituency tree.
FIGURE II.1. Example of constituency tree.
|
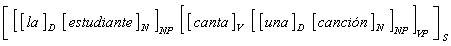
This structure shows the sentence S consisting of a noun phrase NP and a verb phrase VP, that in its turn consists of a verb V followed by a noun phrase NP, that in its turn consists of a determiner D (an articleor pronoun) followed by a noun N that is the word canción, in this case.
TRANSFORMATIONAL GRAMMARS
Further research revealed great generality, mathematical elegance, and wide applicability of generative grammars. They became used not only for description of natural languages, but also for specification of formal languages, such as those used in mathematical logic, pattern recognition, and programming languages. A new branch of science called mathematical linguistics (in its narrow meaning) arose from these studies.
During the next three decades after the rise of mathematical linguistics, much effort was devoted to improve its tools for it to better correspond to facts of natural languages. At the beginning, this research stemmed from the basic ideas of Chomsky and was very close to them.
However, it soon became evident that the direct application of simple context-free grammars to the description of natural languages encounters great difficulties. Under the pressure of purely linguistic facts and with the aim to better accommodate the formal tools to natural languages, Chomsky proposed the so-calledtransformational grammars. They were mainly English-oriented and explained how to construct an interrogative or negative sentence from the corresponding affirmative one, how to transform the sentence in active voice to its passive voice equivalent, etc.
For example, an interrogative sentence such as Does John see Mary? does not allow a nested representation as the one shown on page 37 since the two words does and see obviously form a single entity to which the word John does not belong. Chomsky’s proposal for the description of its structure consisted in
(a) description of the structure of some “normal” sentence that does permit the nested representation plus
(b) description of a process of obtaining the sentence in question from such a “normal” sentence by its transformation.
Namely, to construct the interrogative sentence from a “normal” sentence “John sees Mary.”, it is necessary
(1) to replace the period with the question mark (*John sees Mary?),
(2) to transform the personal verb form see into a word combination does see (*John does see Mary?), and finally
(3) to move the word does to the beginning of the sentence (Does John see Mary?), the latter operation leading to the “violation” of the nested structure.
This is shown in the following figure:
| S | |||||||||||||
| Nested: |  John John
| N | does see | V | Mary | N | VP | ? | |||||
| Not nested: | Does | John | N | see | V | Mary | N | ? |
A transformational grammar is a set of rules for such insertions, permutations, movements, and corresponding grammatical changes. Such a set of transformational rules functions like a program. It takes as its input a string constructed according to some context-free grammar and produces a transformed string.
The application of transformational grammars to various phenomena of natural languages proved to be rather complicated. The theory has lost its mathematical elegance, though it did not acquire much of additional explanatory capacity.