И их роль в анализе информации
В результате первой стадии статистического исследования получают статистическую информацию, представляющую собой большое количество первичных, разрозненных сведений об отдельных единицах объекта исследования. Для приведения и систематизации этих материалов необходимо провести их сводку (вторая стадия статистического исследования). На основе сводки дают сводную характеристику всей совокупности фактов при помощи обобщающих статистических показателей.
Статистическая сводка (С.С.) представляет собой первичную обработку данных статистического наблюдения с целью их систематизации для получения обобщающих сведений изучаемого явления по ряду существенных признаков.
С.С. позволяет перейти к обобщающим показателям совокупности в целом и отдельных ее частей, осуществлять анализ и прогнозирование изучаемых процессов.
2. Виды сводок.
I. В зависимости от цели и задач.
1) Простая С. – если производится только подсчет общих итогов по изучаемой совокупности единиц наблюдения (чтобы узнать общую численность студентов России достаточно сложить данные о численности студентов в каждом ВУЗе). Программа простой сводки – подсчет отдельных фактов.
2) Сложная С. осуществляется с применением метода статистических группировок.
С.С. проводится по определенной программе и плану.
Программа С.С. устанавливает следующие этапы:
– выбор группировочных признаков;
– определение порядка формирования групп;
– разработка системы статистических показателей для характеристики групп или объектов в целом;
– разработка макетов статистических таблиц для представления результатов сводки.
План С.С. содержит указания о последовательности и сроках выполнения отдельных частей сводки, ее исполнителях и о порядке изложения и представления результатов.
II. По технике или способу выполнения сводка может быть:
1) ручной;
2) механической (ЭВМ).
III. По форме обработки данных:
1) децентрализованная (обработка статистических данных проводится поэтапно от отдельных территорий к центру);
2) централизованная (обработка данных осуществляется от начала до конца в одной организации, например, перепись населения).
В сводке статистического материала отдельные единицы статистической совокупности объединяются в группы при помощи метода группировок.
Статистическая группировка – это разделение единиц совокупности на группы и подгруппы по определенным характерным достаточным признакам для глубокого и всестороннего изучения.
Признаки, по которым производится распределение единиц изучаемой совокупности на группы, называются группировочными (Г.П.), или основанием группировки.
При выборе Г.П. необходимо учитывать, что одни и те же признаки могут иметь различные значения в зависимости от конкретных условий, места и времени.
Различают следующие виды Г.П.: – атрибутивные (качественные) (А.П.):
– количественные; (К.П.)
– признаки пространства; (П.П.)
– признаки времени. (П.В.)
А.П.характеризует свойство, качество данного явления и не имеет количественного выражения. При группировке по А.П. статистическая совокупность разделяется на столько групп, сколько разновидностей имеет признак (по полу – на две, по национальному составу – столько, сколько существует национальностей и т.д.).
Если А.П. имеет большое количество разновидностей (профессии, наименование выпускаемой продукции и др.), то для обоснованного их объединения разрабатывают номенклатуры и классификации.
К.П.характеризует размер, величину, изучаемой совокупности и дающий возможность расчленить ее на группы по величине индивидуальных значений группировочного признака.
При группировке по К.П. изучаемую совокупность подразделяют по уровню, или величине признака.
П.П.– это адресный признак (адрес предприятия, фирмы компании и т.д.) применяется для изучения пространственных закономерностей.
П.В. позволяет установить хронологию событий (даты, годы, сезон и т.д.).
Задачи группировки: 1) выделить социально-экономические типы явлений (чтобы дать правильное статистическое освещение собранных материалов, необходимо заранее установит перечень показателей, по которым надо получить сводные данные для характеристики исследуемых явлений. Так, для характеристики работы торговых компаний, фирм, предприятий и т.д. важное значение имеют такие показатели, как объем товарооборота, численность работников, издержки обращения, запасы товаров и т.д.);
2) дать характеристику состава совокупности по какому-либо признаку в пределах уже определенного социально-экономического типа (чтобы дать более полню характеристику в пределах определенного типа необходимо разделить его на подгруппы. Например, количество студентов, поступивших на различные факультеты можно разделить на студентов, обучающихся на очной и заочной форме обучения; получающих первое или второе образование и т.д.);
3) выявить взаимосвязи в изменениях изучаемых признаков (явления жизни и их признаки тесно связаны между собой. Группируя торговые предприятия по размеру розничного товарооборота и исчисляя для каждой группы средний уровень расходов, можно статистически выразить, насколько тесна эта связь. Подобная аналитическая группировка показывает, что уровень издержек обращения на крупных предприятиях в среднем ниже, чем в мелких. Поэтому крупные магазины имеют повышенную рентабельность по сравнению с мелкими. Посредством группировки можно выявить, что объем розничного товарооборота на одно торговое предприятие в городской торговле больше, чем в сельской. Следовательно, в торговых предприятиях, расположенных в городе, расход ниже, чем в функционирующих в сельской местности).
Виды группировок.
I. В зависимости от цели выделяют следующие виды статистических группировок:
1) Типологическая группировка – выделяет важнейшие социально-экономические типы качественно однородных явлений. Примерами типологической группировки могут служить группировки секторов экономики, хозяйствующих субъектов по форме собственности (группы предприятий государственной собственности, федеральной, муниципальной, частной и смешанной собственности).
В типологической группировке число групп определяется, как правило, количеством выделяемых типов явлений. Например, группируя фирмы, входящие в холдинг по степени выполнения прогнозируемого объема произведенной продукции, мы заранее определяем необходимое число групп (фирмы, не достигшие объема прогнозных показателей; достигшие объема прогнозных показателей; перевыполнившие прогнозные показатели).
Определение: Классификация – закрепленное, твердо установленное распределение явлений и объектов на определенные классы, разряды, группы со сложной группировкой, предусматривающие общие и частные итоги (классификация отраслей и производств в промышленности, оборудования, профессий и т.д.).
Классификации устойчивы, не изменяются с течением времени, стандартны.
2) Структурная группировка– группировка, в которой происходит разделение выделенных с помощью типологической группировки типов явлений, однородных совокупностей на группы, характеризующие их структуру по какому-либо варьирующему признаку (группировка населения по размеру среднедушевого дохода, хозяйств по объему продукции, распределение детей в возрасте 7-15 лет по размерам носимой обуви и т.д.).
3) Аналитическая (факторная) группировка – выявляет наличие и характер взаимосвязи между двумя варьирующими признаками. При этом зависимый признак называется результативным, а признак, под влиянием которого изменяется результативный, – факторным. В основе аналитической группировки лежит факторный признак, и каждая выделенная группа характеризуется средними значениями результативного признака.
II. В зависимости от степени сложности массового явления и от задач анализа группировки могут производиться:
1) по одному (простая группировка) признаку;
2) по нескольким признакам (сложная (комбинационная) группировка).
Комбинационная группировка позволяет выявить и сравнить различия и связи между исследуемыми признаками, которые нельзя обнаружить на основе изолированных группировок по ряду группировочных признаков. Однако, при изучении влияния большого числа признаков применение комбинационных группировок становиться невозможным, поскольку чрезмерное дробление информации затушевывает проявление закономерностей. Даже при наличии большого массива первичной информации приходится ограничиваться двумя-четырьмя признаками.
Интервалы группировок. При составлении структурных группировок на основе варьирующих количественных признаков необходимо определить количество групп и интервал группировки.
Интервал – это разность между наибольшим и наименьшим значением признака, т.е. промежуток изменения числового значения признака для каждой группы в пределах «от – до».
Интервалы могут быть равные и неравные.
Количество групп зависит от числа единиц исследуемого объекта и интервала изменения группировочного признака. При небольшом объеме совокупности нельзя образовывать большое число групп, т.к. группы будут малочисленными. Число групп должно быть оптимальным.
Ориентировочно определить оптимальное количество групп с равным интервалом можно по формуле американского ученого Стерджесса:
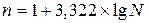 (1)
(1)
где  – численность единиц совокупности.
– численность единиц совокупности.
Равные интервалы применяются, если изменение количественного признака внутри происходит равномерно. Величина такого интервала рассчитывается по формуле
 (2)
(2)
где,  ,
,  – наибольшее и наименьшее значение признака;
– наибольшее и наименьшее значение признака;  – число групп.
– число групп.
Пример 1. Необходимо провести группировку акционеров по размеру выплат дивидендов, образовав группы с равными интервалами, если известны следующие данные о размере дивидендов в рублях: 432, 91, 937, 431, 408, 920, 677, 148, 217, 476, 810, 449, 8, 749, 566, 954, 133, 855, 56, 95, 970, 712, 951, 58, 654, 15, 723, 797, 569, 421, 191, 262, 160, 719, 373, 770, 554, 449, 692, 101, 691, 823, 628, 991, 485, 15, 260, 412, 614, 759, 784, 869, 309, 485, 221, 687, 960, 447, 523, 127, 371, 586, 204, 734, 896, 230, 607, 242, 396, 227, 735, 308, 102, 923, 354, 637, 755, 261, 158, 815, 66, 350, 367, 819, 902, 110, 566, 200, 907, 34, 473, 77, 415, 972, 301, 192, 24.
Решение. Количество интервалов определяется следующим образом:

Величина равных интервалов определяется так:
 рубля.
рубля.
Подсчитаем число АО, в % от их общего количества в группе и занесем в таблицу.
Таблица 1
| АО с размером дивидендов, руб | Число АО | Число АО, в % от их общего количества | Число АО, в % от их общего количества нарастающим итогом |
| 7 – 130 130 – 253 253 – 376 376 – 499 499 – 622 622 – 745 745 – 868 868 – 991 | |||
| ИТОГО | – |
Первый интервал означает, что размер дивидендов будет не менее 7 рублей, но не более 130 рублей, т.е. АО с размером дивидендов 130 рублей в первую группу не войдут, но войдут во вторую группу. Такой подход к формированию групп следует сохранять и далее. Единственное исключение составит последняя группа.
Как видим, интервалы групп могут быть закрытыми, когда указаны и верхняя и нижняя границы (как в последнем интервале, приведенного выше примера) и открытыми, когда указана лишь одна из границ (остальные интервалы, в приведенном выше примере).
Все сказанное выше относится к группировкам, которые производятся на основе анализа первичного статистического материала. Но иногда приходится сравнивать группировки, которые могут быть несопоставимыми. Для приведения таких группировок к сопоставимому виду в целях их дальнейшего сравнительного анализа используется метод вторичной группировки.
Вторичная группировка – это образование новых групп на основе ранее осуществленной группировки.
Пример 2. Пусть дана еще одна группировка акционеров по размеру выплат дивидендов. Необходимо сравнить распределение акционеров этих районов по размеру дивидендов на одну акцию. При данных условиях это невозможно. Необходимо интервалы в рядах привести к сопоставимому виду. За основу сравнения возьмем структуру распределения акционеров второго района.
Таблица 2
| Первый район | Второй район | ||
| АО с размером дивидендов, руб. | Число АО, в % от их общего количества | АО с размером дивидендов, руб. | Число АО, в % от их общего количества |
| 7 – 130 130 – 253 253 – 376 376 – 499 499 – 622 622 – 745 745 – 868 868 – 991 | 0 – 250 250 – 600 600 – 800 800 – 1000 – – – – | – – – – | |
| Итого | Итого |
Следовательно, по первому району нужно произвести перегруппировку (вторичную группировку), образовав такое же число групп и с теми же интервалами, как во втором районе.
Таблица 3
| № группы | АО с размером дивидендов, руб. | Число АО, в % от их общего количества | Расчет | |
| Второй район | Первый район | |||
| 0 – 250 250 – 600 600 – 800 800 – 1000 | 



| |||
| Итого |
Анализ сопоставимых данных вторичной группировки позволяет сделать вывод о том, что акционеры второго района имеют более высокие размеры дивидендов (600 руб. и более на одну акцию выплачивают 70 % акционеров этого района, а в первом – только 42 % акционеров).
Ряды распределения
После определения группировочного признака и границ групп, строится ряд распределения.
Статистический ряд распределения представляет собой упорядоченное распределение единиц изучаемой совокупности на группы по определенному варьирующему признаку.
Виды рядов распределения:
1) атрибутивные (построенные по атрибутивным признакам). Например, распределение населения по полу, занятости, национальности, профессии и т.д.
2) вариационные (построенные по количественному признаку). Например, распределение населения по возрасту, рабочих – по стажу работы, заработной плате и т.д.
Обязательными элементами вариационного ряда распределения являются варианты и частоты.
Числовые значения количественного признака в вариационном ряду распределения называются вариантами и обозначаются  .
.
Они могут быть положительными и отрицательными, абсолютными и относительными. Так, при группировке предприятий по результатам хозяйственной деятельности варианты положительные (прибыль) и отрицательные (убыток) числа.
Частоты – это численности отдельных вариантов или каждой группы вариационного ряда, т.е. это числа, показывающие, как часто встречаются те или иные варианты в ряду распределения и обозначаются  .
.
Сумма всех частот называется объемом совокупности и определяет число элементов всей совокупности. Производными частот в статистике являются частности.
Частости – это частоты, выраженные в виде относительных величин (долях единиц или процентах).
Сумма частостей равна единице или 100 %. Замена частот частостями позволяет сопоставлять вариационные ряды с разным числом наблюдений.
В зависимости от характера вариации ряды распределения делятся на дискретные и интервальные.
Дискретные вариационные ряды основаны на дискретных (прерывных) признаках, имеющих только целые значения (например, тарифный разряд рабочих, число детей в семье).
Интервальные – на непрерывных признаках (имеющих любые значения, в том числе и дробные).
Т.к. на первый взгляд тяжело оценить представленные ряды, их необходимо упорядочить, т.е. расположить его в возрастающем (или убывающем) порядке. Это действие в статистике называется ранжированием.
Например, в вышеприведенном примере № 1, ранжированный ряд будет иметь вид: 7, 13, 15, 27, 34, 38, 46, 64, 106, 112, 116, 121, 127, 140, 141, 150, 153, 176, 209, 214, 216, 222, 230, 235, 239, 253, 267, 295, 327, 328, 340, 347, 376, 390, 397, 432, 435, 440, 448, 448, 450, 475, 490, 494, 495, 500, 500, 504, 508, 509, 509, 513, 514, 515, 532, 535, 538, 542, 549, 595, 615, 636, 641, 641, 647, 647, 650, 654, 661, 664, 667, 690, 707, 745, 752, 773, 775, 796, 798, 804, 806, 823, 825, 840, 857, 861, 881, 896, 901, 902, 908, 908, 940, 949, 957, 960, 971, 974, 976, 991.
При рассмотрении первичных данных можно видеть, что одинаковые варианты признака у отдельных единиц повторяются (  – частота повторений,
– частота повторений,  – объем изучаемой совокупности).
– объем изучаемой совокупности).
Способы построения дискретных и интервальных рядов различны. Ряды распределения удобно представлять в виде таблиц и графиков.
Статистические таблицы. Таблица может быть наглядным, кратким и последовательным изложением полученных цифровых данных.
Основанием любой таблицы является сетка – скелет, в которой вертикальные столбцы называются графами, а горизонтальные – строками. Внешне таблицы представляют собой сетку из вертикальных и горизонтальных линий, в которой записываются числовые данные.
В ней выделяются две составляющие: подлежащее и сказуемое.
Статистическое подлежащее таблицы (стрóки) – это то, о чем говорится и что характеризуется в таблице (объект изучения).
Статистическое сказуемое таблицы (грáфы) показывает, какими признаками характеризуется подлежащее.
Название таблицы (общий заголовок)
| Заголовок подлежащего | Заголовок сказуемого | ||||||
 Строки Строки
| А |  4 4
| |||||
| под | Нумерация граф | ||||||
  лежа лежа
| 
| Сказуемое (гр. 1-5) | |||||
 щего щего
|
| 
| 
|
|
| 
| Итоговая графа |
итоговая строка Графы (столбцы, колонки)
Виды таблиц: 1) простые;
2) групповые;
3) комбинационные.
1) в простой таблице подлежащее не делится на группы. В этом случае возможны два варианта:
- таблица содержит данные по совокупности в целом;
- таблица содержит данные о каждой единице совокупности.
Подлежащее этой таблицы вынесено в заголовок, сама таблица – это сказуемое, причем значения показателей даны в динамике.
Таблица 4
Среднедушевые денежные доходы в месяц (руб.)
| Наименование | ||
| А | ||
| Российская Федерация Центральный федеральный округ Московская область Москва | 3 950 5 314 3 405 13 672 | 5 000 7 510 4 864 20 751 |
2) групповая таблица – таблица, в которой подлежащее разделено на группы по какому-либо одному признаку.
Например, распределение безработных по уровню образования, %
Таблица 5
| Уровень образования | ||
| Всего В том числе: Высшее профессиональное Неполное высшее профессиональное Среднее профессиональное Среднее общее Основное общее Не имеют основного общего | 100,0 9,2 2,2 28,6 40,8 17,9 1,3 | 100,0 13,8 2,7 24,0 36,3 19,5 3,8 |
3) Комбинационными называются такие таблицы, в которых подлежащее делится на группы не по одному, а по нескольким признакам, причем каждая группа, образованная по одному признаку, делится на подгруппы по другому признаку.
Правила построения таблиц:
● таблица должна иметь небольшие размеры, чтобы ее было удобно читать и анализировать;
● название таблицы, заголовки подлежащего и сказуемого должны быть точными, краткими и ясными;
● в таблице должны быть точно обозначены единицы измерения, а также территория и период, к которым относятся приводимые данные;
● при отсутствии данных следует ставить знак тире, а при отсутствии сведений – многоточие или «нет сведений»;
● в таблице должны быть подсчитаны итоги;
● цифровой материал должен даваться с одинаковой степенью точности.
Таблица 6
Группировка магазинов в г. N по размеру товарооборота и по площади торгового зала
| Группы магазинов по размеру квартального товарооборота, млн. руб. | Площадь торгового зала, кв. м. | Количество розничных предприятий, единиц | Розничный товарооборот, млн. руб. |
| До 10 От 11 до 20 | До 30 30–50 50–100 свыше 100 до 30 30–50 50–100 свыше 100 | – | 1,2 14,2 9,3 28,4 – 12,8 90,1 132,6 |
Статистические графики. Ряды распределения для наглядности и удобства анализа можно изобразить графически. Основные виды графиков рядов распределения:
– полигон (служит для изображения дискретного вариационного ряда, а также для интервального вариационного ряда, для этого в качестве координат по оси абсцисс используют середины интервалов).

– гистограмма (столбиковая диаграмма, для построения которой на оси абсцисс откладывают отрезки, равные величине интервалов вариационного ряда. На отрезках строят прямоугольники, высота которых в принятом масштабе по оси ординат соответствует частотам или частостям). Гистограмма может быть преобразована в полигон распределения, если середины верхних сторон прямоугольников соединить отрезками прямых, при этом середины верхних сторон двух крайних прямоугольников соединить с осью абсцисс в точках, отстоящих в принятом масштабе на величину интервалов от середины первого и последнего интервалов;

Если интервалы неравные (размер дивидендов второго района из примера 2), то строят гистограмму плотностей распределения, так как плотность дает представление о заполненности каждого интервала:
Таблица 7
| Второй район | ||
| АО с размером дивидендов, руб. | Число АО, в % от их общего количества | Абсолютная плотность распределения |
| 0 – 250 250 – 600 600 – 800 800 – 1000 | 0,04 0,06 0,20 0,15 | |
| Итого |

– кумулята строится по накопленным частотам (частостям). Накопленные частоты (частости) определяют последовательным суммированием частот (частостей), они показывают, сколько единиц совокупности имеют значение признака не больше, чем рассматриваемое значение. При построении кумуляты интервального ряда нижней границе первого интервала соответствует нулевая частота (частость), верхней – вся частота (частость) первого интервала. Верхней границе второго интервала – сумма частот (частостей) первого и второго интервалов и т.д. Верхней границе последнего интервала – сумма накопленных частот (частостей) во всех интервалах, что соответствует общей численности изучаемой совокупности или 100%.
